
In the article, An Overview of the Azure Synapse Analytics, we explored the Azure Synapse workspace and its features as an analytics service combining Big data analytics and enterprise data warehousing.
This article is a practical demonstration of deploying Azure Synapse Analytics workspace using the Azure portal.
Table of contents
- How to Deploy Synapse Analytics Workspace in Azure
- Basics
- Security
- Networking
- Getting Started
- Analyze Azure Open Datasets Using the Serverless SQL Pool
- Conclusion
How to Deploy Synapse Analytics Workspace in Azure
Go to the search box and look for Azure Synapse Analytics in the services in the Azure portal.
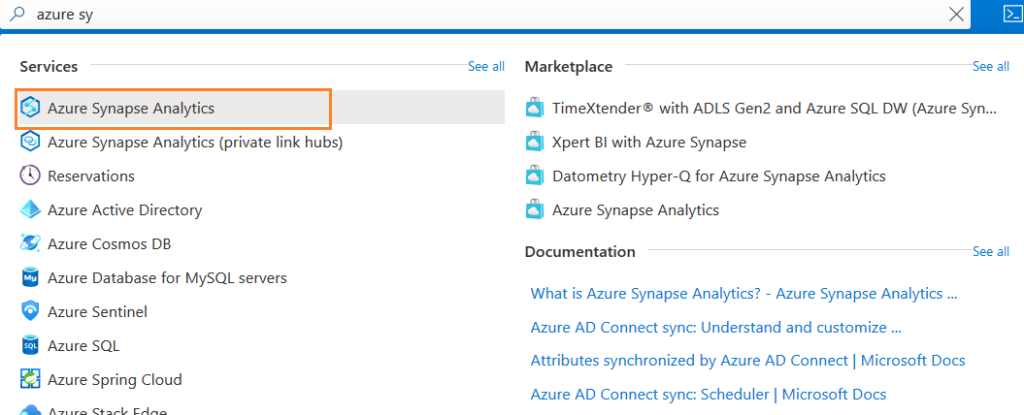
We do not have any synapse workspace deployed. Therefore, you get the page “No Azure Synapse Analytics to display”.

Click Create, and you get a page Create synapse workspace. This page is divided into multiple sections: Basic, Security, Networking, Tags, Review + Create.
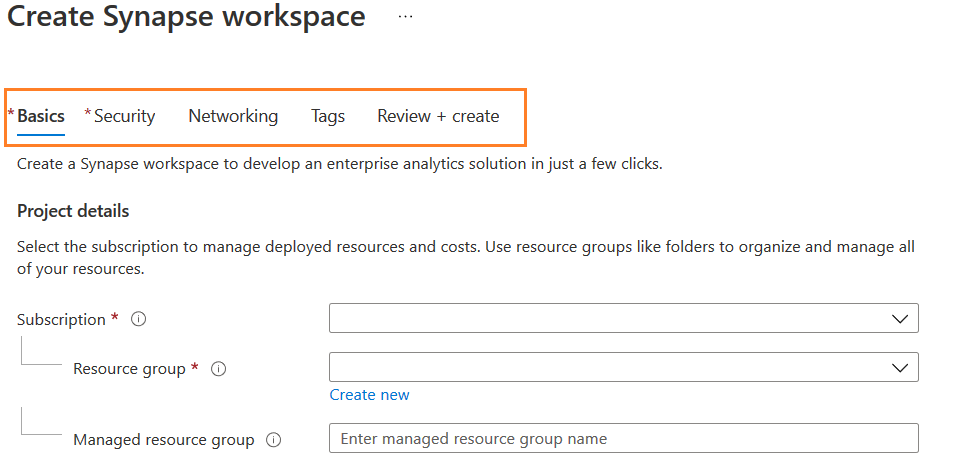
Basics
The basics section requires Azure subscription, resource group, managed resource group, workspace name, region, account name, and file system name.
