The string data type is one of the most significant data types in any programming language. You can hardly write a useful program without it. Nevertheless, many developers do not know certain aspects of this type. Therefore, let’s consider these aspects.
Representation of strings in memory
In .Net, strings are located according to the BSTR (Basic string or binary string) rule. This method of string data representation is used in COM (the word ‘basic’ originates from the Visual Basic programming language in which it was initially used). As we know, PWSZ (Pointer to Wide-character String, Zero-terminated) is used in C/C++ for representation of strings. With such location in memory, a null-terminated is located in the end of a string. This terminator allows to determine the end of the string. The string length in PWSZ is limited only by a volume of free space.
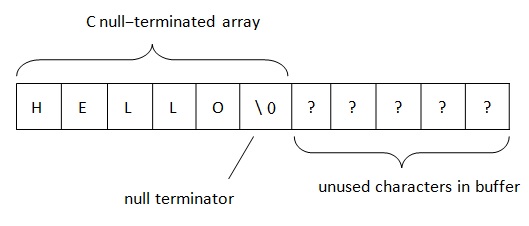
In BSTR, the situation is slightly different.
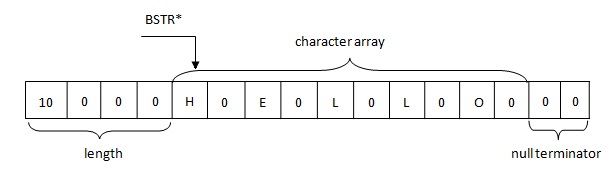
Basic aspects of the BSTR string representation in memory are the following:
- The string length is limited by a certain number. In PWSZ, the string length is limited by the availability of free memory.
- BSTR string always points at the first character in the buffer. PWSZ may point to any character in the buffer.
- In BSTR, similar to PWSZ, the null character is always located at the end. In BSTR, the null character is a valid character and may be found anywhere in the string.
- Because the null terminator is located at the end, BSTR is compatible with PWSZ, but not vice versa.
Therefore, strings in .NET are represented in memory according to the BSTR rule. The buffer contains a 4-byte string length followed by two-byte characters of a string in the UTF-16 format, that, in its turn, is followed by two null bytes (\u0000).
Using this implementation has many benefits: string length must not be recalculated as it is stored in the header, a string can contain null characters anywhere. And the most important thing is that the address of a string (pinned) can be easily passed over native code where WCHAR* is expected.
How much memory does a string object take?
I encountered articles stating that the string object size equals size=20 + (length/2)*4, but this formula is not quite correct.
To begin with, a string is a link type, so first four bytes contain SyncBlockIndex and the next four bytes contain the type pointer.
String size = 4 + 4 + …
As I stated above, the string length is stored in the buffer. It is an int type field, therefore we need to add another 4 bytes.
String size = 4 + 4 + 4 + …
To pass a string over to native code quickly (without copying), the null terminator is located at the end of each string that takes 2 bytes. Therefore,
String size = 4 + 4 + 4 + 2 + …
The only thing left is to recall that each character in a string is in the UTF-16 coding and also takes 2 bytes. Therefore:
String size = 4 + 4 + 4 + 2 + 2 * length = 14 + 2 * length
One more thing and we are done. The memory allocated by the memory manager in CLR is multiple of 4 bytes (4, 8, 12, 16, 20, 24, …). So, if the string length takes 34 bytes in total, 36 bytes will be allocated. We need to round our value to the nearest larger number that is multiple of four. For this, we need:
String size = 4 * ((14 + 2 * length + 3) / 4) (integer division)
The issue of versions: until .NET v4, there was an additional m_arrayLength field of the int type in the String class that took 4 bytes. This field is a real length of the buffer allocated for a string, including the null terminator, i.e. it is length + 1. In .NET 4.0, this field was dropped from the class. As a result, a string type object occupies 4 bytes less.
The size of an empty string without the m_arrayLength field (i.e. in .Net 4.0 and higher) equals = 4 + 4 + 4 + 2 = 14 bytes, and with this field (i.e. lower than .Net 4.0), its size equals = 4 + 4 + 4 + 4 + 2 = 18 bytes. If we round of 4 bytes, the size will be 16 and 20 bytes, correspondingly.
String Aspects
So, we considered the representation of strings and the size they take in memory. Now, let’s talk about their peculiarities.
Basic aspects of strings in .NET are the following:
- Strings are reference types.
- Strings are immutable. Once created, a string cannot be modified (by fair means). Each call of the method of this class returns a new string, while the previous string becomes a prey for the garbage collector.
- Strings redefine the Object.Equals method. As a result, the method compares character values in strings, not link values.
Let’s consider each point in detail.
Strings are reference types
Strings are real reference types. That is, they are always located in heap. Many of us confuse them with value types, since thy behave in the same way. For instance, they are immutable and their comparison is performed by value, not by references, but we must bear in mind that it is a reference type.
Strings are immutable
- Strings are immutable for a purpose. The string immutability has a number of benefits:
- String type is thread-safe, since not a single thread can modify the content of a string.
- Use of immutable strings leads to decrease of memory load, since there is no need to store 2 instances of the same string. As a result, less memory is spent, and comparison is performed faster, since only references are compared. In .NET, this mechanism is called string interning (string pool). We will talk about it a bit later.
- When passing an immutable parameter to a method, we can stop worrying that it will be modified (if it wasn’t passed as ref or out, of course).
Data structures can be divided into two types: ephemeral and persistent. Ephemeral data structures store only their last versions. Persistent data structures save all their previous versions during modification. The latter are, in fact, immutable, since their operations do not modify the structure on site. Instead, they return a new structure that is based on the previous one.
