
Indexes are speed-boosters in SQL databases. They can be clustered or non-clustered. But what does it mean and where should you apply each?
I know this feeling. I’ve been there. First-timers are often confused about which index to use on which columns. However, even experts need to think this issue through before making a decision, and different situations require different decisions. As you will see later, there are queries where a clustered index will shine compared to a non-clustered index, and vice-versa.
Still, first, we have to know each of them. If you’re looking for the same info, today is your lucky day.
This article will tell you what these indexes are and when to use each. Of course, there will be code samples for you to try in practice. So, grab your chips or pizza and some soda or coffee, and get ready to immerse yourself in this insightful journey.
Ready?
What is Clustered Index
A clustered index is an index that defines the physical sort order of rows in a table or view.
To see this in actual form, let’s take the Employee table in the AdventureWorks2017 database.
The primary key is also a clustered index, and the key is based on the BusinessEntityID column. When you do a SELECT on this table without an ORDER BY, you will see that it is sorted by the primary key.
Try it for yourself using the code below:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Now, see the result in Figure 1:
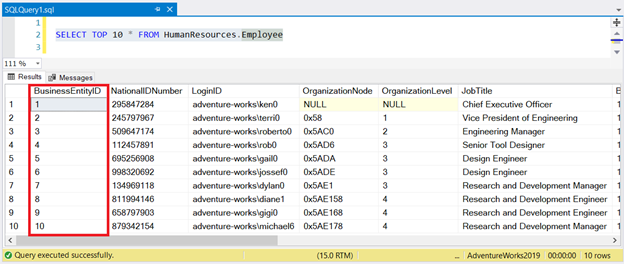
As you can see, you don’t need to sort the result set with BusinessEntityID. The clustered index takes care of that.
Unlike non-clustered indexes, you can only have 1 clustered index per table. What if we try this on the Employee table?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
We have a similar error below:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
When to Use a Clustered Index?
A column is the best candidate for a clustered index if one of the following is true:
- It is used in a large number of queries in the WHERE clause and joins.
- It will be used as a foreign key to another table, and, ultimately, to joins.
- Unique column values.
- The value will less likely to change.
- That column is used to query a range of values. Operators such as >, <, >=, <= or BETWEEN are used with the column in the WHERE clause.
But clustered indexes are not good if the column or columns
- frequently change
- are wide keys or a combination of columns with a big key size.
Examples
Clustered indexes can be created using T-SQL code or any SQL Server GUI tool. You can do it in T-SQL upon table creation, like this:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Or, you can do this using ALTER TABLE after creating the table without a clustered index:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Another way is using CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
One more alternative is using a SQL Server tool like SQL Server Management Studio or dbForge Studio for SQL Server.
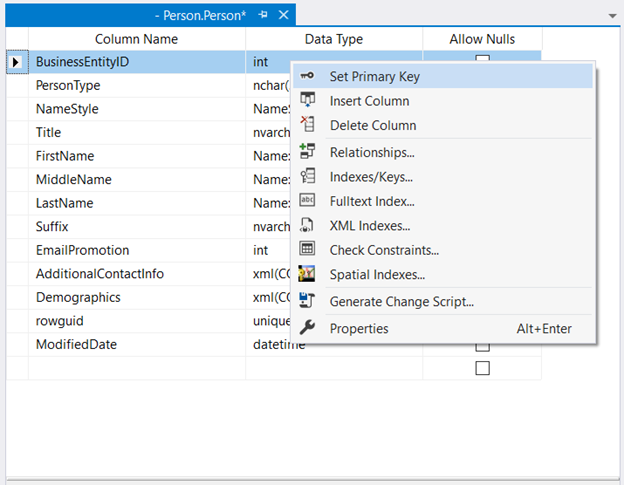
In Object Explorer, expand the database and table nodes. Then, right-click the desired table and select Design. Finally, right-click the column you want to be the primary key > Set Primary Key > Save the changes to the table.
Figure 2 below shows where BusinessEntityID is set as the primary key.
Aside from creating a single-column clustered index, you can use multiple columns. See an example in T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
After creating this clustered index, the Person table will be physically sorted by Lastname, Firstname, and MiddleName.
