Database replication is the technology to distribute data from the primary server to secondary servers. Replication works on Master-slave concept where Master database distributes data to one or multiple slave servers. Replication can be set up between multiple SQL Server instance on the same server, OR it can be set up between multiple database servers within same or geographically separated data centers.
There are two main benefits of using SQL Server replication:
- Using replication, we can get nearly real-time data which can be used for reporting purpose. For example, when you want to separate the write intensive OLTP load on one server and read-intensive load on another server, you can set up replication to keep data synchronized on both servers.
- The second benefit is that you can schedule the replication to run on specific time. For example, if you want that report server contains data of completed day than you can schedule the replication snapshot accordingly. We do not need to write additional logic to deal with current data.
Replication offers lots of flexibility. Using replication, we can filter out the rows and also we can replicate the subset of data of any table. We can change the replicated data or replicate only update and insert and ignoring the deletes. We can also replicate the data from another database system like Oracle.
Components of Replication
There are seven core components of SQL Server Replication. Following is the list:
- Publisher.
- Distributor.
- Subscriber.
- Articles.
- Publication.
- Push Subscription.
- Pull Subscription.
Following are the details:
Articles
An article is a database object, such as a SQL table, or a stored procedure. As I mentioned above, using Replication, we can filter data, or we can replicate the selected table column, hence table columns or rows are considered as articles.
Publication
Articles cannot be replicated until they become a part of the publication. Publication is the group of the Articles/Database objects. It also represents the dataset that will be replicated by SQL Server.
Publisher
Publisher contains a master database which has the data that needs to be published. It determines what data should be distributed across all subscriber.
Distributor
The distributor is the bridge between publisher and subscriber. Distributer gathers all the published data and holds it until sending across all the subscribers. It’s a bridge between publisher and subscriber. It supports multiple publishers and subscriber concept. It is not mandatory to configure distributor on a separate SQL Instance or a separate server. If we do not configure it, the publisher can act as a distributor. Organizations that have large-scale replication can configure distributor on a separate system.
Subscribers
The subscriber is the end of the source or the destination to which data or replicated publication will be transmitted. In replication, there is one publisher, it can have multiple subscribers.
Push Subscription
In a push subscription, the publisher updates the data to the subscriber. In a Push subscription, the subscriber is passive. The publisher sends articles or publications to all its subscribers. Based on the organization’s requirement, in creating replication wizard, on the screen, you can select the subscription to be used. Transaction replication and peer-to-peer replication uses the Push subscription to maintain the real-time availability of data.
Pull Subscription
In a Pull subscription, all subscribers request the new data or updated data from its publisher. In a pull subscription, we can control that what data or data changes are needed to subscribers. It is useful when we do not need the changed data immediately.
Replication Types
SQL Server supports three replication types:
- Transactional Replication.
- Snapshot Replication.
- Merge Replication.
Transactional Replication
Transactional replication, any schema changes, data changes occur on the publisher database will be replicated on the subscriber database. Whenever any Update, Delete or Insert operations occur on the publisher database, the changes are tracked, and those changes are sent to the subscriber databases. Transactional replication sends only a limited amount of data over a network. Moreover, changes are nearly real-time, hence it can be used to set up the DR site, or it can be used to scale out the reporting operations. Transactional replication is ideal for the following situations:
- When you want to set up a system where changes made on publisher should be applied to subscribers immediately.
- The publisher has high low INSERT, UPDATES, and DELETES.
- When you want to set up heterogeneous replication meaning, publisher or subscribers for non-SQL Server databases, like Oracle.
When any changes are made on the publisher database, changes logged in a log file on publisher database. Distributor / Publisher site, two jobs will be created.
- Snapshot Agent: Snapshot agent job generates the snapshot of schema, data of the objects which we want to replicate or publish. Files of the snapshot can be saved on the Publisher server or network location. When we initiate the replication for the first time, it creates a snapshot and applies it to all subscribers. Snapshot agent remains idle until it is triggered manually or scheduled to run on specific time.
- Log Reader Agent: Log reader agent job runs continuously. It reads the changes (INSERT, UPDATES, and DELETES) occurred from the transaction log of the publisher database and sends them to a distribution agent.