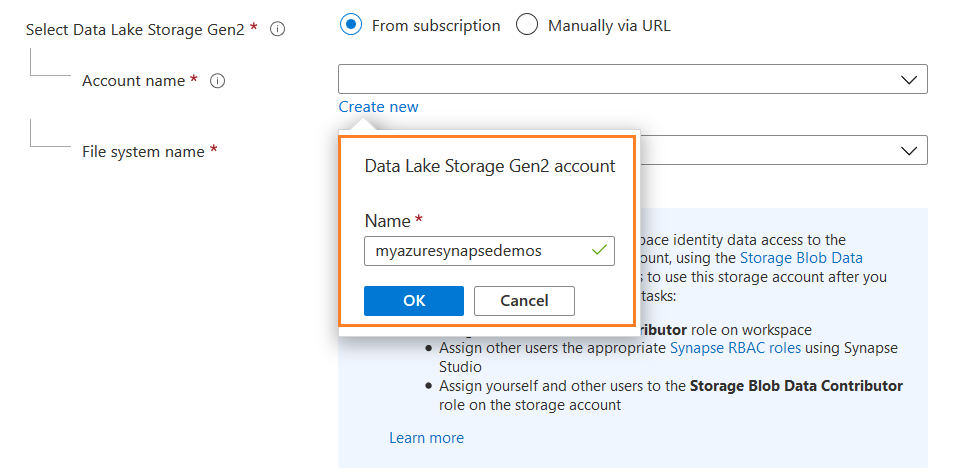
The synapse workspace requires a data lake storage gen2 account and storage blob role as its data contributor. You can configure a separate gene2 storage account and specify the URI using the option – Manually via URL. In this demonstration, we choose from subscription and specify the new deployment’s storage account name and file system name.
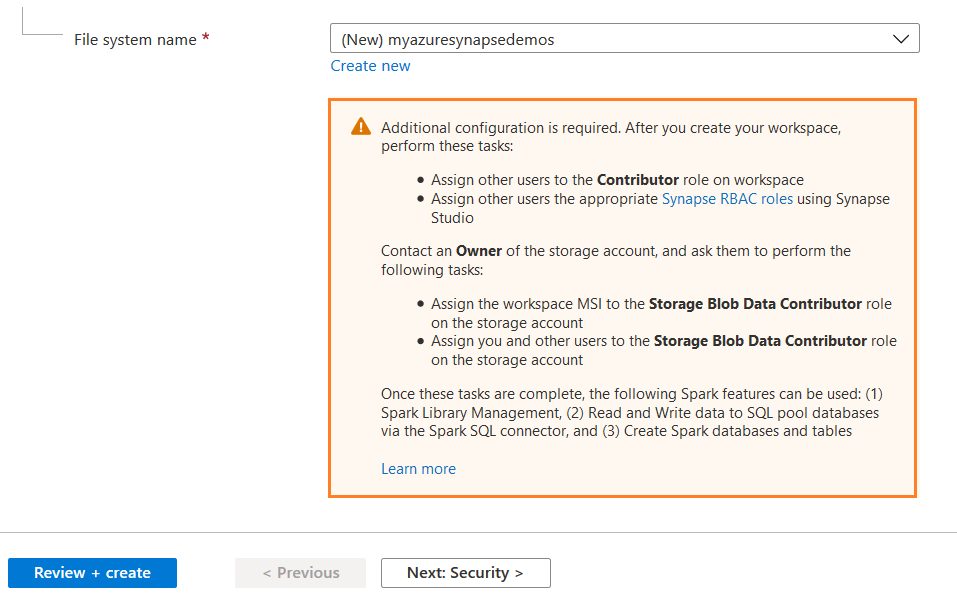
As highlighted below, it gives details of a few additional configurations for providing permissions to other users on the synapse workspace.
Security
Enter the credentials that will be the administrator for the synapse workspace SQL pool in the security tab. To generate an automatic password, leave the password section empty.
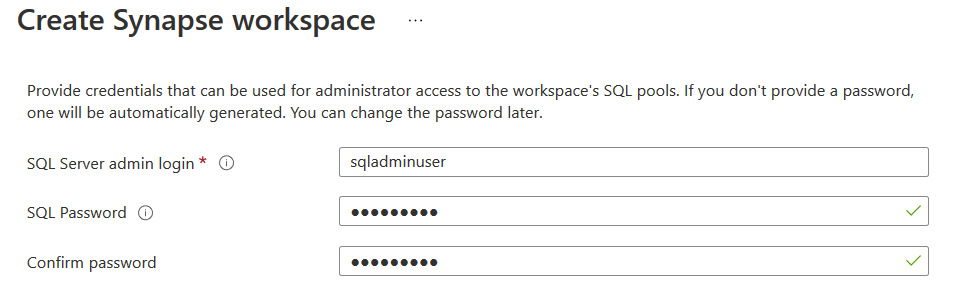
Scroll down and verify that you have the following options checked – Allow pipelines (running as workspace system identity) to access the SQL pools.
