
SQL Server UPDATE from SELECT is not your usual cup of tea on T-SQL. So, it’s time to level up your UPDATE skills. But with this, you have a new foe: code complexity.
Crushing code complexity is a source of many headaches. Reading rows using a complex query is one thing. Updating rows is another. You always need to hit the bullseye. Only the intended rows to update. Nothing more. So, that makes SQL Server UPDATE from SELECT even scarier. And to add more to your pain, you can’t be too careful. Adding unnecessary conditions to hit the bullseye can make your query slower.
It’s like boxing with an octopus. How can you land a blow to it when 8 tentacles can block your punch? And yet, how can you avoid or block 8 tentacles with 2 hands without dropping out unconscious? It’s like a no-win scenario.
Or is it?
Ease up, my fellow SQL developer. This is not your Kobayashi Maru. You can break complex things down into simpler ones, like a giant supercluster down to an atom.
So, in this article, we’ll make SQL Server UPDATE from SELECT second nature to you. And with this, we will use SQL Server 2022 and dbForge Studio for SQL Server 6.4.7.
Here’s how the battle will proceed:
- Why SQL Server UPDATE From SELECT?
- Various Techniques to UPDATE From SELECT in SQL Server
- Prepare the Data and Cover All Your Bases
- UPDATE From SELECT Using a CTE
- UPDATE From SELECT Using a Derived Table
- UPDATE From SELECT Using MERGE
- UPDATE From SELECT Using a Subquery
- SQL Server UPDATE From SELECT Techniques: Which One is the Fastest?
So, buckle up, and let’s dive in.
Why SQL Server UPDATE From SELECT
Consider the simplest and most basic UPDATE statement possible:
UPDATE table
SET column1 = value1, column2 = value2, columnN = valueN
WHERE keycolumn = keyvalue; That’s how you do an UPDATE using plain values like numbers, text, dates, and more. So, if you have edited a row in a table from your app, this is the UPDATE you will do.
But consider these scenarios:
- Updating the order status in the “Orders” table based on the payment status in the “Payments” table. The UPDATE statement would retrieve payment information and update the corresponding order status.
- Merging customer information from different sources into a master customer table. The UPDATE statement would apply business rules for consolidation. Then, update the master customer table accordingly.
- Updating the product prices based on defined pricing strategy. The UPDATE statement would calculate the new prices based on the defined rules in a table. Then, update the product records accordingly.
Using plain values to update rows in these scenarios will be difficult if not impossible. So, we use UPDATE from SELECT. Because plain values are not always practical to achieve a more complex scenario. You will use some join types like INNER JOIN or even self-join in certain use cases.
There are different ways to UPDATE a table with a SELECT statement. We will consider each of them in this article. And you will get examples for each method. You will also know how to pick the right method that will perform best in your specific requirements.
Note, though, that you can use UPDATE without a SELECT. Just a simple join. Check out this UPDATE with JOIN article for more information. In the same article also comes some tips to do the update safely. The same tips also apply to this article.
For this article, the scope is using UPDATE with a SELECT statement within.
Various Techniques to UPDATE From SELECT in SQL Server
The techniques used here involve the use of the following:
- a common table expression (CTE),
- a derived table,
- a MERGE,
- and a subquery.
But before we proceed, we need some data.
Prepare the Data and Cover All Your Bases
The scenario we will use is to update a sales subtotal based on the order details. And with this, we are going to borrow some rows in 2 AdventureWorks tables. And these are the SalesOrderHeader and SalesOrderDetails tables.