One of the advantages of this approach is improved query performance based on the name. Besides, it sorts results by name without specifying ORDER BY. But note that if the name changes, the table will have to be rearranged. Though this won’t happen every day, the impact can be huge if the table is very large.
What is Non-clustered Index
A non-clustered index is an index with a key and a pointer to the rows or the clustered index keys. This index can apply to both tables and views.
Unlike clustered indexes, here the structure is separate from the table. Since it’s separate, it needs a pointer to the table rows also called a row locator. Thus, each entry in a non-clustered index contains a locator and a key value.
Non-clustered indexes do not physically sort the table based on the key.
Index keys for non-clustered indexes have a maximum size of 1700 bytes. You can bypass this limit by adding included columns. This method is good if your query needs to cover more columns without increasing the key size.
You can also create filtered non-clustered indexes. This will reduce index maintenance cost and storage while improving query performance.
When to Use a Non-clustered Index?
A column or columns are good candidates for non-clustered indexes if the following is true:
- The column or columns are used in a WHERE clause or join.
- The query will not return a large result set.
- The exact match in the WHERE clause using the equality operator is needed.
Examples
This command will create a unique, non-clustered index in the Employee table:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Aside from a table, you can create a non-clustered index for a view:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Clustered and Non-Clustered Indexes: Key Distinctions
From what you saw earlier, you can already form ideas on how different clustered and non-clustered indexes are. But let’s have it on a table for easy reference.
| Info | Clustered Index | Non-clustered Index |
| Applies to | Tables and views | Tables and views |
| Allowed per Table | 1 | 999 |
| Key size | 900 bytes | 1700 bytes |
| Columns per index key | 32 | 32 |
| Good for | Range queries ( >,<, >=, <=, BETWEEN) | Exact matches (=) |
| Non-key included columns | Not allowed | Allowed |
| Filter with condition | Not allowed | Allowed |
Should Primary Keys be Clustered or Non-clustered Index?
A primary key is a constraint. Once you make a column a primary key, a clustered index is automatically created out of it, unless an existing clustered index is already in place.
Do not confuse a primary key with a clustered index! A primary key can also be the clustered index key. But a clustered index key can be another column other than the primary key.
Let’s take another example. In the Person table of AdventureWorks2017, we have the BusinessEntityID primary key. It is also the clustered index key. You can drop that clustered index. Then, create a clustered index based on Lastname, Firstname, and Middlename. The primary key is still the BusinessEntityID column.
But should your primary keys always be clustered?
It depends. Revisit the question on when to use a clustered index.
If a column or columns appear in your WHERE clause in a lot of queries, this is a candidate for a clustered index. But another consideration is how wide the clustered index key is. Too wide – and the size of each non-clustered index will increase if they exist. Remember that non-clustered indexes also use the clustered index key as a pointer. So, keep your clustered index key as narrow as possible.
If a large number of queries use the primary key in the WHERE clause, leave it also as the clustered index key. If not, create your primary key as a non-clustered index.
But what if you are still unsure? Then, you can assess the performance benefit of a column when it is clustered or non-clustered. So, tune in to the next section about it.
Which is Faster: Clustered or Non-clustered Index?
Good question. There’s no general rule. You need to check the logical reads and the execution plan of your queries.
Our short experiment will include copies of the following tables from the AdventureWorks2017 database:
- Person
- BusinessEntityAddress
- Address
- AddressType
Here’s the script:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Using the structure above, we will compare query speeds for clustered and non-clustered indexes.
We have 2 copies of the Person table. The first will use BusinessEntityID as the primary and clustered index key. The second still uses BusinessEntityID as the primary key. The clustered index is based on Lastname, Firstname, Middlename, and Suffix.
Let’s begin.
Example 1: Query Exact Matches Based On The Last Name
First, let’s have a simple query. Also, need to turn on STATISTICS IO. Then, we paste the results in statisticsparser.com for a tabular presentation.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
The expectation is the first SELECT will be slower because the WHERE clause doesn’t match the clustered index key. But let’s check the logical reads.

