During numerous discussions about the applicability of the Repository pattern, I noticed that people are divided into two groups. In this article, I will call them abstractionists and concretists. The difference between them is in the way they treat the pattern value. The former believe that a repository is worthwhile, as it allows disregarding details of data storing. The latter suppose there is no way to disregard these details, therefore, the concept of repository makes no sense and its usage is a waste of time. The dispute between these two groups usually turns into a Holy War.
So, what is wrong with the repository? Obviously, everything is OK with the pattern, but the difference is in how developers understand it. I tried investigating this issue and stumbled upon two basic things that, in my opinion, are the reason of the dispute. One of them is a sliding responsibility of repository, and the other one is related to underrating of unit testing. I will describe the first one.
Sliding Responsibility of Repository
When it comes to designing architecture of an application, everybody thinks of three layers at first: Presentation Layer, Business Layer, and Data Layer (for more information, see MSDN). In such systems, objects of business logic use repositories for extracting data from physical storage. Repositories return business entities instead of raw record sets. Often, it is justified by the fact that if we need to change the type of the physical storage (database, file, or service), we need to create an abstract repository class and implement a specific class for the required storage. It looks in the following way:
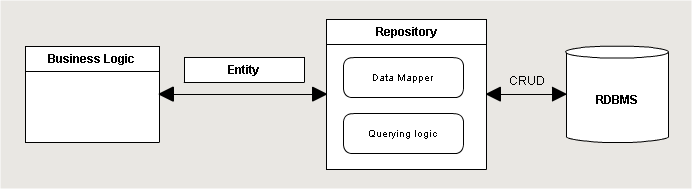
Descriptions of this division can be found in the article by Martin Fowler and in MSDN. As usual, description is just a simplified model. That is why, though it seems correct for a small project, the model is tricky when you try to transfer this pattern to a more complicated one. The existing ORM confuse even more since they implement many things out-of-the-box. But let’s imagine that a developer knows how to use Entity Framework (or other ORM) only for retrieving data. Where, for example, should it place the cache of the second level, or logging of all business operations? In the attempt to do this, it will try to divide modules by functionality in accordance with SPR from SOLID, and build a composition from them that may look as follows:
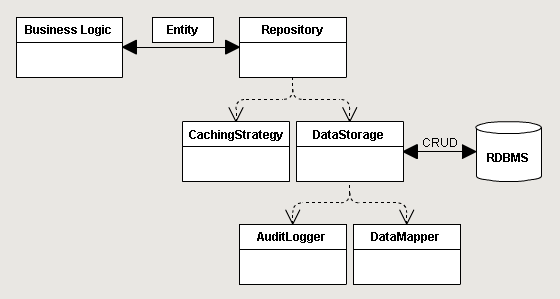
Does repository perform the same role as earlier? Obviously, the answer is ‘No’, since it does not extract data from a storage. This responsibility was passed to another object. And here we face the first discord between abstractionists and concretists.
Conclusion
If we presume that all terms must retain their values regardless of code modifications, it would be correct at the first stage not to call an object, that simply returns data, a repository. This is a genuine DAO pattern since its task is to hide a certain data access interface (ling, ADO.NET, or something else). At the same time, repository may not know of such peculiarities at all, and as a consequence, it assembles all data access subsystems into a single composition.
Do you agree that such problem exists?
Tags: .net, design patterns, entity framework Last modified: October 07, 2024




nope. those underlying access layers should be abstracted away such that it doesn’t really matter.
Don’t you think using such segregation you’re not correctly describe the purpose of the abstraction component? It’s too broad to say just “abstract” because it may be done by means of different approaches with different purposes. For example, a service class can abstract the way how data is construct to be used inside of the app layer, repository can abstract how data is retrieved, joined, access object can abstract the tech details of data retrieval. Although, for a small project where you have only web site and DB these segregation might be redundant.
I don’t see the problem. Why can’t we have logging and caching below the repo layer?
It depends on what exactly you’re assuming. When both are injected as separate services hiding all logging and caching details from repo it’s OK. If they are part of repo implementation then it’s not OK.