According to Wikipedia, the bulk insert is a process or method provided by a database management system to load multiple rows of data into a database table. If we adjust this explanation to the BULK INSERT statement, the bulk insert allows importing external data files into SQL Server.
Assume that our organization has a CSV file of 1.500.000 rows, and we want to import it to a particular table in SQL Server to use the BULK INSERT statement in SQL Server. We can find several methods to handle this task. It could be using BCP (bulk copy program), SQL Server Import and Export Wizard, or SQL Server Integration Service package. However, the BULK INSERT statement is much faster and potent. Another advantage is that it offers several parameters helping to determine the bulk insert process settings.
Let’s start with a basic sample. Then we will go through more sophisticated scenarios.
Preparation
First of all, we need a sample CSV file. We download a sample CSV file from the E for Excel website (a collection of sampled CSV files with a different row number). Here, we are going to use 1.500.000 Sales Records.
Download a zip file, unzip it to get a CSV file, and place it in your local drive.
Import CSV File to SQL Server table
We import our CSV file into the destination table in the simplest form. I placed my sample CSV file on the C: drive. Now we create a table to import the CSV file data to it:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
The following BULK INSERT statement imports the CSV file to the Sales table:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
You’ve probably noted the specific parameters of the above bulk insert statement. Let’s clarify them:
- FIRSTROW specifies the starting point of the insert statement. In the below example, we want to skip column headers, so we set this parameter to 2.

- FIELDTERMINATOR defines the character which separates fields from each other. SQL Server detects each field this way.
- ROWTERMINATOR does not much differ from FIELDTERMINATOR. It defines the separation character of rows.
In the sample CSV file, FIELDTERMINATOR is very clear, and it is a comma (,). To detect this parameter, open the CSV file in Notepad++ and navigate to View -> Show Symbol -> Show All Charters. The CRLF characters are at the end of each field.
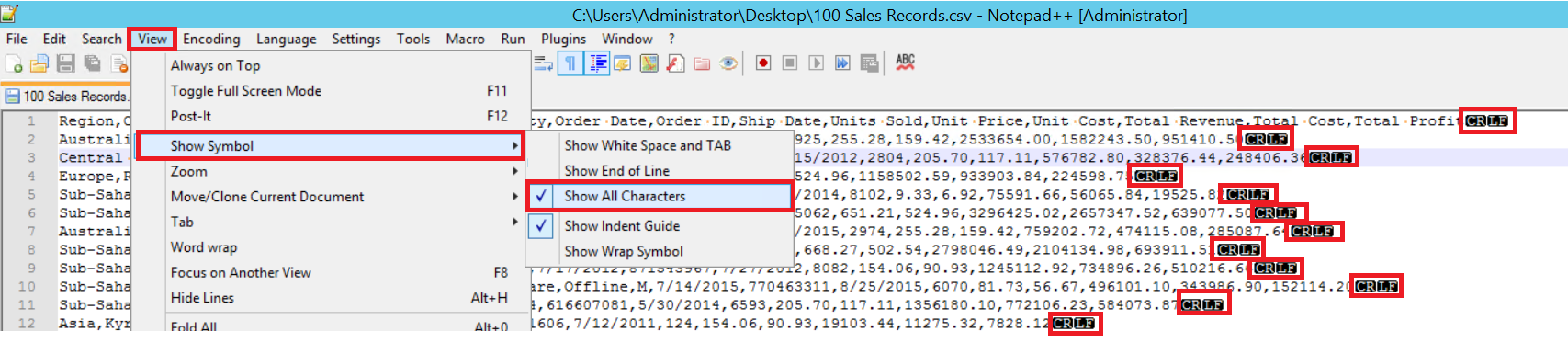
CR = Carriage Return and LF = Line Feed. They are used to mark a line break in a text file. The indicator is “\n” in the bulk insert statement.
Another way to import a CSV file to a table with bulk insert is by using the FORMAT parameter. Note that this parameter is available only in SQL Server 2017 and later versions.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
That was the simplest scenario where the destination table and CSV file have an equal number of columns. However, the case when the destination table has more columns, then the CSV file is typical. Let’s consider it.
