The concept of good or bad design is relative. At the same time, there are some programming standards, which in most cases guarantee effectiveness, maintainability, and testability. For example, in object-oriented languages, this is the use of encapsulation, inheritance, and polymorphism. There is a set of design patterns that in a number of cases have a positive or negative effect on the application design depending on the situation. On the other hand, there are opposites, following which sometimes leads to the problem design.
This design usually has the following indicators (one or several at a time):
- Rigidity (it is difficult to modify the code, as a simple change affects many places);
- Immobility (it is complicated to split the code into modules that can be used in other programs);
- Viscosity (it is quite difficult to develop or test the code);
- Needless complexity (there is an unused functionality in the code);
- Needless repetition (Copy/Paste);
- Poor readability (it is difficult to understand what the code is designed for and to maintain it);
- Fragility (it is easy to break functionality even with small changes).
You need to be able to understand and distinguish these features in order to avoid a problem design or to predict possible consequences of its use. These indicators are described in the book «Agile Principles, Patterns, And Practices in C#» by Robert Martin. However, there is a brief description and no code examples in this article as well as in other review articles.
We are going to eliminate this drawback dwelling upon each feature.
Rigidity
As it has been mentioned, a rigid code is difficult to be modified, even the smallest things. This may not be an issue if the code is not changed often or at all. Thus, the code turns out to be quite good. However, if it is necessary to modify the code and difficult to do this, it becomes a problem, even if it works.
One of the popular rigidity cases is to explicitly specify the class types instead of using abstractions (interfaces, base classes, etc.). Below, you can find an example of the code:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
}
Here class A depends on class B very much. So, if in future you need to use another class instead of class B, this will require changing class A and will lead to it being retested. In addition, if class B affects other classes, the situation will become much complicated.
The workaround is an abstraction that is to introduce the IComponent interface via the constructor of class A. In this case, it will no longer depend on the particular class В and will depend only on the IComponent interface. Сlass В in its turn must implement the IComponent interface.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
}
Let’s provide a specific example. Assume there is a set of classes that log the information – ProductManager and Consumer. Their task is to store a product in the database and order it correspondingly. Both classes log relevant events. Imagine that at first there was a log into a file. To do this, the FileLogger class was used. In addition, the classes were located in different modules (assemblies).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
}
If at first it was enough to use only the file, and then it becomes necessary to log into other repositories, such as a database or a cloud-based data collection and storage service, then we will need to change all classes in the business logic module (Module 2) that use FileLogger. After all, this can turn out to be difficult. To solve this issue, we can introduce an abstract interface to work with the logger, as shown below.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
}
In this case, when changing a logger type, it is enough to modify the client code (Main), which initializes the logger and adds it to the constructor of ProductManager and Consumer. Thus, we closed the classes of business logic from the modification of the logger type as required.
In addition to direct links to the used classes, we can monitor rigidity in other variants that may lead to difficulties when modifying the code. There can be an infinite set of them. However, we will try to provide another example. Assume there is a code that displays the area of a geometrical pattern on the console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
}
As you can see, when adding a new pattern, we will have to change the methods of the ShapeHelper class. One of the options is to pass the algorithm of rendering in the classes of geometrical patterns (Rectangle and Circle), as shown below. In this way, we will insulate the relevant logic in the corresponding classes thereby reducing the responsibility of the ShapeHelper class before displaying information on the console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
}
As a result, we actually closed the ShapeHelper class for changes that add new types of patterns by using inheritance and polymorphism.
Immobility
We can monitor immobility when splitting the code into reusable modules. As a result, the project may stop developing and being competitive.
As an example, we will consider a desktop program, the whole code of which is implemented in the executable application file (.exe) and has been designed so that the business logic is not built in separate modules or classes. Later, the developer has faced the following business requirements:
- To change the user interface by turning it into a Web application;
- To publish the functionality of the program as a set of Web services available to third-party clients to be used in their own applications.
In this case, these requirements are difficult to be met, as the whole code is located in the executable module.
The picture below shows an example of an immobile design in contrast to the one that does not have this indicator. They are separated by a stipple line. As you can see, the allocation of the code on reusable modules (Logic), as well as the publication of the functionality at the level of Web services, allow using it in various client applications (App), which is an undoubted benefit.
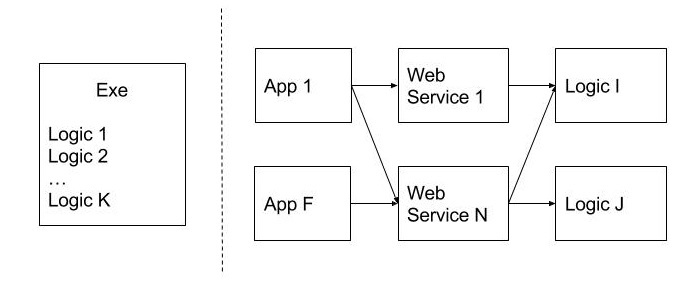
Immobility can also be called a monolithic design. It is difficult to split it into smaller and useful units of the code. How can we evade this issue? At the design stage, it is better to think about how likely it is to use this or that feature in other systems. The code that is expected to be reused is best to be placed in separate modules and classes.