- Distribution Agent: Once changes are retrieved from the Log reader agent, distribution agent sends all the changes to the subscribers.
When we configure transactional replication, it performs following activities
- It initiates by taking the First snapshot of publication data and database objects and snapshot applied to subscribers.
- Log reader agent continuously monitors the T-Log of the publisher and if any changes occur, it sends them to the distributor or directly to subscribers.
The following image represents how transactional replication works:
![]()
Advantages:
- Transaction replication can be used as a standby SQL server, or it can be used for the load balancing or separating reporting system and OLTP system.
- Publisher server replicates data to subscriber server with low latency.
- Using transactional replication, object level replication can be implemented.
- Transactional replication can be applied when you have fewer data to protect, and you should have a fast data recovery plan.
Disadvantages:
- Once the replication establishes, the schema changes on the publisher do not apply on the subscriber server. We must make those changes manually by generating a new snapshot and applying it to subscribers.
- If we change the servers, we must reconfigure the replication.
- If transactional replication used as a DR setup, we have to failover manually.
Snapshot Replication
Snapshot replication generates a complete picture/snapshot of publication on a defined schedule and sends the snapshot files on subscribers. When snapshot replication occurs, destination data will be replaced with a new snapshot. Snapshot replication is the best option when data is less volatile. For example, Master tables like City, Zipcode, Pincode are best candidates for snapshot replication.
While configuring snapshot replication, the following important components are defined:
- Snapshot Agent: It creates a complete image of schema and data defined in publication and sends it to the distributor. Snapshot agent remains idle until it is triggered manually OR scheduled to run on specific time.
- Distributor agent: It sends the snapshot files to subscribers and applies schema and data by replacing the existing one.
Snapshot replication performs the following activities:
- On the defined schedule, the snapshot agent places a shared lock on the schema and data to be published.
- Entire snapshot of published data copied to the distributor end. Snapshot agent creates three files
- File to created database schema of published data.
- BCP file to export data within SQL Tables
- Index Files to export index data.
- Once files are created, snapshot agent release shared locks on published data and data.
- Distributor agents start and replace the subscriber schema and data using files created by the snapshot agent.
The following image illustrates how snapshot replication works.
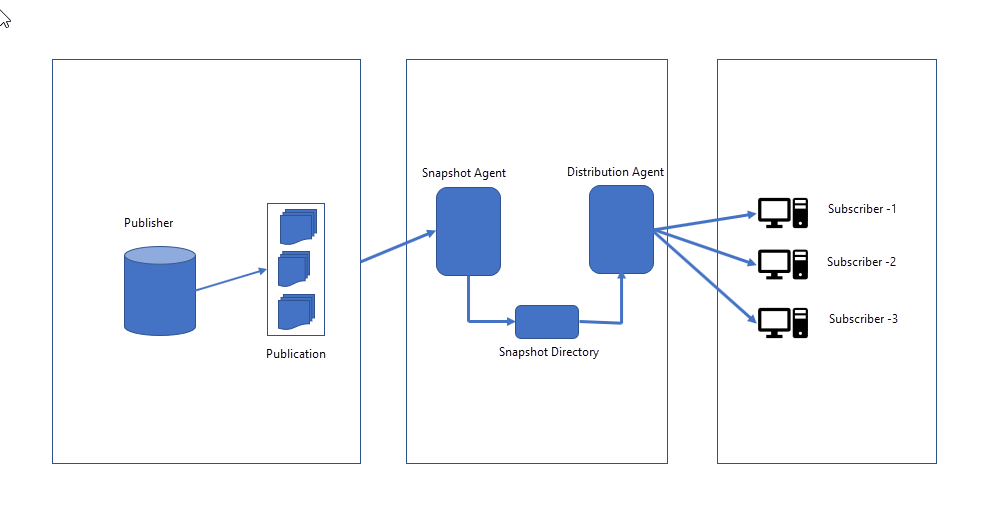
Advantages
- Snapshot replication is very simple to set up. If data is changed not frequently, snapshot replication is a very suitable option.
- You can control when to send data. For example, a master table that has a high volume of data, but changes less frequently than you can replicate the data when the traffic is low.