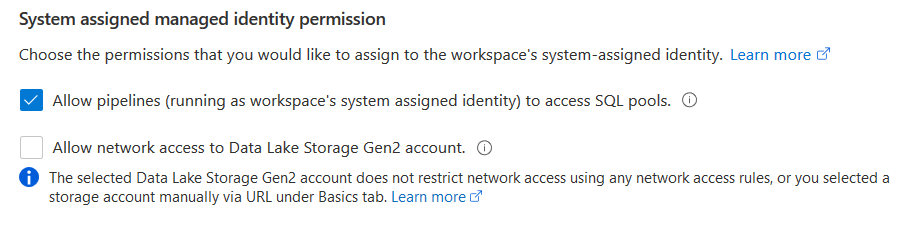
You also get an option to do workspace encryption with the customer-managed key. If you choose this option, it configures the double encryption using the platform-managed keys at the infrastructure layer. We can skip workspace encryption for this article.
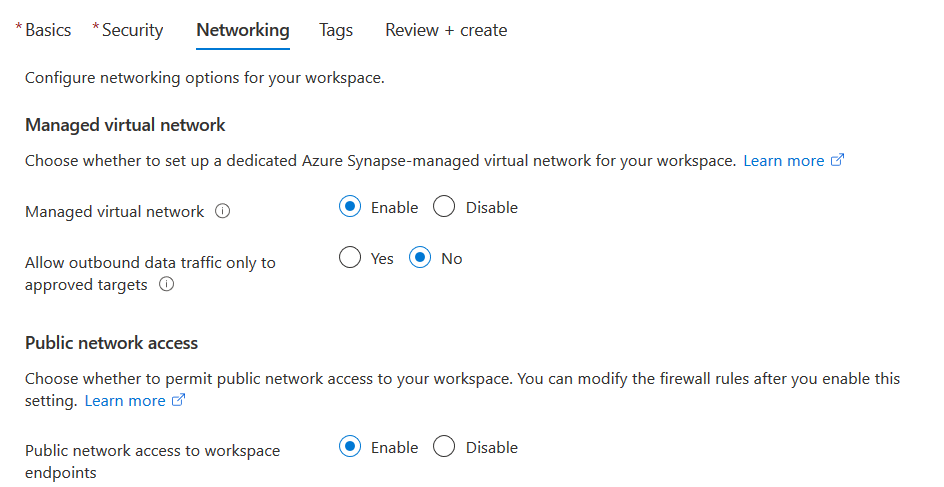
Networking
You can choose to configure public or private networking connectivity to the Azure workspace. By default, the option Managed virtual network is disabled. If we want to use the Azure internal network instead of open internet for synapse workspace, data sources, you can use the synapse managed virtual network.
Click Review + Create, and it starts deploying Azure Synapse Workspace. Once the validation is successful, you get an estimated server SQL cost per TB.
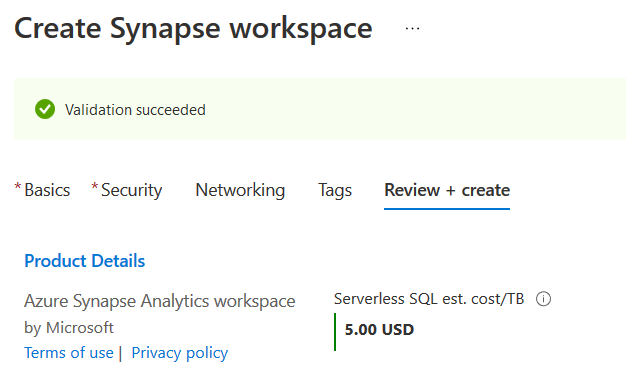
Scroll down in the review page and note down the data lake storage Gen2 account URL.