First, let’s create the 2 tables using a SELECT INTO statement:
-- Let's dump the data to this test database
USE TestDatabase
GO
-- create the sales header table using 2011 data
SELECT * INTO dbo.SalesOrderHeader FROM AdventureWorks.Sales.SalesOrderHeader
WHERE year(OrderDate) = 2011;
-- create the sales order details table based on data from the header
SELECT * INTO dbo.SalesOrderDetail FROM AdventureWorks.Sales.SalesOrderDetail
WHERE SalesOrderID IN (SELECT SalesOrderID FROM dbo.SalesOrderHeader) Then, let’s add some indexes that we need in this exercise:
ALTER TABLE dbo.SalesOrderHeader
ADD CONSTRAINT PK_SalesOrderHeader_SalesOrderID PRIMARY KEY CLUSTERED (SalesOrderID);
ALTER TABLE dbo.SalesOrderDetail
add CONSTRAINT PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE INDEX IX_SalesOrderDetail_SalesOrderID ON SalesOrderDetail (SalesOrderID)
INCLUDE (LineTotal);
CREATE INDEX IX_SalesOrderHeader_OrderDate ON SalesOrderHeader (OrderDate)
INCLUDE (SubTotal); To make bulletproof updates, you need to have a fallback in case you updated the wrong records. You can also use this to reset the table again to use a different UPDATE technique. First, we need to dump the sales subtotal together with it’s key in another table. We used a temporary table for this purpose.
-- Dump the subtotals to a temporary table
SELECT SalesOrderID, SubTotal
INTO #tmpSalesSubTotals
FROM dbo.SalesOrderHeader
GO Then, below is the UPDATE with JOIN statement that will return the values to their original state:
UPDATE soh
SET SubTotal = sst.SubTotal
FROM dbo.SalesOrderHeader soh
INNER JOIN #tmpSalesSubTotals sst ON soh.SalesOrderID = sst.SalesOrderID
GO We’re going to use this before running each technique later.
Another thing you need is to view the records you need to UPDATE. So, here’s the query for that:
;WITH cteSalesDetail AS
(
SELECT
sod.SalesOrderID
,SUM(sod.LineTotal) AS ProductOrderTotal
FROM dbo.SalesOrderDetail sod
GROUP BY sod.SalesOrderID
)
SELECT
s.SalesOrderID
,s.SubTotal
, c.ProductOrderTotal
FROM dbo.SalesOrderHeader s
INNER JOIN cteSalesDetail c ON s.SalesOrderID = c.SalesOrderID
WHERE s.SubTotal <> c.ProductOrderTotal
AND (s.OrderDate BETWEEN '06/01/2011' AND '12/31/2011'); For clarity, we use a common table expression (CTE). This will separate the sum of the sales order details from the sales header subtotal. The CTE sums the product sales order based on the SalesOrderID. And then, we join this CTE to the SalesOrderHeader to compare the subtotal to the sum of the detailed orders. Any differences in row values are the rows we need to update. And we will only cover 6 months of data in 2011 (June to December).
And here’s the result set of that query.
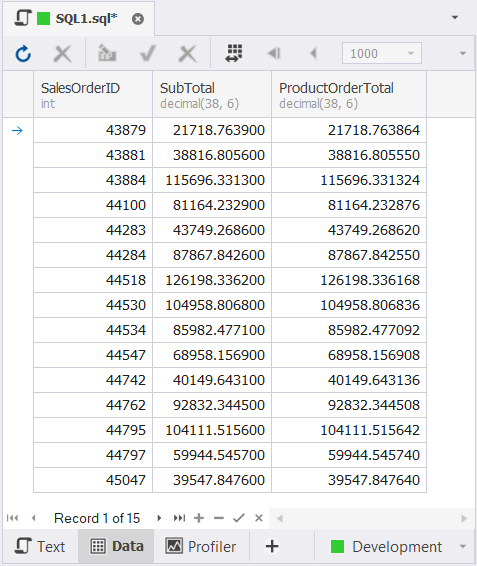
Note that we need to update 15 rows only. The differences occur on the decimal part of the figures. We want them to be exact. You will see 15 rows in execution plans later.
So, I think we covered all the bases. Let’s start with the first technique.
UPDATE From SELECT Using a CTE
The UPDATE statement is not so different from the CTE query earlier. Here it is:
;WITH cteSalesDetail AS
(
SELECT
SalesOrderID
,SUM(LineTotal) AS ProductOrderTotal
FROM dbo.SalesOrderDetail
GROUP BY SalesOrderID
)
UPDATE s
SET SubTotal = c.ProductOrderTotal
FROM dbo.SalesOrderHeader s
INNER JOIN cteSalesDetail c ON s.SalesOrderID = c.SalesOrderID
WHERE s.SubTotal <> c.ProductOrderTotal
AND (s.OrderDate BETWEEN '06/01/2011' AND '12/31/2011') We only transformed the SELECT from a CTE to an UPDATE. The SELECT part is the same as the CTE earlier. And the UPDATE part updates the subtotal with the order totals from the CTE. Compare the WHERE clause here from the SELECT from CTE query earlier. It’s obvious not to change the condition to avoid updating the wrong records. And the indexes we created earlier cover the columns in the INNER JOIN and the WHERE clause. This is very important in query optimization.