We add a primary key to the Sales table to break the equality column mappings. We create the Sales table with a primary key and import the CSV file through the bulk insert command.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
But it produces an error:
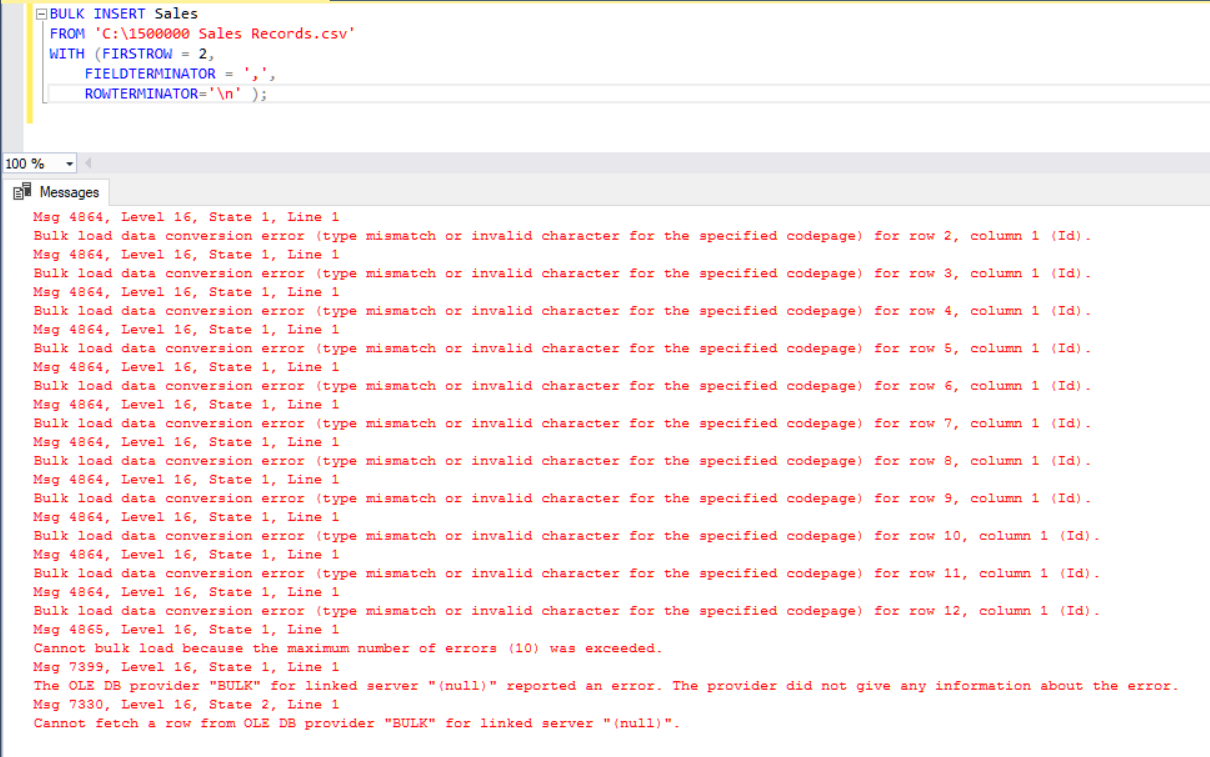
To overcome the error, we create a view of the Sales table with mapping columns to the CSV file. Then we import the CSV data over this view to the Sales table:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Separate and load a large CSV file into a small batch size
SQL Server acquires a lock to the destination table during the bulk insert operation. By default, if you do not set the BATCHSIZE parameter, SQL Server opens a transaction and inserts the whole CSV data into it. With this parameter, SQL Server divides the CSV data according to the parameter value.
Let’s divide the whole CSV data into several sets of 300.000 rows each.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
The data will be imported five times in parts.
- If your bulk insert statement does not include the BATCHSIZE parameter, an error will occur, and the SQL Server will roll back the whole bulk insert process.
- With this parameter set to bulk insert statement, SQL Server rolls back only the part where the error occurred.
There is no optimum or best value for this parameter because its value can change according to your database system requirements.
Set the behavior in case of errors
If an error occurs in some bulk copy scenarios, we may either cancel the bulk copy process or keep it going. The MAXERRORS parameter allows us to specify the maximum number of errors. If the bulk insert process reaches this max error value, it cancels the bulk import operation and rolls back. The default value for this parameter is 10.