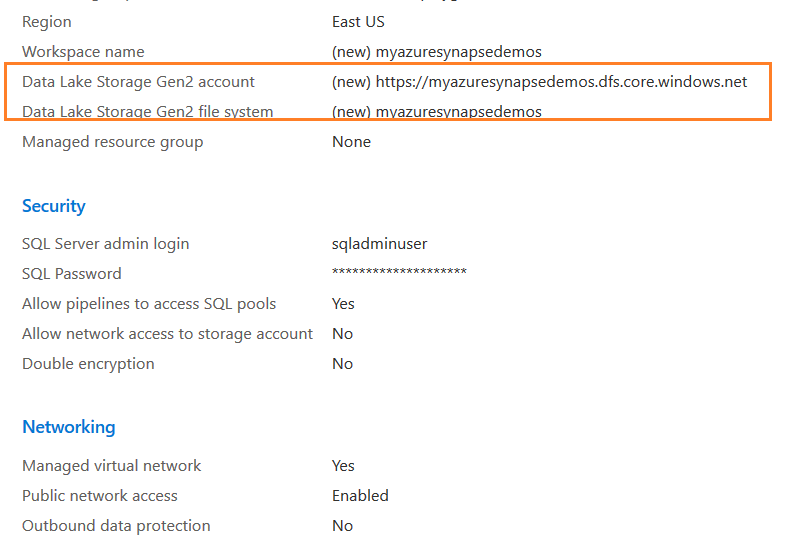
Click Create, and it starts synapse workspace deployment.

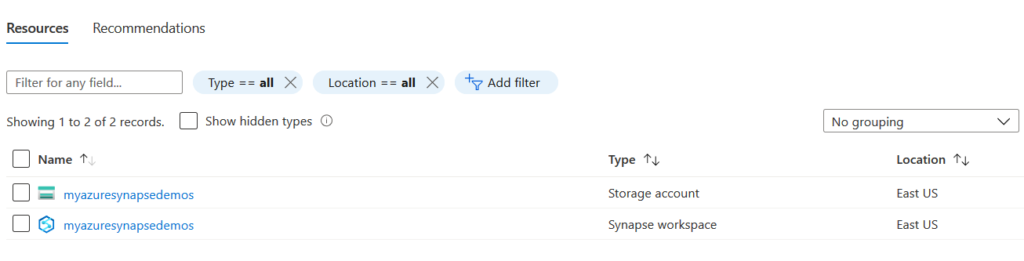
As shown below, it creates a storage account and synapse workspace.
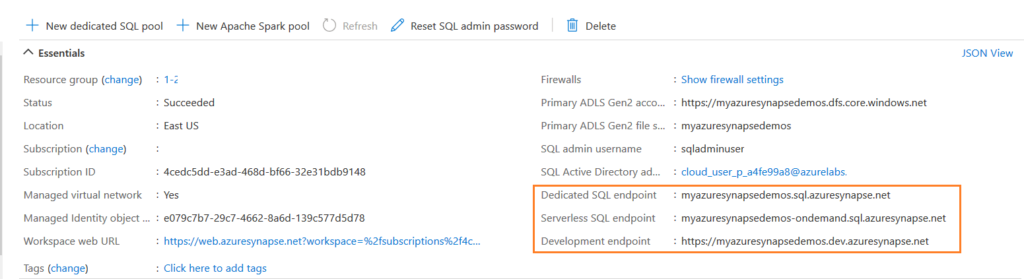
Click Synapse workspace, and you get the following details.
- Workspace web URL
- Primary ADLS Gen2 account
- Primary ADLS Gen2 file system
- SQL admin username
- SQL active directory admin
- Dedicated SQL endpoint
- Serverless SQL endpoint
- Development endpoint
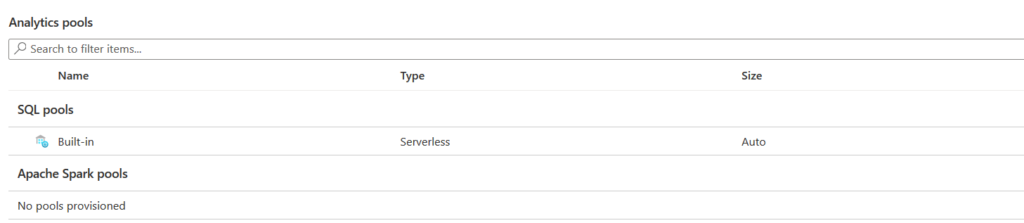
In the analytics pools section, you get deployed SQL pools or Apache Spark pools. By default, it deploys an SQL pool in serverless mode.