As expected in Figure 3, Person_pkClustered had more logical reads. Therefore, the query needs more I/O. The reason? The table is sorted by BusinessEntityID. Yet, the second table has the clustered index based on the name. Since the query wants a result based on the name, Person_pkNonClustered wins. The less logical reads, the faster the query.
What else is going on? Check out Figure 4.
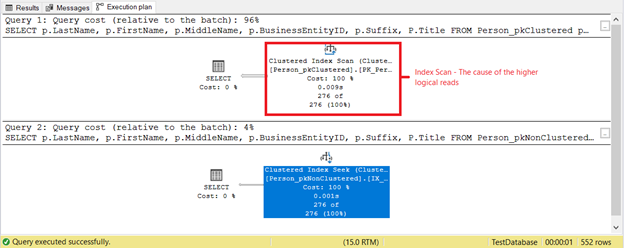
Something else happened based on the execution plan in Figure 4. Why a Clustered Index Scan is in the first SELECT instead of an Index Seek? The culprit is the Title column in the SELECT. It is not covered by any of the existing indexes. SQL Server optimizer deemed it faster to use the clustered index based on BusinessEntityID. Then, SQL Server scanned it for the right last names and got the first name, middle name, and title.
Remove the Title column, and the operator used will be Index Seek. Why? Because the rest of the fields are covered by the non-clustered index based on Lastname, Firstname, Middlename, and Suffix. It also includes BusinessEntityID as the clustered index key locator.
Example 2: Range Query Based On Business Entity Id
Clustered indexes can be good for range queries. Is that always the case? Let’s find out by using the code below.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
The listing needs rows based on a range of BusinessEntityIDs from 285 to 290. Again, the clustered and non-clustered indexes of the 2 tables are intact. Now, let’s have the logical reads in Figure 5. The expected winner is Person_pkClustered because the primary key is also the clustered index key.

Do you see lower logical reads on Person_pkClustered? Clustered indexes proved their worth on range queries in this scenario. Let’s see what more the execution plan will reveal in Figure 6.
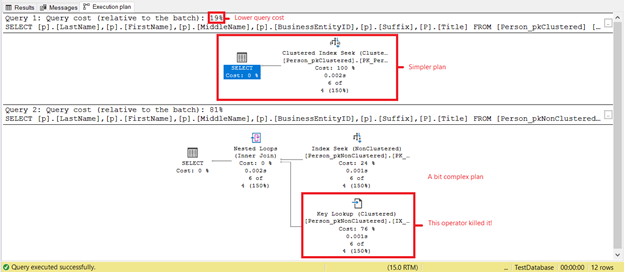
The first SELECT has a simpler plan and lower query cost based on Figure 7. This also supports lower logical reads. Meanwhile, the second SELECT has a Key Lookup operator that slows the query down. The culprit? Again, it is the Title column. Remove the column in the query or add it as an Included column in the non-clustered index. Then, you will have a better plan and lower logical reads.
Example 3: Query Exact Matches With A Join
Many SELECT statements include joins. Let’s have some tests. Here we start with exact matches:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
We expect that the second SELECT from Person_pkNonClustered with a clustered index on the name will have less logical reads. But is it? See Figure 7.
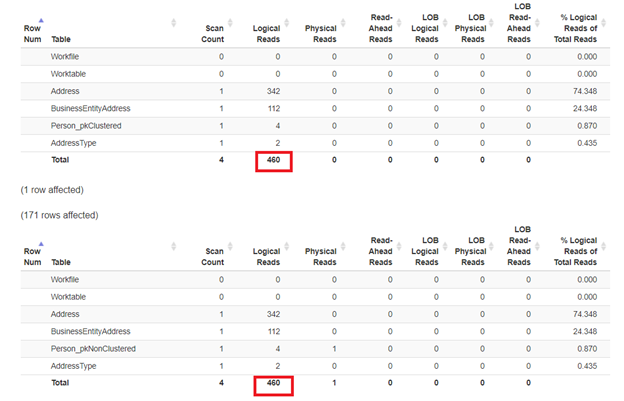
Looks like the non-clustered index on the name did just fine. The logical reads are the same. If you check the execution plan, the difference in the operators is the Clustered Index Seek on Person_pkNonClustered, and the Index Seek on Person_pkClustered.