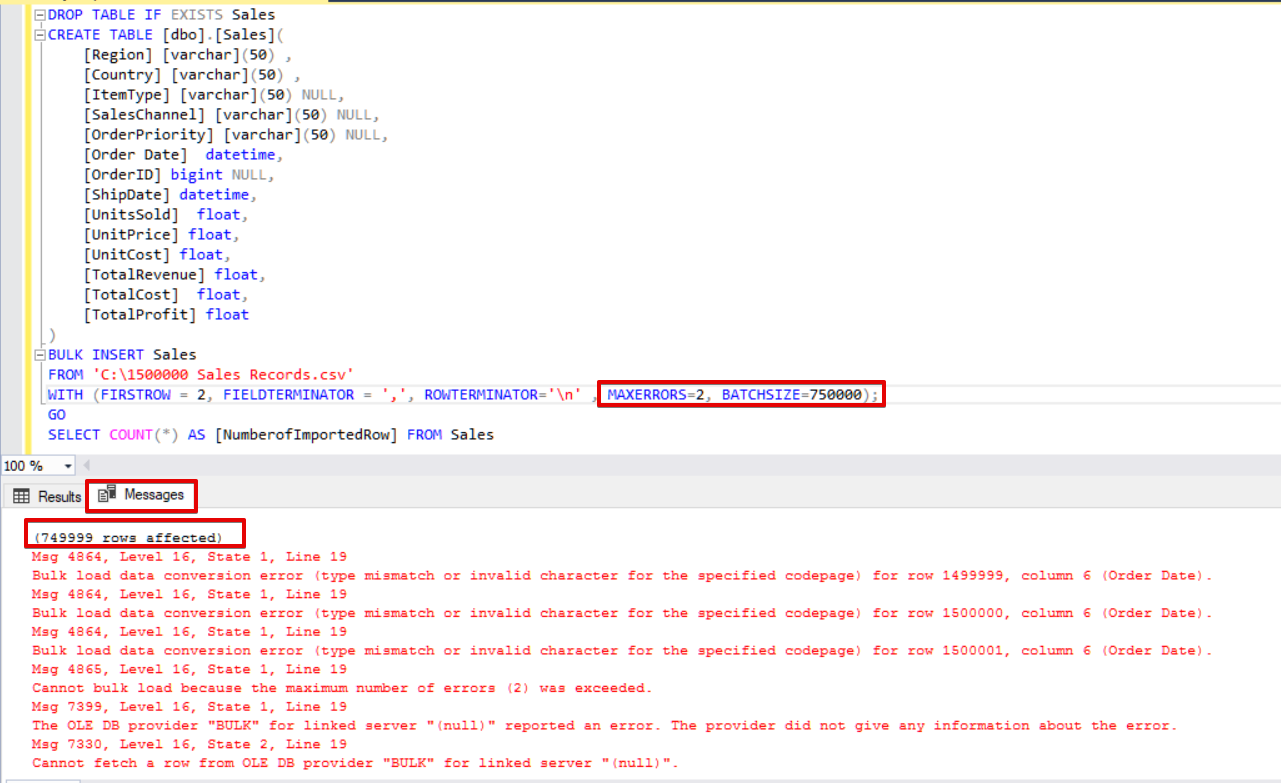
For instance, we have corrupted data types in 3 rows of the CSV file. The MAXERRORS parameter is set to 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
The whole bulk insert operation will be canceled because there are more errors than the MAXERRORS parameter value.
If we change the MAXERRORS parameter to 4, the bulk insert statement will skip these rows with errors and insert correct data structured rows. The bulk insert process will be complete.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
If we use both BATCHSIZE and MAXERRORS simultaneously, the bulk copy process will not cancel the whole insert operation. It will only cancel the divided part.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
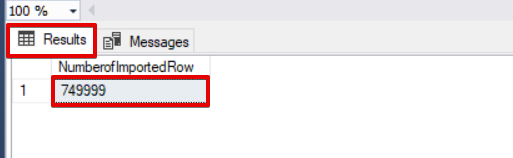
Have a look at the image below that shows the script execution result:
Other options of the bulk insert process
FIRE_TRIGGERS – enable triggers in the destination table during the bulk insert operation
By default, during the bulk insert process, the insert triggers specified in the target table are not fired. Still, in some situations, we may want to enable them.
The solution is using the FIRE_TRIGGERS option in bulk insert statements. But please note that it can affect and decrease the bulk insert operation performance. It is because trigger/triggers can make separate operations in the database.