Disadvantages
- Snapshot generated by the snapshot agent contains changed and unchanged published data, therefore the snapshot transmitted over the network can produce latency and impact other operations.
- As data increases, the size of snapshot increases and it takes more time to create and distribute the snapshot to subscribers.
Merge Replication
Merge replication can be used when we need to manage changes on multiple servers and these changes need to be consolidated.
When we configure merge replication, the following components will be created:
- Snapshot Agent: Snapshot agent generates the first snapshot of publication data and database objects. Once the snapshot is created, it will be distributed to all subscribers.
- Merge Agent: Merge agent is responsible for resolving the conflicts between publisher and subscribers. Any conflicts are resolved through the merge agent which uses conflict resolution. Depending on how you configured the conflict resolution, the conflicts are resolved by the merge agent.
When we configure merge replication, it performs the following activities:
- It initiates by taking a snapshot of publication data and database objects and snapshot applied to subscribers.
- While configuring merge replication, it creates triggers on publisher and subscriber. Triggers are responsible for keeping track of subsequent changes and table modifications on publisher and subscribers.
- When publisher and subscribers connect to the network, changes of data rows and schema modification will be synchronized with each other. While merging the changes of the publisher and subscribers, merge agent resolves the conflicts based on the conditions defined in the merge agent.
Merge replication is used in server to client environments, and it is ideal for the situations where subscribers need to retrieve data from the publisher, make changes offline and then synchronize changes with the publisher and other subscribers.
There can be practical situations where the same row is changed by different publishers and subscribers. At that time, the Merge agent will look at what conflict resolution is defined and make changes accordingly.
SQL Server uniquely identifies a column using a globally unique identifier for each row in a published table. If the table already has a unique identifier column, then SQL Server automatically uses that column. Otherwise, it will add a rowguid column in the table and creates an index based on the column.
Triggers will be created on the published tables on both, publishers and subscribers. They are used to track the changes based on the row or column changes.
The following image illustrates how merge replication works:
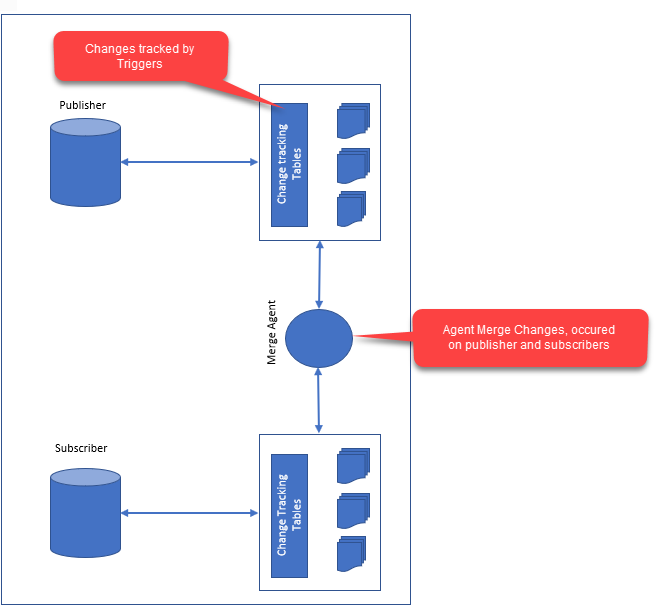
Advantages:
- This is the only way to manage to consolidate changes on multiple server data.
Disadvantages:
- It takes a lot of time to replicate and synchronize both ends.
- There is low consistency as a lot of parties must be synchronized.
- There can be conflicts while merging replication if the same rows are affected in more than one subscriber and publisher. It can be fixed using the conflict resolution, but it makes the replication setup more complicated.
T-SQL code to review replication configuration
I have configured the snapshot replication and transactional replication on two instances of my machine. Using SQL dynamic management (DMVs), we can check the configuration of replication. To review the configuration of replication we can use T-SQL code. Script code populates the following:
- Subscriber database name.
- Publisher Name.
- Subscription type.
- Publisher database.
- Replication Agent Name.
Below is the script:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Following is the output:

Summary
In this article, I have explained:
- The fundament and benefits of Replication and its components.
- Transactional replication.
- Snapshot replication.
- Merge Replication.







good job thank you