Let’s try another way to update the rows.
UPDATE From SELECT Using a Derived Table
A derived table is a result of a SELECT statement that we treat as a table. So, we join this result and use it to update the rows. Here’s the UPDATE variant using a derived table:
UPDATE s
SET SubTotal = c.ProductOrderTotal
FROM dbo.SalesOrderHeader s
INNER JOIN
(
SELECT
SalesOrderID
,SUM(LineTotal) AS ProductOrderTotal
FROM dbo.SalesOrderDetail
GROUP BY SalesOrderID
) c ON s.SalesOrderID = c.SalesOrderID
WHERE s.SubTotal <> c.ProductOrderTotal
AND (s.OrderDate BETWEEN '06/01/2011' AND '12/31/2011'); See the derived table enclosed in parentheses. It’s the same as the CTE earlier. But instead of creating a CTE, we directly joined the SELECT query as a derived table. The rest of the conditions are the same.
Note that if you want to run this UPDATE statement, you need to reset the subtotal values first. To do that, use the UPDATE statement in the Prepare the Data and Cover All Your Bases section.
Let’s try another way to UPDATE from SELECT.
UPDATE From SELECT Using MERGE
You can use the MERGE statement for UPDATE only. Though MERGE is useful for syncing 2 tables instead of using 3 commands (INSERT, UPDATE, DELETE). So, it’s not just for UPDATE.
The syntax will be different from the previous examples but the results are the same.
MERGE dbo.SalesOrderHeader AS target
USING (
SELECT SalesOrderID, SUM(LineTotal) AS TotalLineAmount
FROM dbo.SalesOrderDetail
GROUP BY SalesOrderID
) AS source (SalesOrderID, TotalLineAmount)
ON (target.SalesOrderID = source.SalesOrderID)
WHEN MATCHED AND target.SubTotal <> source.TotalLineAmount
AND (target.OrderDate BETWEEN '06/01/2011' AND '12/31/2011') THEN
UPDATE SET target.SubTotal = source.TotalLineAmount; With MERGE, we define a source and a target. The source is the same as the CTE and derived table earlier. While the target is the SalesOrderHeader table where the subtotal column exists. And the WHEN MATCHED clause is the same as our WHERE clause from the 2 previous examples. Though we used different table aliases.
Again, you need to reset the subtotal values again before running this MERGE command. Or you update nothing.
Let’s try the final technique.
UPDATE From SELECT Using a Subquery
We sometimes refer to a subquery as a sub-SELECT or a query within a query. It’s different from a derived table because it needs to output 1 value. See the UPDATE variant below:
UPDATE dbo.SalesOrderHeader
SET SubTotal = (
SELECT SUM(LineTotal)
FROM dbo.SalesOrderDetail
WHERE SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID
GROUP BY SalesOrderID
)
WHERE SubTotal <> (
SELECT SUM(LineTotal)
FROM dbo.SalesOrderDetail
WHERE SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID
GROUP BY SalesOrderID
) AND (SalesOrderHeader.OrderDate BETWEEN '06/01/2011' AND '12/31/2011'); You know, I don’t like the query above because of repeated code. But this is to let you know that this technique is a possibility. The subquery in this case outputs the sum of the order details. And the result becomes the new value of the subtotal for each SalesOrderID. The ugly part is the comparison of the same subquery to the current subtotal.
Note that for this requirement, the subquery repeats across the entire UPDATE statement. It can be different with another requirement. So, remember that. And don’t hate the subquery because of this.
And again, before running this, run the UPDATE to reset the subtotal values.
After knowing these 4 techniques, you may ask: “Which is the fastest among the 4?”
SQL Server UPDATE From SELECT Techniques: Which One is the Fastest?
It’s only natural to ask which is the best and fastest technique. Besides, all 4 methods result in the same updated rows.