Getting Started
In this section, click Open Synapse Studio to build a fully integrated analytics solution.
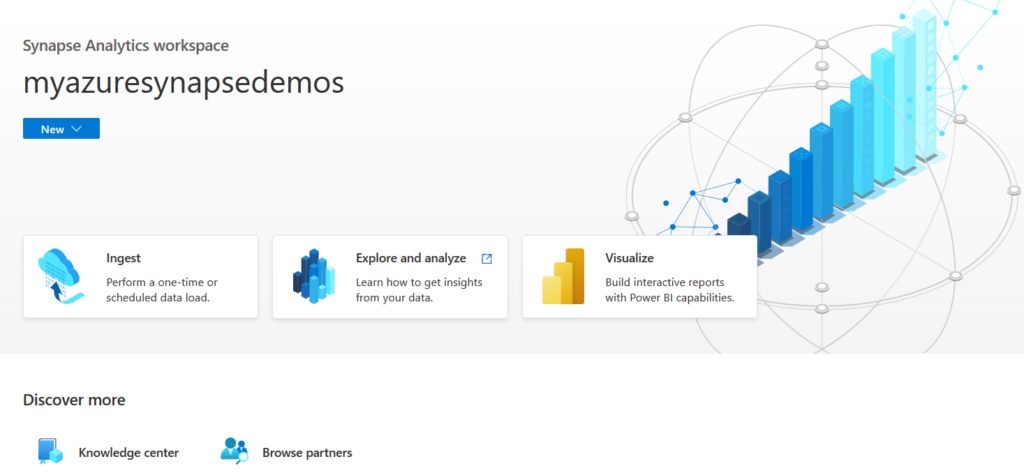
It opens the following synapse Analytics workspace with few tiles – Ingest, Explore & Analyze, Visualize.
You also get an option Knowledge center that gives Azure Open Datasets and sample code to learn about the synapse workspace.
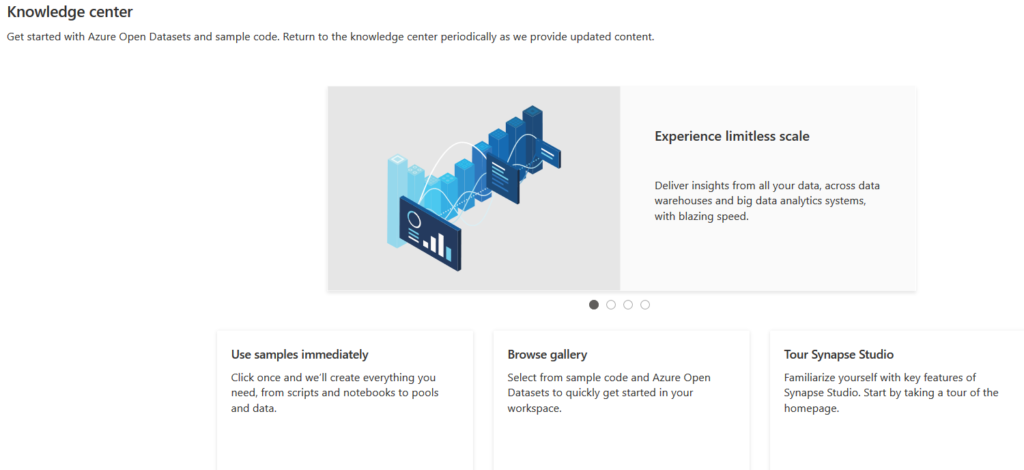
- Use samples immediately
- Browse gallery
- Tour Synapse Studio
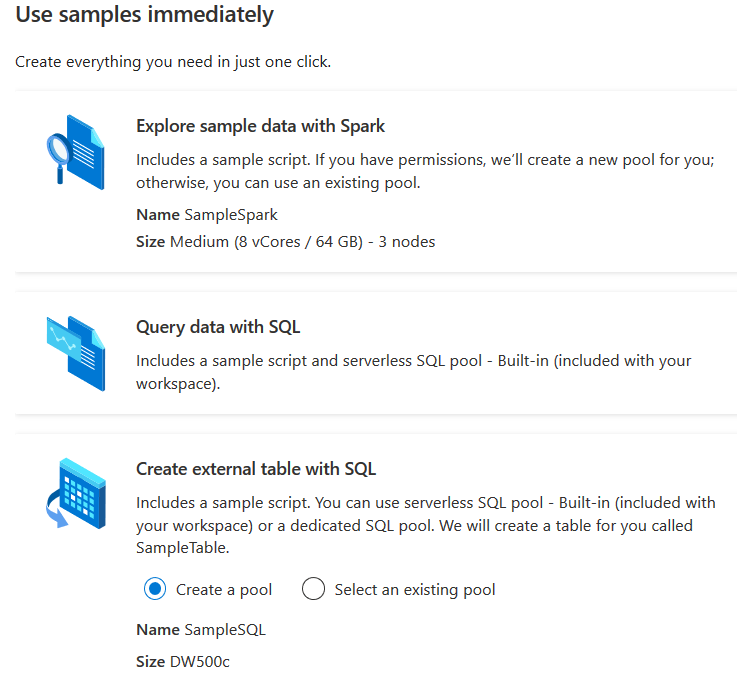
To understand the synapse analytics solution, let’s use the samples with the option Use Samples immediately. Here, you get the following options:
- Explore sample data with spark: It creates a sample script along with a new or existing spark pool.
