
Have you ever been asked how to create array in SQL Server? Or, you might be asked how to how to store values in an array in SQL Server.
Processing an array of values inside a procedure/ function is a common requirement. The question arises quite often, especially if you communicate with Oracle specialists. For instance, they may seek something like SQL declare array of strings. Oracle has arrays, but the problem is, there aren’t SQL array functions, as this RDBMS does not support the feature. .
Still, what if we need the SQL Server array of strings functionality? Fortunately, there are ways to resolve the issue. I am going to explain the most efficient alternatives to arrays in SQL Server.
Table Valued Parameters (TVP) Instead of Arrays
The SQL Server 2008 introduced a feature called table-valued parameters (TVP). It enabled users to combine values in a table and process them in table format. Thus, instead of an SQL array variable, that is unavailable, we can use table variables.
Stored procedures or functions could use this variable in join operations. It let them improve performance and avoid cursor-like operations item-by-item.
Although the table-based approach has been available for a long time, the SQL list of values as parameter is widely used for the following two reasons:
- Table-based variables are not supported by JDBC drivers. Java applications and services have to use comma-separated lists or structured formats like XML to transfer the list of values to the database server.
- Legacy code is still in production and needs to be maintained, and migration projects are too costly for execution.
To solve this problem, specialists apply several approaches. Some of them include writing a .NET CLR function or using XML. However, as the execution of .NET CLR functions might not be available in all environments, and XML is usually not the fastest solution, I will focus on the other two common approaches. They are the numbers table and common table expression (CTE) methods.
Split String into Array in SQL Server
The numbers table approach means that you must manually create a table containing enough rows so that the longest string you split will never exceed this number. It is not the same as SQL declare array, but it is functional for our purposes.
In this example, I am using 100.000 rows with a clustered index and compression on the generated column. This allows accelerating data retrieval.
IF EXISTS (
SELECT *
FROM sys.objects
WHERE object_id = OBJECT_ID(N'dbo.NumbersTest')
)
BEGIN
DROP TABLE NumbersTest;
END;
CREATE TABLE NumbersTest (Number INT NOT NULL);
DECLARE @RunDate datetime = GETDATE()
DECLARE @i INT = 1;
WHILE @i <= 100000
BEGIN
INSERT INTO dbo.NumbersTest(Number) VALUES (@i);
SELECT @i = @i + 1;
END;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.NumbersTest(Number) WITH (DATA_COMPRESSION = PAGE);
GONotice that index compression can only be used on Enterprise versions of SQL Server. Otherwise, you do not apply this option during the index creation.
With a newly created NumbersTest table, we can write a custom function performing an array splitting functionality:
CREATE FUNCTION dbo.Split_Numbers ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) )
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.NumbersTest
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter);On the other hand, if we use the CTE method, it will not require a numbers table. Instead, we will use a recursive CTE to extract each part of the string from the “remainder” of the previous part.
CREATE FUNCTION dbo.Split_CTE ( @List NVARCHAR(MAX),
@Delimiter NVARCHAR(255) )
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld, COALESCE(NULLIF(CHARINDEX(@Delimiter, @List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll
)
INSERT @Items SELECT [value]
FROM a
WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
ENDNow we need to test these two approaches. Let us start with a simple test case to check if they work properly:
DECLARE @Values NVARCHAR(MAX) =N'Value 1,Value 2,Value 3,Value 4,Value 5';
SELECT Item AS NumSplit FROM dbo.Split_Numbers (@Values, N',');
SELECT Item AS CTESplit FROM dbo.Split_CTE (@Values, N',');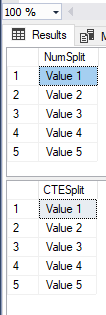
The Execution plan is below. As we see, functions use different methods to achieve the same result.
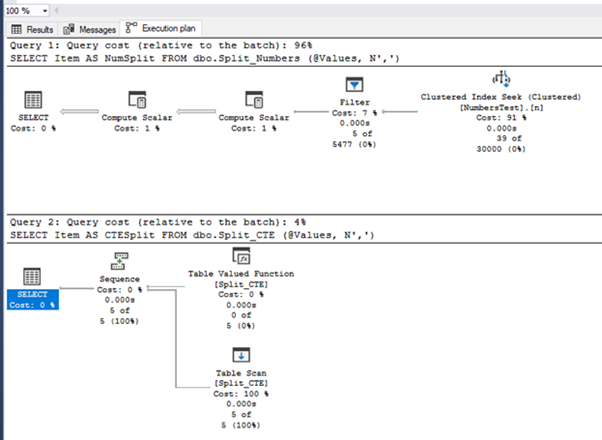
Since this is a very small dataset, performance cannot be compared. Let us do a test on a bigger set of values.