But note that in query optimization, one method is not always faster than the other. Requirements vary including your database design. So, a CTE is not always faster than a subquery and vice versa. You need to inspect execution plans, I/O statistics, and other information.
We don’t compare using elapsed time or execution time. Why not? Other factors affect elapsed time. Examples are processes the operating system does when your query runs. Queries running in the background are culprits too. So, a rather simple query can wait longer to run because of some locking or blocking process.
But in our example, let’s see by comparing their execution plans and other factors. We will use the Query Profiler of dbForge Studio for SQL Server. But you can use SQL Server Management Studio to inspect the same information.
Comparing Logical Reads and Other Information
First, let’s inspect the logical reads and other stats used by each technique. See below:
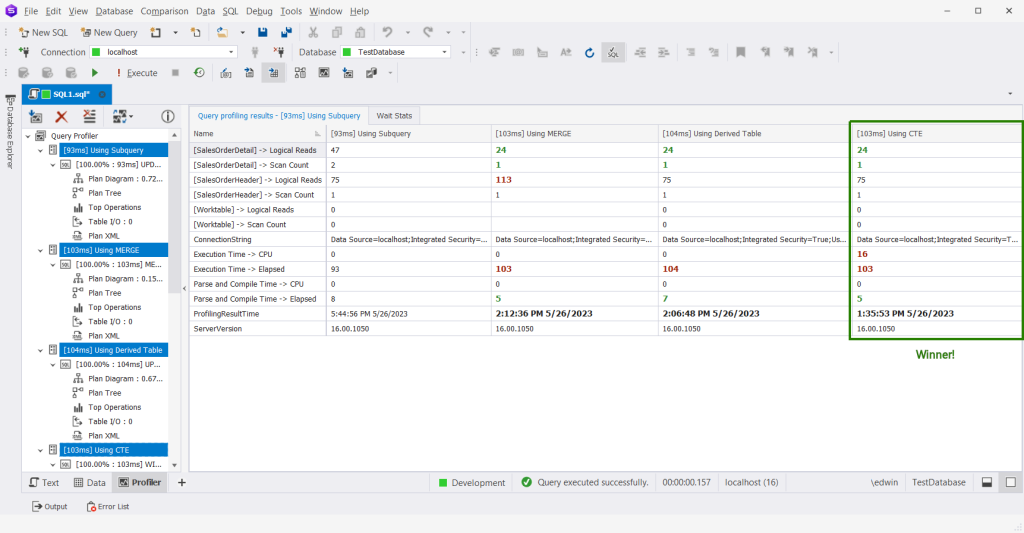
These are not some confusing numbers. Let me explain:
- First, the logical reads. The lower the number the better. And from the 4 methods, using MERGE is the worst. Check out the logical reads for both SalesOrderHeader and SalesOrderDetail. Using MERGE results in 24 and 113 logical reads respectively. The winners for logical reads are the CTE and the derived table. See the green numbers on them.
- Then, scan count. The lower the number the better. The subquery is the loser here. The scan count is 2 for SalesOrderDetail. The reason? The repeated code in the query.
- Then, the Worktable. All techniques used a Worktable. It means that they all utilized tempdb to process. They need temporary storage for the sum values for each SalesOrderID. As much as we don’t like Worktables, this is necessary for the process.
- Finally, the Parse and Compile Time Elapsed. The loser here is the subquery. It took longer to compile.
So, which method is better? In our example, using a CTE is better. It will also run faster given the right conditions. It used the least logical reads, scan count, and compile time. The subquery is a bit faster in this case. However, the scan count of 2 will make it slower in the long run. Now, let me reiterate that this is only for this example. It may vary in other requirements.
And just a side note: the above presentation in dbForge Studio for SQL Server makes me compare faster. Much better than manually comparing in SQL Server Management Studio. So, you see why I prefer using dbForge Studio in this article.
Comparing Execution Plans
Below is the execution plan when using CTE:

The index on OrderDate played a good part in this execution plan. Without them, you won’t find an Index Seek in SalesOrderHeader to filter order dates. Note that an Index Seek in the execution plan is generally better than a Table Scan or Index Scan. This is especially so in large tables.
See the execution plan without that extra index.