- Name: SampleSpark
- Size: Medium 8 vCores , 64 GB – 3 nodes
- Query data with SQL: It creates a sample script that you can use with a SQL On-demand(default) pool.
- Create an external table with SQL: It creates a standard SQL pool for accessing external data.
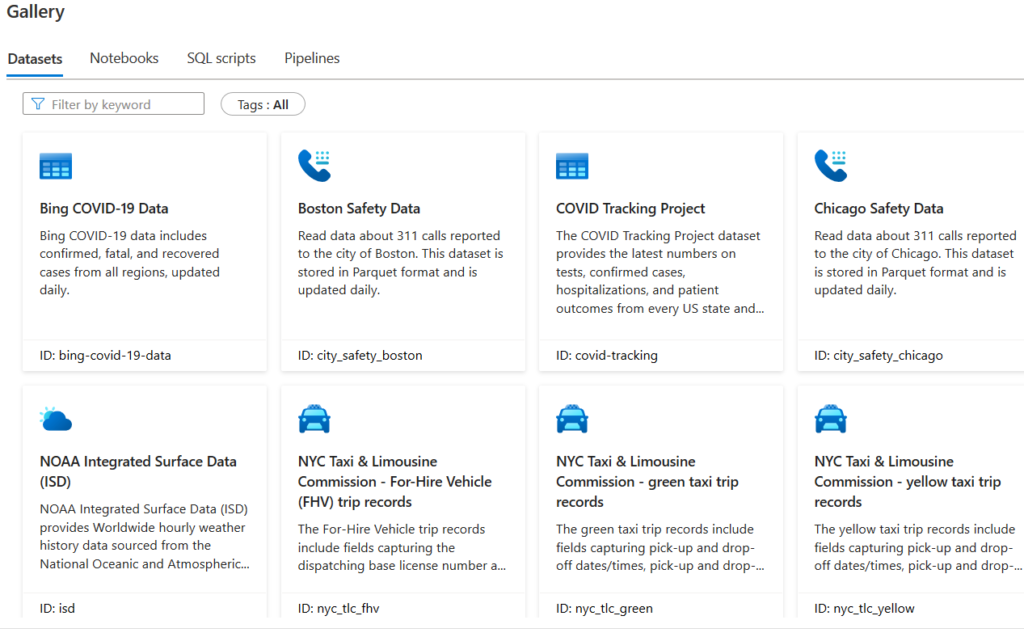
Go back and click Browse Gallery. It gives a wide range of data sets, notebooks, SQL scripts, and pipelines.