First, we need to create a table with test values. I will use the TestData table and populate it with different records, marking them by different types, depending on the category they are assigned to:
CREATE TABLE dbo.TestData
(
string_typ INT,
string_val NVARCHAR(MAX)
);
CREATE CLUSTERED INDEX st ON dbo.TestData(string_len);
CREATE TABLE #Temp(st NVARCHAR(MAX));
INSERT #Temp
SELECT N'a,va,val,value,value1,valu,va,value12,,valu,value123,value1234';
GO
INSERT dbo.TestData SELECT 1, st FROM #Temp;
GO 10000
INSERT dbo.TestData SELECT 2, REPLICATE(st,10) FROM #Temp;
GO 1000
INSERT dbo.TestData SELECT 3, REPLICATE(st,100) FROM #Temp;
GO 100
INSERT dbo.TestData SELECT 4, REPLICATE(st,1000) FROM #Temp;
GO 10
INSERT dbo.TestData SELECT 5, REPLICATE(st,10000) FROM #Temp;
GO
DROP TABLE #Temp;
GO
-- Cleanup up the trailing comma
UPDATE dbo.TestData
SET string_val = SUBSTRING(string_val, 1, LEN(string_val)-1) + 'x';With the test data available and split functions ready, we can try to test the case on bigger datasets to see how different functions perform (for each type of data, in seconds).
SELECT func.Item
FROM dbo.TestData AS tst
CROSS APPLY dbo.Split_CTE(tst.string_val, ',') AS func
WHERE tst.string_typ = 1; -- Values of string_typ are from 1-5
SELECT func.Item
FROM dbo.TestData AS tst
CROSS APPLY dbo.Split_Numbers(tst.string_val, ',') AS func
WHERE tst.string_typ = 1; -- Values of string_typ are from 1-5| STRING_TYP | Split_CTE function (s) | Split_Numbers function ( s) |
| 1 | 1 | 4 |
| 2 | 1 | 4 |
| 3 | 1 | 10 |
| 4 | 4 | 57 |
| 5 | 18 | 956 |
As the results show, with the strings getting larger, the advantage of the CTE method increases. It should be used over the table numbers approach.
Also, take into account that results depend on the hardware available on your server machine.
String Split Functions in MS SQL
The SQL Server 2016 provided a new built-in function STRING_SPLIT. This function changes the delimited string into a single-column table with two inputs, the string to be split into values and the separator character. It returns one column named value.
Have a look at the example below:
SELECT *
FROM string_split('Value 1,Value 2,Value 3,Value 4,Value 5',',' );The execution plan for this query is bellow:
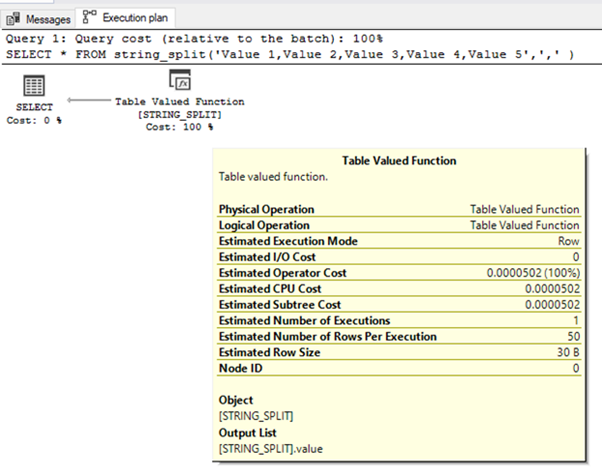
The Estimated Number of Rows Per Execution value is always 50. It does not depend on the number of string elements.
If we have the user-defined table-valued functions, the Estimated Number of Rows is 100.
As a table-valued function, it can also be used in FROM and WHERE expressions, and wherever a table expression is supported.
For example, we will use the AdventureWorks2019 database to demonstrate the usage of string_split in JOIN statements:
USE AdventureWorks2019;
DECLARE @Persons NVARCHAR(4000) = 'Miller,Margheim,Galvin,Duffy,Khanna';
SELECT PersonType, FirstName, MiddleName, LastName
FROM PErson.Person
WHERE LastName IN ( SELECT value FROM string_split(@Persons,',') );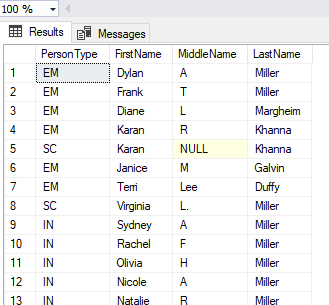
If you are working on a newer version of SQL Server, using the list of values with STRING_SPLIT function is optimal. It is optimized and easy to use, without the potential third-to-find bugs of some custom solutions.
However, there are some limitations:
- Single-character separator is the only type accepted. If you need more characters, you have to use a custom function.
- Single-output column – the output is always a single-column table without positioning the string element within the delimited string. It allows sorting only by the element name.
- String data type – you use this function to delimit a string of numbers (although all values in the output column are numbers, their data type is a string). When you join them to numeric columns in other tables, the data type conversion is required. If you forget to do explicit casts, you might get unexpected results.
If these limitations are acceptable to you, feel free to apply the function to get some alternative to SQL Server array of strings.
Conclusion
The issue like getting the SQL declare array option is not resolved directly in SQL Server. Still, modern methods of processing arrays allow doing the required tasks appropriately. If you consider how to apply the statement like SQL Server WHERE in array, there are other options. In my work, I would always suggest a built-in function rather than a user-defined one if they are similar from a performance point of view. It is always pre-deployed and available in all databases.
Besides, the software tools available for working with SQL servers help significantly. They provide the necessary values faster and can automate lots of tasks that often consume that time you might use better. For instance, dbForge SQL Complete offers a handy feature of getting the aggregates’ values for the selected data in the SSMS Results Grid (MIN, MAX, AVG, CONT, etc.).
Tags: sql, sql arrays, sql server Last modified: November 03, 2022







