
Relational databases represent an organization’s data in tables that use columns with different data types allowing them to store valid values. Developers and DBAs need to know and understand the appropriate data type for each column for better query performance.
This article will deal with the popular data types VARCHAR() and NVARCHAR(), their comparison, and performance reviews in SQL Server.
What is NVARCHAR in SQL?
The NVARCHAR data type is for the Unicode variable-length character data type. Here, N refers to National Language Character Set and is used to define the Unicode string. You can store both non-Unicode and Unicode characters (Japanese Kanji, Korean Hangul, etc.).
- N represents string size in bytes.
- It can store a maximum of 4000 Unicode and Non-Unicode characters.
- The VARCHAR data type takes 2 bytes per character. It takes 2 bytes storage if you do not specify any value for N.
The following query defines the VARCHAR data type with 100 bytes of data.
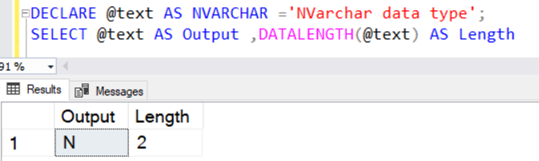
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
It returns the string length of 36 because NVARCHAR takes 2 bytes per character storage.
![NVARCHAR [ ( n | max ) ] in SQL](https://codingsight.com/wp-content/uploads/2021/07/image-245.png)
Similar to the VARCHAR data type, NVARCHAR also has a default value of 1 character (2 bytes) without specifying an explicit value for N.
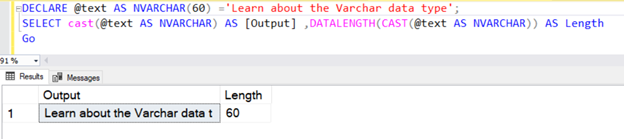
If we apply the NVARCHAR convert using the CAST or CONVERT function without any explicit value of N, the default value is 30 characters, i.e. 60 bytes.
Storing the Unicode and Non-Unicode Values in VARCHAR Data Type
Suppose we have a table that records customer feedback from an e-shopping portal. For this purpose, we have a SQL table with the following query.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
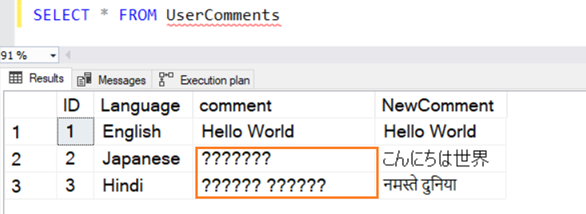
We insert several sample records in this table in English, Japanese, and Hindi. The data type for [Comment] is VARCHAR and [NewComment] is NVARCHAR().
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
The query executes successfully, and it gives the following rows while selecting a value from it. For the 2nd and 3rd row, it does not recognize data if it is not in English.
VARCHAR vs NVARCHAR Data Types: Performance Comparison
We should not mix the use of VARCHAR and NVARCHAR data types in the JOIN or WHERE predicates. It invalidates the existing indexes because SQL Server requires the same data types on both sides of JOIN. SQL Server tries to do the implicit conversion using the CONVERT_IMPLICIT() function in case of a mismatch.
SQL Server uses the data type precedence to determine which the target data type is. NVARCHAR has higher precedence than the VARCHAR data type. Therefore, during the data type conversion, SQL Server converts the existing VARCHAR values into NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Now, let’s execute two SELECT statements that retrieve records as per their data types.
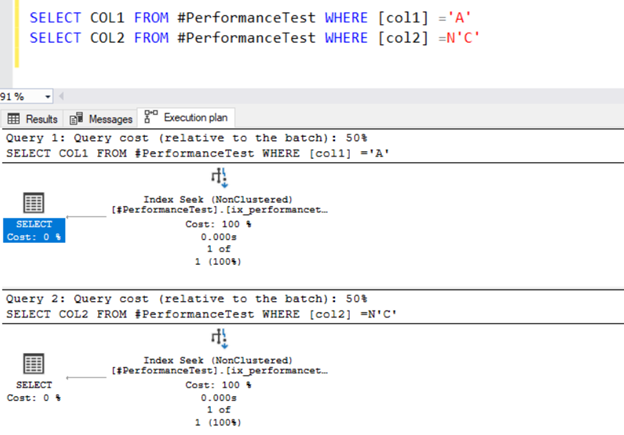
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Both queries use the Index seek operator and the indexes we defined earlier.
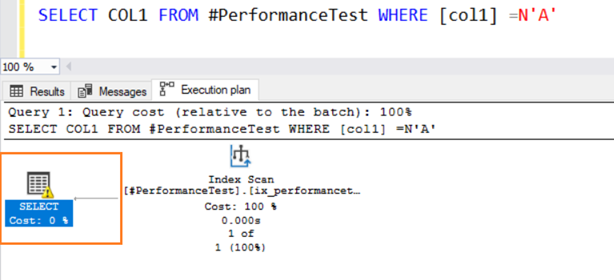
Now, we switch the data type values for comparison to the WHERE predicate. Column 1 has a VARCHAR data type, but we specify N’A’ to put it as NVARCHAR data type.
Similarly, col2 is the NVARCHAR data type, and we specify the value ‘C’ that refers to the VARCHAR data type.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'In the query actual execution plan, you get an Index scan, and the SELECT statement has a warning symbol.
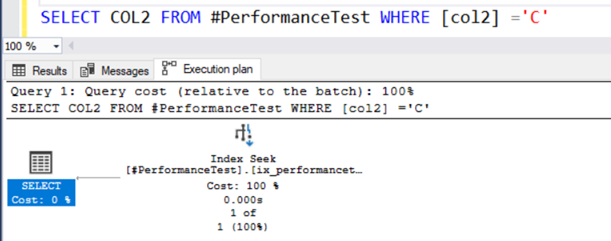
This query works fine because the NVARCHAR() data type can have both Unicode and non-Unicode values.
Now, the second query uses an Index scan and issues a warning symbol on the SELECT operator.
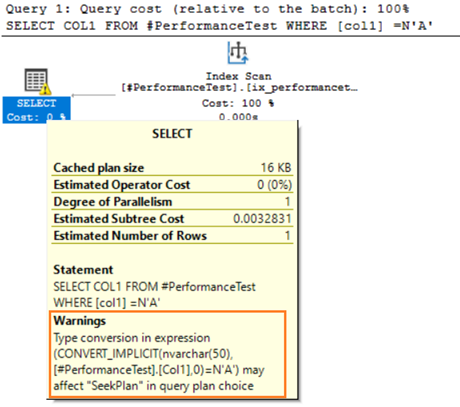
Hover the mouse over the SELECT statement that issues a warning about the implicit conversion. SQL Server could not use the existing index properly. It is due to the different data sorting algorithms for both VARCHAR and NVARCHAR data types.
If the table has millions of rows, SQL Server has to do additional work and convert data using data conversion implicitly. It might impact your query performance negatively. Therefore, you should avoid mixing and matching these data types in optimizing the queries.
Conclusion
You should review your data requirements while designing database tables and their columns data type appropriately. Usually, the VARCHAR data type servers most of your data requirements. However, if you need to store both Unicode and non-Unicode data types in a column, you can consider using the NVARCHAR. However, you should review its performance implication, storage size before making the final decision.
Tags: data types, nvarchar, varchar Last modified: June 12, 2023