Given the fact that strings are immutable, they could be persistent, but they are not. Strings are ephemeral in .Net.
For comparison, let’s take Java strings. They are immutable, like in .NET, but additionally they are persistent. The implementation of the String class in Java looks as follows:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
In addition to 8 bytes in the object’s header, including a reference to the type and a reference to a synchronization object, strings contain the following fields:
- A reference to a char array;
- An index of the first character of the string in the char array (offset from the beginning)
- The number of characters in the string;
- The hash code calculated after first calling the HashCode() method.
Strings in Java take more memory than in .NET, since they contain additional fields allowing them to be persistent. Owing to persistence, the execution of the String.substring() method in Java takes O(1), since it does not require string copying as in .NET, where execution of this method takes O(n).
Implementation of String.substring() method in Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
}
However, if a source string is large enough and the cutout substring is of several characters long, the entire array of characters of the initial string will be pending in memory till there is a reference to the substring. Or, if you serialize the received substring by standard means and pass it over the network, the entire original array will be serialized and the number of bytes that is passed over the network will be large. Therefore, instead of the code
s = ss.substring(3)
the following code can be used:
s = new String(ss.substring(3)),
This code will not store the reference to the array of characters of the source string. Instead, it will copy only the actually used part of the array. By the way, if we call this constructor on a string which length equals the length of the array of characters, copying will not take place. Instead, the reference to the original array will be used.
As it turned out, the implementation of the string type has been changed in the last version of Java. Now, there are no offset and length fields in the class. The new hash32 (with different hashing algorithm) has been introduced instead. This means that strings are not persistent anymore. Now, the String.substring method will create a new string each time.
String redefine Onbject.Equals
The string class redefines the Object.Equals method. As a result, comparison takes place, but not by reference, but by value. I suppose that developers are grateful to creators of the String class for redefining the == operator, since code that uses == for string comparison looks more profound than the method call.
if (s1 == s2)
Compared to
if (s1.Equals(s2))
By the way, in Java, the == operator compares by reference. If you need to compare strings by character, we need to use the string.equals() method.
String Interning
Finally, let’s consider string interning. Let’s take a look at a simple example – a code that reverses a string.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
}
Obviously, this code cannot be compiled. The compiler will throw errors for these strings, since we try to modify the content of the string. Any method of the String class returns new instance of the string, instead of its content modification.
The string can be modified, but we will need to use the unsafe code. Let’s consider the following example:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
After execution of this code, elbatummi era sgnirtS will be written into the string, as expected. Mutability of strings leads to a fancy case related to string interning.
String interning is a mechanism where similar literals are represented in memory as a single object.
In short, the point of string interning is the following: there is a single hashed internal table within a process (not within an application domain), wherein strings are its keys, and values are references to them. During JIT compilation, literal strings are placed into a table sequentially (each string in a table can be found only once). During execution, references to literal strings are assigned from this table. During execution, we can place a string into internal table with the String.Intern method. Also, we can check the availability of a string in internal table using the String.IsInterned method.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Note, that only string literals are interned by default. Since the hashed internal table is used for interning implementation, the search against this table is performed during JIT compilation. This process takes some time. So, if all strings are interned, it will reduce optimization to zero. During compilation into IL code, the compiler concatenates all literal strings, since there is no need in storing them in parts. Therefore, the second equality returns true.
Now, let’s return to our case. Consider the following code:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable");
It seems that everything is quite obvious and the code should return Strings are immutable. However, it doesn’t! The code returns elbatummi era sgnirtS. It happens exactly because of interning. When we modify strings, we modify its content, and since it is literal, it is interned and represented by a single instance of the string.
We can abandon string interning if we apply the CompilationRelaxationsAttribute attribute to the assembly. This attribute controls the accuracy of the code that is created by JIT compiler of the CLR environment. The constructor of this attribute accepts the CompilationRelaxations enumeration, which currently includes only CompilationRelaxations.NoStringInterning. As a result, the assembly is marked as the one that does not require interning.
By the way, this attribute is not processed in .NET Framework v1.0. That’s why, it was impossible to disable interning. As from version 2, the mscorlib assembly is marked with this attribute. So, it turns out that strings in .NET can be modified with the unsafe code.
What if we forget about unsafe?
As it happens, we can modify string content without the unsafe code. Instead, we can use the reflection mechanism. This trick was successful in .NET till version 2.0. Afterwards, developers of the String class deprived us of this opportunity. In .NET 2.0, the String class has two internal methods: SetChar for bounds checking and InternalSetCharNoBoundsCheck that does not make bounds checking. These methods set the specified character by a certain index. The implementation of the methods looks in the following way:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
Therefore, we can modify the string content without unsafe code with the help of the following code:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
As expected, the code returns elbatummi era sgnirtS.
The issue of versions: in different versions of .NET Framework, string.Empty can be integrated or not. Let’s consider the following code:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal");
In .NET Framework 1.0, .NET Framework 1.1 and .NET Framework 3.5 with the 1 (SP1) service pack, str1 and str2 are not equal. Currently, string.Empty is not interned.
Aspects of Performance
There is one negative side effect of interning. The thing is that the reference to a String interned object stored by CLR can be saved even after the end of application work and even after the end of application domain work. Therefore, it’s better to omit using big literal strings. If it is still required, interning must be disabled by applying the CompilationRelaxations attribute to assembly.
Tags: .net, .net framework, c# Last modified: September 23, 2021