At first, we don’t set the FIRE_TRIGGERS parameter, and the bulk insert process will not fire the insert trigger. See the below T-SQL script:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogWhen this script executes, the insert trigger won’t fire because the FIRE_TRIGGERS option is not set.
Now, let’s add the FIRE_TRIGGERS option to the bulk insert statement:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 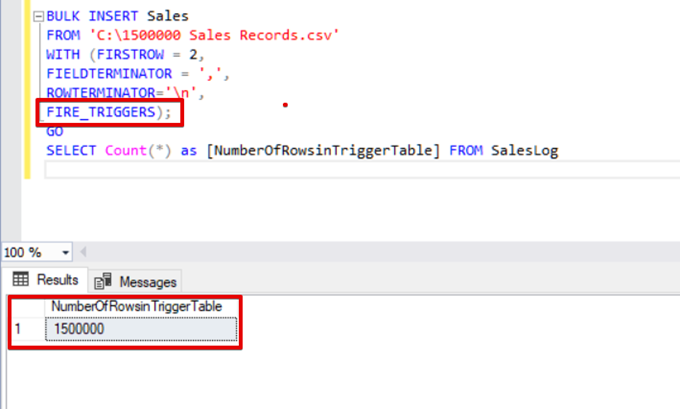
CHECK_CONSTRAINTS – enable a check constraint during the bulk insert operation
Check constraints allow us to enforce data integrity in SQL Server tables. The purpose of the constraint is to check inserted, updated, or deleted values according to their syntax regulation. Such as, the NOT NULL constraint provides that the NULL value cannot modify a specified column.
Here, we focus on constraints and bulk insert interactions. By default, during the bulk insert process, any check and foreign key constraints are ignored. But there are some exceptions.
According to Microsoft, “UNIQUE and PRIMARY KEY constraints are always enforced. When importing into a character column for which the NOT NULL constraint is defined, BULK INSERT inserts a blank string when there is no value in the text file.”
In the following T-SQL script, we add a check constraint to the OrderDate column, which controls the order date greater than 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'As a result, the bulk insert process skips the check constraint control. However, SQL Server indicates check constraint as not-trusted:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'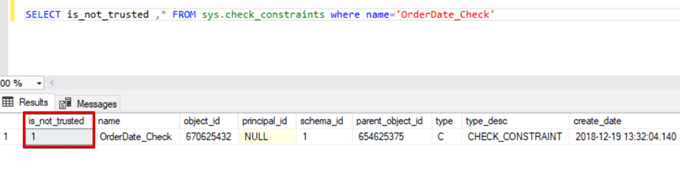
This value indicates that somebody inserted or updated some data to this column by skipping the check constraint. At the same time, this column may contain inconsistent data regarding that constraint.
Try to execute the bulk insert statement with the CHECK_CONSTRAINTS option. The result is straightforward: check constraint returns an error because of improper data.
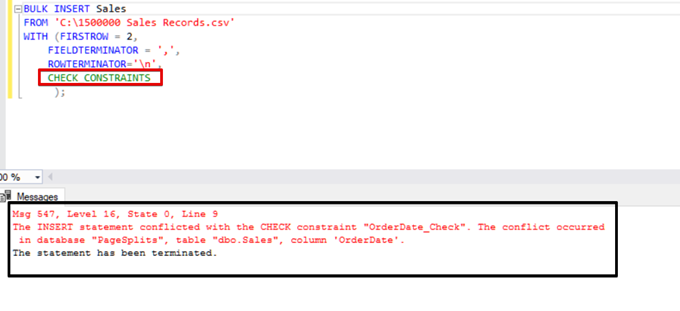
TABLOCK – increase performance in multiple bulk inserts into one destination table
The primary purpose of the locking mechanism in SQL Server is to protect and ensure data integrity. In the Main concept of the SQL Server locking article, you can find details about the lock mechanism.
We will focus on bulk insert process locking details.
If you run the bulk insert statement without the TABLELOCK option, it acquires the lock of rows or tables according to lock hierarchy. But in some cases, we may want to execute multiple bulk insert processes against one destination table and thus decrease the operation time.