Viscosity
There are two types:
- Development viscosity
- Environment viscosity
We can see development viscosity while trying to follow the selected application design. This may happen when a programmer needs to meet too many requirements while there is an easier way of the development. In addition, the development viscosity can be seen when the process of the assembly, deployment, and testing is not effective.
As a simple example, we can consider the work with constants that are to be placed (By Design) into a separate module (Module 1) to be used by other components (Module 2 and Module 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
}
If for any reason the assembly process takes much time, it will be difficult for developers to wait until it finishes. In addition, it should be noted that the constant module contains mixed entities that belong to different parts of business logic (financial and marketing modules). So, the constant module can be changed quite often for reasons that are independent of each other, which can lead to additional issues such as synchronization of the changes.
All this slows down the development process and can stress out programmers. The variants of the less viscous design would be either to create separate constant modules – by one for the corresponding module of business logic – or to pass constants to the right place without taking a separate module for them.
An example of the environment viscosity can be the development and testing of the application on the remote client virtual machine. Sometimes this workflow becomes unbearable due to a slow Internet connection, so the developer can systematically ignore the integration testing of the written code, which can eventually lead to bugs on the client side when using this feature.
Needless complexity
In this case, the design has actually unused functionality. This fact can complicate the support and maintenance of the program, as well as increase the development and testing time. For example, consider the program that requires reading some data from the database. To do this, the DataManager component was created, which is used in another component.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
}
If the developer adds a new method to DataManager to write data into the database (WriteData), which is unlikely to be used in future, then it will be a needless complexity as well.
Another example is an interface for all purposes. For example, we are going to consider an interface with the single Process method that accepts an object of the string type.
interface IProcessor
{
void Process(string message);
}
If the task was to process a certain type of message with a well-defined structure, then it would be easier to create a strictly typed interface, rather than to make developers deserialize this string into a particular message type each time.
To overuse design patterns in cases where this is not necessary at all can lead to viscosity design as well.
Why waste your time on writing a potentially unused code? Sometimes, QA are to test this code, because it is actually published and is open for use by third-party clients. This also puts off the release time. To include a feature for the future is worth only if its possible benefit exceeds costs for its development and testing.
Needless repetition
Perhaps, most developers have faced or will come across this feature, which consists in multiple copying the same logic or the code. The main threat is the vulnerability of this code while modifying it – by fixing something in one place, you may forget to do this in another one. In addition, it takes more time to make changes in comparison with the situation when the code does not contain this feature.
Needless repetition can be due to the negligence of developers, as well as of due to the rigidity/fragility of design when it is much more difficult and riskier not to repeat the code rather than to do this. However, in any case, repeatability is not a good idea, and it is necessary to constantly improve the code, passing reusable parts to common methods and classes.
Poor readability
You can monitor this feature when it is difficult to read a code and understand what it is created for. The reasons for poor readability can be non-compliance with the requirements for the code execution (syntax, variables, classes), a complicated implementation logic, etc.
Below you can find the example of the hard-to-read code, which implements the method with the Boolean variable.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
}
Here, we can outline several issues. Firstly, names of methods and variables do not conform to generally accepted conventions. Secondly, the implementation of the method is not the best.
Perhaps, it is worth taking a Boolean value, rather than a string. However, it is better to convert it to a Boolean value at the beginning of the method, rather than using the method of determining the length of the string.
Thirdly, the text of the exception does not correspond to the official style. Reading such texts, there can be a feeling that the code is created by an amateur (still, there may be a point at issue). The method could be rewritten as follows if it takes a Boolean value:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
}
Here is another example of refactoring if you still need to take a string:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
}
It is recommended to perform refactoring with the hard-to-read code, for example, when its maintenance and cloning lead to multiple bugs.
Fragility
Fragility of a program means that is can be easily crashed when being modified. There are two types of crashes: compilation errors and runtime errors. The first ones can be a back side of rigidity. The latter ones are the most dangerous as they occur on the client side. So, they are an indicator of the fragility.
No doubt, the indicator is relative. Someone fixes the code very carefully and a possibility of its crash is quite low, while others do this in a hurry and carelessly. Still, a different code with the same users may cause a different amount of errors. Probably, we can say that the more difficult it is to understand the code and to rely on the execution time of the program, rather than on the compilation stage, the more fragile the code is.
In addition, the functionality that is not going to be modified often crashes. It may suffer from the high coupling of the logic of different components.
Consider the particular example. Here the logic of user authorization with a certain role (defined as the rolled parameter) to access a particular resource (defined as the resourceUri) is located in the static method.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
}
As you can see, the logic is complicated. It is obvious that adding new roles and resources will easily break it. As a result, a certain role may get or lose access to a resource. Creating the Resource class that internally stores the resource identifier and the list of supported roles, as shown below, would reduce fragility.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
}
In this case, to add new resources and roles, it is not necessary to modify the authorization logic code at all, that is, there is actually nothing to break.
What can help catch runtime errors? The answer is manual, automatic and unit testing. The better the testing process is organized, the more probable is that the fragile code will occur on the client side.
Often, fragility is a back side of other identifiers of bad design such as rigidity, poor readability, and needless repetition.
Conclusion
We have tried to outline and describe the main identifiers of bad design. Some of them are interdependent. You need to understand that the issue of the design does not always inevitably lead to difficulties. It only points that they may occur. The less these identifiers are monitored, the lower this probability is.
Tags: design patterns, oop Last modified: September 23, 2021