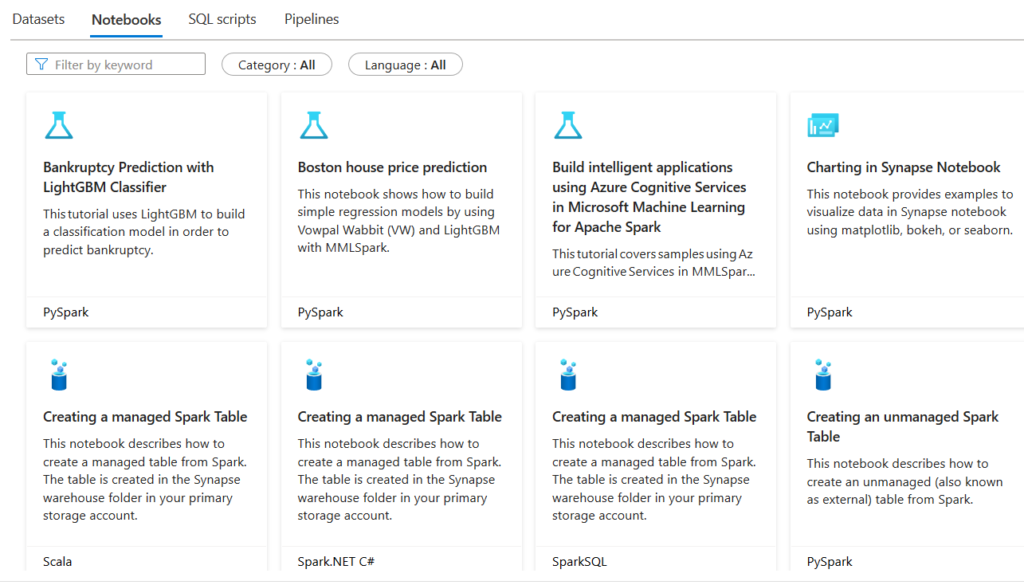
Click Notebooks, and you get sample notebooks in different languages such as PySpark, Scala, Spark.net C#.
Analyze Azure Open Datasets Using the Serverless SQL Pool
For this article, we use the sample script Analyze Azure Open Datasets using serverless SQL pool. It demonstrates the exploratory data analysis using serverless SQL pools. It visualizes the results in the Azure Synapse studio.
Note: You can refer to sample serverless SQL pools for more details.
Select the script and click Continue to open the following page with SQL script. For the demo, the data is stored in the Azure Storage account blob in the Parquet file format. Therefore, it can use an automatic schema interface where you do not need to specify the data type of the columns in the file.
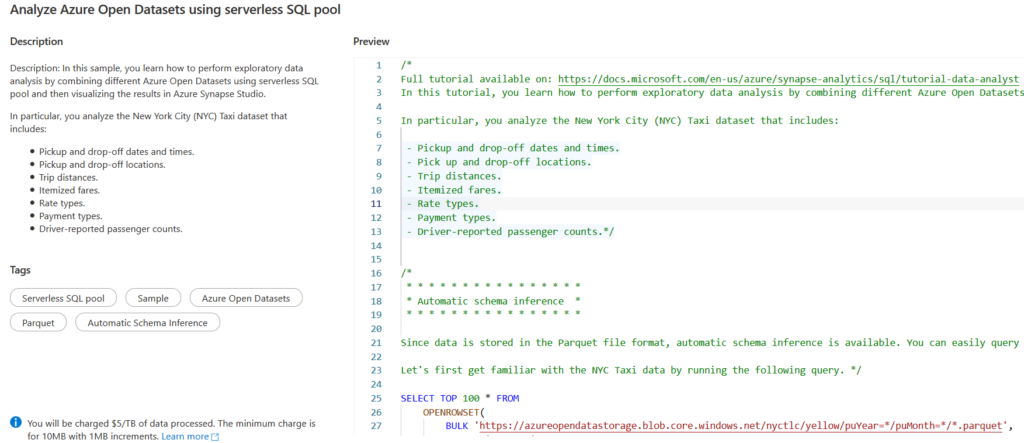
For example, the below SQL script returns the NYC Taxi data from the PARQUET file:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc];Click the Open script option and select the parameters’ values from the drop-down.
- Connect to: Select SQL pools
- Use database: Select the default database as master
We can select the options to return the first 5000 rows (default) or all properties.
Click Run to start deployment.
It starts populating the query results in the tabular format.