First, we execute two bulk insert statements simultaneously and analyze the behavior of the locking mechanism. Open two query windows in SQL Server Management Studio and run the following bulk insert statements simultaneously.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
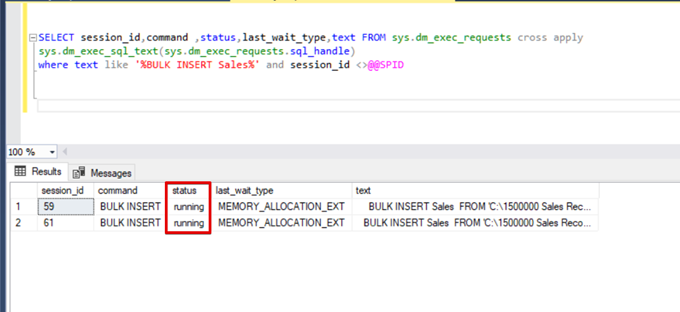
);Execute the following DMV (Dynamic Management View) query – it helps to monitor the bulk insert process status:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID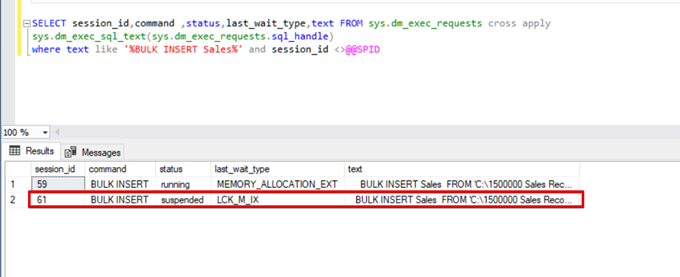
As you can see in the above image, session 61, the bulk insert process status is suspended due to locking. If we verify the problem, session 59 locks the bulk insert destination table. Then, session 61 waits for releasing this lock to continue the bulk insert process.
Now, we add the TABLOCK option to the bulk insert statements and execute the queries.
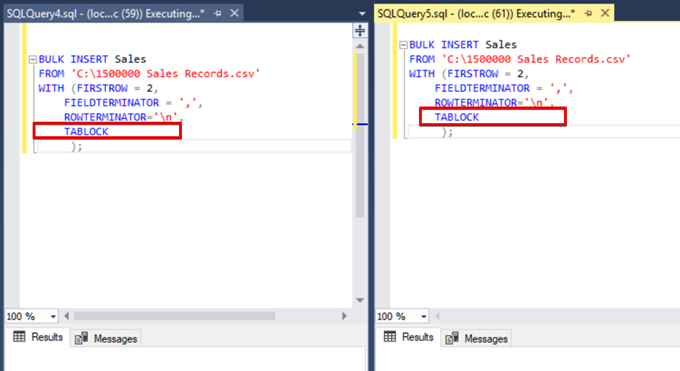
When we execute the DMV monitoring query again, we cannot see any suspended bulk insert process because SQL Server uses a particular lock type called bulk update lock (BU). This lock type allows processing multiple bulk insert operations against the same table simultaneously. This option also decreases the total time of the bulk insert process.
When we execute the following query during the bulk insert process, we can monitor the locking details and lock types:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()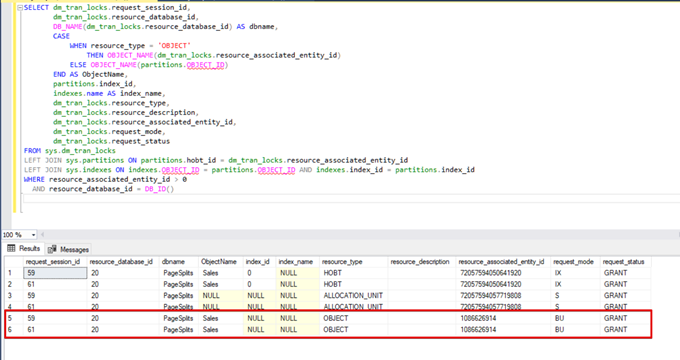
Conclusion
The current article explored all details of bulk insert operation in SQL Server. Notably, we mentioned the BULK INSERT command and its settings and options. Also, we analyzed various scenarios close to real-life problems.
Useful tool:
dbForge Data Pump – an SSMS add-in for filling SQL databases with external source data and migrating data between systems.
Tags: sql, sql server, t-sql, t-sql statements Last modified: July 10, 2023