Surprisingly, the query optimizer used the same execution plan for the derived table. See below:
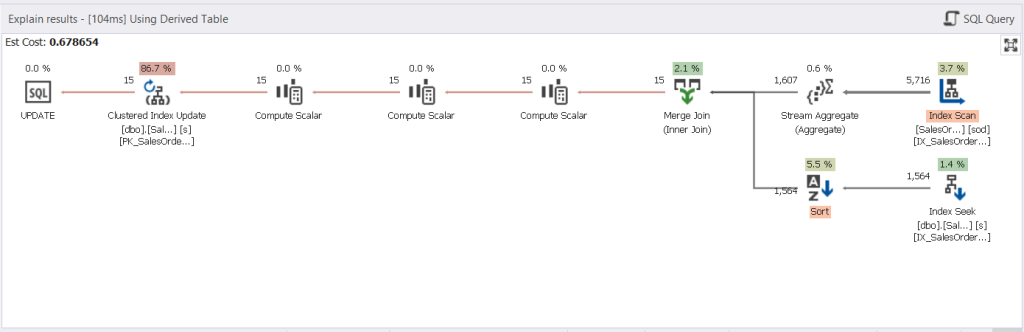
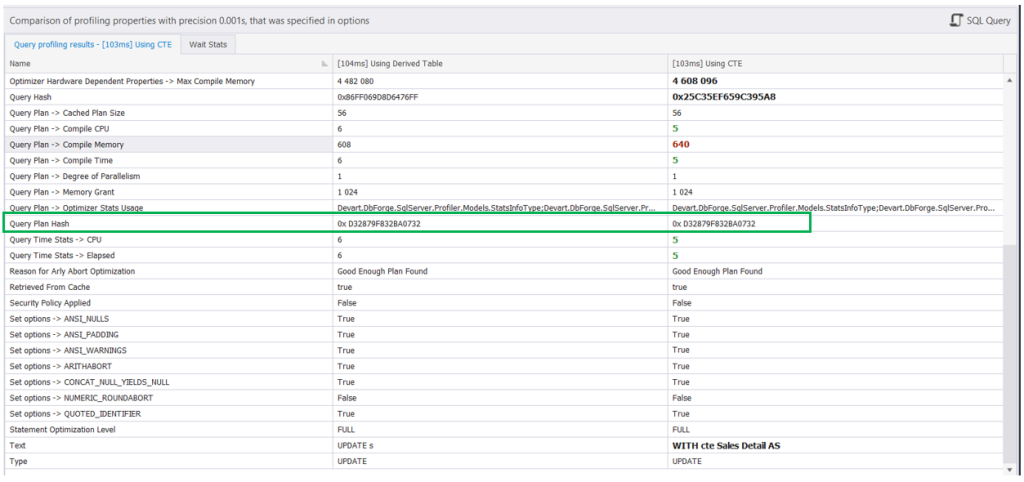
How did we know it was the same plan? The Query Profiler has the answer too. Notice the same Query Plan Hash. If they’re the same, the plan is the same.
Meanwhile, check out the execution plan used by MERGE:
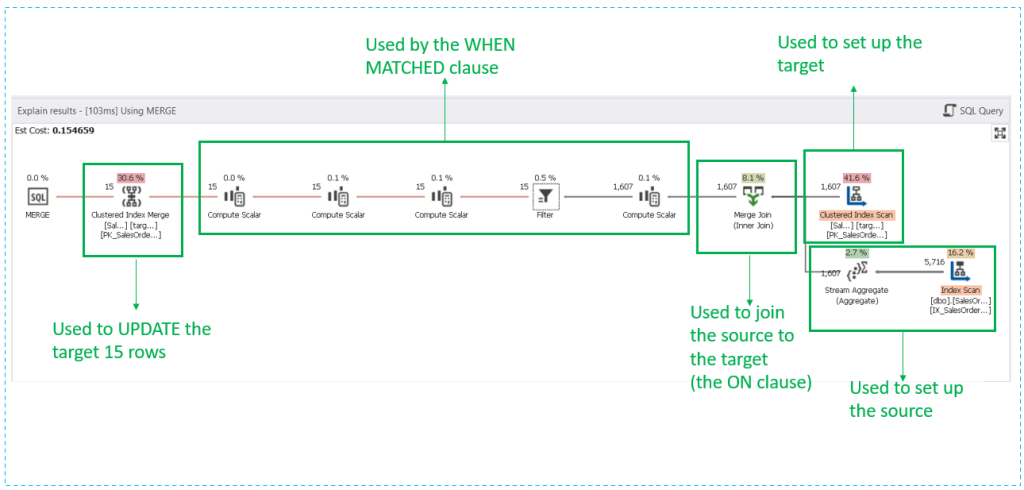
Notice a bit more complex execution plan. There’s no Index Seek. Only Index Scans. This explains why there are more logical reads.