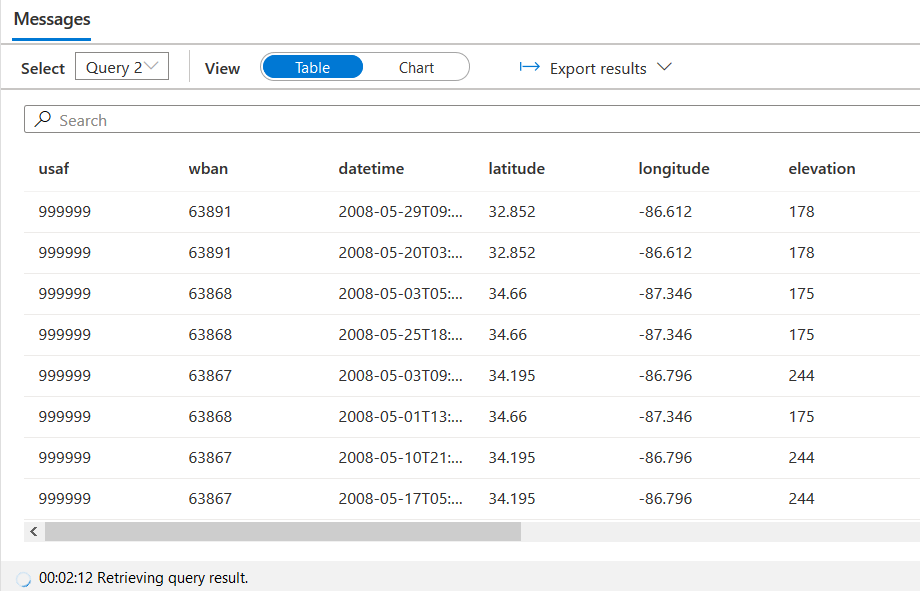
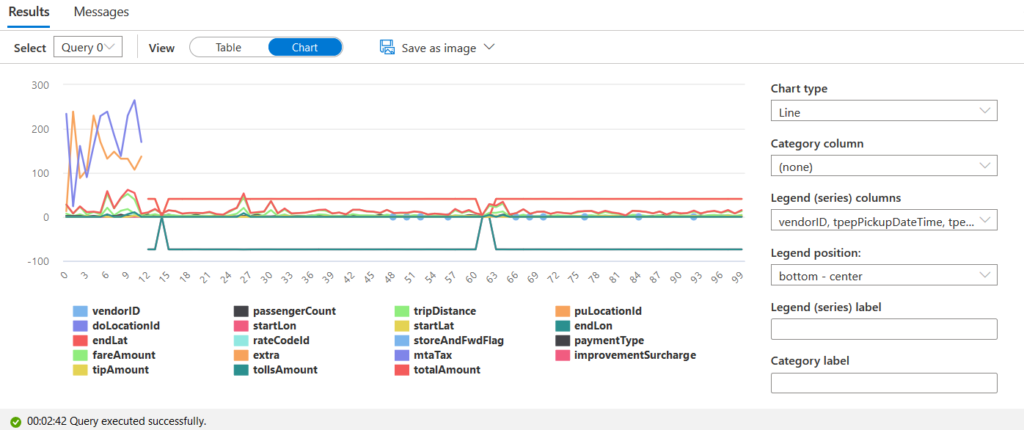
If there are multiple queries in the scripts, each query gives its results for individual queries. You can view the results in chart format as well. For example, the following figure displays the result in chart format for query 0.
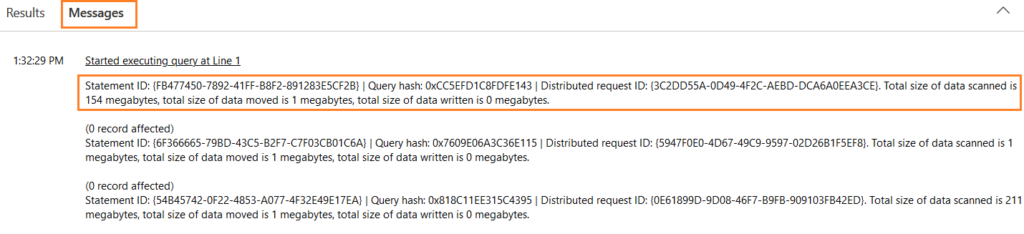
The message section gives information such as the total size of data scanned, the total size of data moved, the total size of data written.
Conclusion
This article explored the Azure Synapse Workspace deployment, different configurations for networking, and Azure data lake gen2 storage account. We also used the Azure samples for processing data stored in Azure storage parquet files.
Tags: azure, azure dw, azure sql Last modified: October 06, 2022