So, we need to check the logical reads and execution plan to be sure.
Example 4: Range Query With Joins
Since our expectations can be different from reality, let’s try it with range queries. Clustered indexes are generally good with it. But what if you include a join?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Now, inspect the logical reads of these 2 queries in Figure 8:
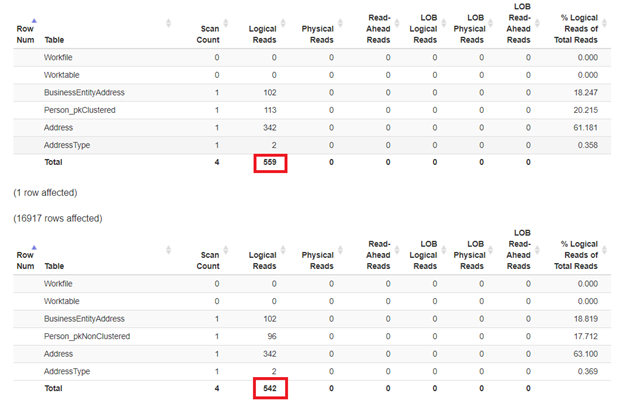
What’s happened? In Figure 9, reality bites at Person_pkClustered. More I/O cost was observed in it compared to Person_pkNonClustered. That’s different from what we expect. But based on this forum answer, a non-clustered index seek can be faster than clustered index seek when all columns in the query are 100% covered in the index. In our case, the query for Person_pkNonClustered covered the columns using the non-clustered index (BusinessEntityID – key; Lastname, Firstname, Middlename, Suffix – pointer to clustered index key).
Example 5: Insert Performance
Then, try to test INSERT performance over the same tables.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
Figure 9 shows the INSERT logical reads:

Both generated the same I/O. Thus, both performed the same.
Example 6: Delete Performance
Our last test involves DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
Figure 10 shows the logical reads. Note the difference.

Why do we have higher logical reads on Person_pkClustered? The thing is, the DELETE statement condition is based on an exact match of a name. The optimizer will have to resort to the non-clustered index first. It means more I/O. Let’s confirm using the execution plan in Figure 11.
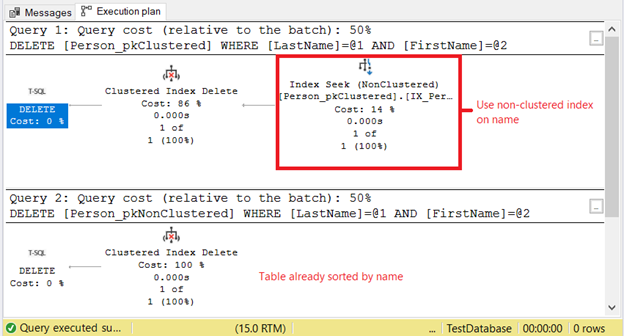
The first SELECT needs an Index Seek on the non-clustered index. The reason is the WHERE clause on Lastname and Firstname. Meanwhile, Person_pkNonClustered is already physically sorted by name because of the clustered index.
Takeaways
Forming high-performing queries isn’t about luck. You cannot just put a clustered and a non-clustered index and then suddenly, your queries have the speed force. You need to keep using the tools as your lens to focus on the small details other than the result set.
But sometimes you just don’t have time to do all of these. I think that’s normal. But as long as you don’t mess up that much, you have your job the next day, and you can work it out. This won’t be easy at first. It will actually be confusing. You will also have a lot of questions. But with constant practice, you can achieve it. So, keep your chin up.
Remember, both clustered and non-clustered indexes are for boosting queries. Knowing the key differences, the usage scenarios, and the tools will help you in your quest for coding high-performance queries.
I hope this post answers your most pressing questions about clustered and non-clustered indexes. Do you have something else to add for our readers? The Comments section is open.
And if you find this post enlightening, please share it on your favorite social media platforms.
More information about indexes and query performance is in the below articles:
- 22 Nifty SQL Index Examples to Warp Speed Your Queries
- SQL Query Optimization: 5 Core Facts to Boost Your Queries









[…] Clustered and Non-clustered Indexes Described […]