Finally, below is the execution plan using the subquery:
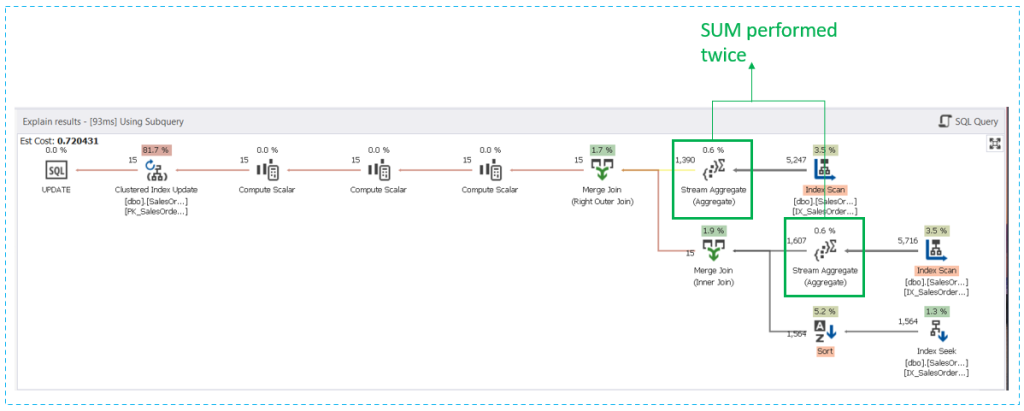
The plan is almost the same as the others. But the Stream Aggregate used to SUM(LineTotal) ran twice. Of course, there’s duplicate code in the query. So, it will reflect in the plan.
The lesson for all these comparisons? Do them every time you need to choose a method that produces the same results. With these comparisons, you can pick the best query to solve the problem.
Bulletproof Tips to UPDATE From SELECT Safely
You can learn something from what we did in this entire exercise. Though I didn’t show that we updated only the intended rows. But I can honestly tell you that it happened as expected. I leave the checking of your own tables to your capable hands. You know how to SELECT, right?
So, here are the takeaways from all that we did earlier:
- To safely do a table UPDATE while coding, dump some or all the records to another table. We dumped the 2011 records from AdventureWorks to TestDatabase. This way, making a mistake will not ruin your table rows. This applies even to development databases, especially if you’re working in a team.
- Dump some rows to UPDATE to a temporary table. So you can reset the values when you make a mistake. Create an UPDATE statement to reset the values from here.
- Make a SELECT statement to view the records you need to update. We also did this before crafting the UPDATE statement. The WHERE clause and joins should be the same between the SELECT and UPDATE statements.
- Craft the UPDATE statement. Try different techniques. Check the rows if the new values are there. You can use the OUTPUT clause to verify. Check some OUTPUT clause examples in this article. Reset the values if necessary by running the UPDATE in #2.
- Check the logical reads, scan count, estimated rows vs. actual rows, and execution plan. Then, after comparing results, choose the technique the best technique. Finally, make some changes to apply it to the actual table you need to update.
Conclusion
That’s it.
We did 4 methods to do an UPDATE from SELECT. And then, compare their query performance. The best technique is the one with the best plan, less logical reads, and more. Use indexes to improve performance. And use the comparisons like the ones done here. We only did some. There are more ways but it’s out of the scope of this article.
Your tools matter how fast you can do your SQL code and compare performance information. Using SQL Server Management Studio is just fine. But using dbForge Studio for SQL Server takes your productivity to the next level. You can have a free trial by downloading here.
Last modified: June 14, 2023



