The database is a critical and vital part of any business or organization. The growing trends predict that 82% of enterprises expect the number of databases to increase over the next 12 months. A major challenge of every DBA is to discover how to tackle massive data growth, and this is going to be a most important goal. How can you increase database performance, lower costs, and eliminate downtime to give your users the best experience possible? Is data compression is an option? Let’s get started and see how some of the existing features can be useful to handle such situations.
In this article, we are going to learn how the data compression solution can help us optimize the data management solution. In this guide, we’ll cover the following topics:
- An overview of compression
- Benefits of compression
- An outline about data is compression techniques
- Discussion of various types of data compression
- Facts about data compression
- Implementation considerations
- and more…
Compression
The compression is a technique and, thus, a resource-sensitive operation, but with hardware trade-offs. One must think of deploying data compression for the following benefits:
- Effective space management
- Efficient cost reduction technique
- Ease of database backup management
- Effective N/W bandwidth utilization
- Safe and faster recovery or restoration
- Better performance – reduces the memory footprint of the system
Note: If SQL Server is CPU or memory constrained then compression might not suit your environment.
Data compression applies to:
- Heaps
- Clustered indexes
- Non-clustered indexes
- Partitions
- Indexed views
Note: Large objects are not compressed (For example, LOB and BLOB)
Best suited for the following applications:
- Log tables
- Audit tables
- Fact tables
- Reporting
Introduction
Data compression is a technology that’s been around since SQL Server 2008. The idea of data compression is that you can selectively choose tables, indexes, or partitions within a database. I/O continues to be a bottleneck in moving information between in-and-out of the database. Data compression takes advantage of this type and helps to increase the efficiency of a database. As we know that the network speeds are so much slower than processing speed, it’s possible to find efficiency gains by using the processing power to compress data in a database, so that it travels faster. And then use processing power again, to uncompress the data on the other end. In general, data compression reduces the space occupied by the data. The technique of data compression is available for every database and it’s supported by all the editions of SQL Server 2016 SP1. Prior to this, it was only available on SQL Server Enterprise or Developer editions, not on Standard or Express.
Feature Support
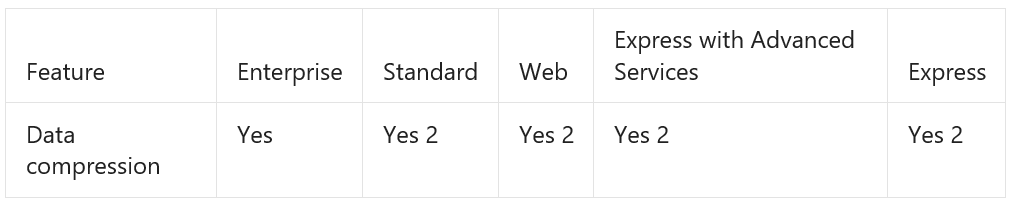
Data compression types
There are two types of data compression available within SQL Server, row-level and page-level.
The row-level compression works behind the scenes and converts any fixed length data types into variable length types. The assumption here is that often data is stored at a fixed length type, such as char 100, and they don’t actually fill the entire 100 characters for every record. Small gains can be achieved by removing this extra space from the table. Of course, if your data tables don’t use fixed length text and numeric fields, or if they do and you actually store the fully allowable number of characters and digits, then the compression gains under the row-level scheme are going to be minimal at best.
The concept of compression is extended to all fixed-length data types, including char, int, and float. SQL Server allows saving space by storing the data like it was a variable sized type; the data will appear and behave like a fixed length.
For example, if you stored the value of 100 in an int column, the SQL Server needn’t use all 32 bits, instead, it simply uses 8 bits (1 byte).
Page level compression takes things to another level. First, it automatically applies row-level compression on fixed length data fields, so you automatically get those gains by default. Then on top of that, it applies something called prefix compression, and another technique called dictionary compression.
Row Compression
Row compression is an inner level of compression that stores the fixed character strings by using variable-length format by not storing the blank characters. The following steps are performed in the row-level compression.
- All numeric data types like int, float, decimal, and money are converted into variable length data types. For example, 125 stored in column and data type of the column is an integer. Then we know that 4 bytes are used to store the integer value. But 125 can be stored in 1 byte because 1 byte can store values from 0 to 255. So, 125 can be stored as a tiny int, such that 3 bytes can be saved.
- Char and Nchar data types are stored as variable length data types. For example, “SQL” is stored in a char(20) type column. But after compression, only 3 bytes will use. After the data compression, no blank character is stored with this type of data.
- The metadata of the record is reduced.
- NULL and 0 values are optimized and no space is consumed.
Page Compression
Page compression is an advanced level of data compression. By default, a page compression also implements the row level compression. Page compression is categorized into two types
- Prefix compression and
- Dictionary compression.
Prefix Compression
In prefix compression for each page, for each column in the page, a common value is retrieved from all rows and stored below the header in each column. Now in each row, a reference to that value is stored instead of common value.
Dictionary Compression
Dictionary compression is similar to prefix compression but common values are retrieved from all columns and stored in the second row after the header. Dictionary compression looks for exact value matches across all the columns and rows on each page.
We can perform row and page level compression for following database objects.
- A table stored in a heap.
- A whole table stored as a clustered index.
- Indexed view.
- Non-clustered index.
- Partitioned indexes and tables.
Note: We can perform data compression either at the time of creation like CREATE TABLE, CREATE INDEX or after the creation using ALTER command with REBUILD option like ALTER TABLE …. REBUILD WITH.
Demo
The WideWorldImporters database is used through the entire demo. Also, a real-time DW database is considered for the compression operation.
Let us walk-through the steps in detail:
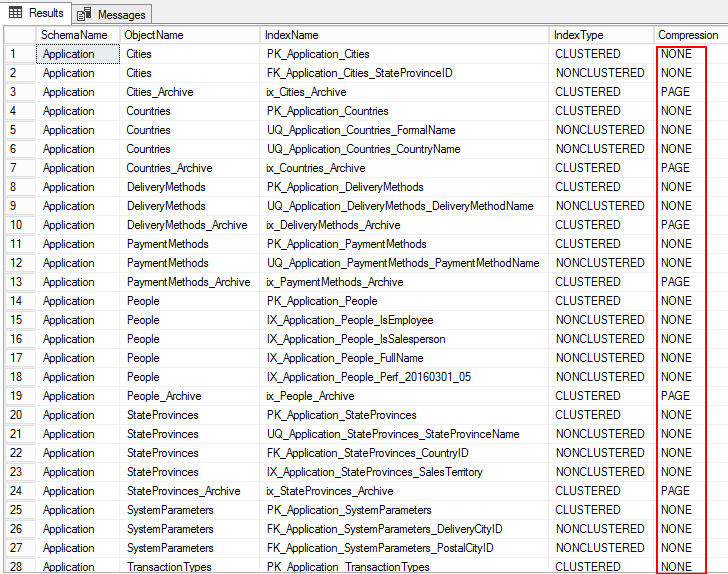
1. To view compression settings for objects in the database, run the following T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
The following output shows the compression type as PAGE, ROW, and for several tables it’s NONE. This means that it is not configured for compression.
2. To estimate compression, run the following system stored procedure sp_estimate_data_compression_savings. In this case, the stored procedure is executed on the PurchaseOrderLines tables.
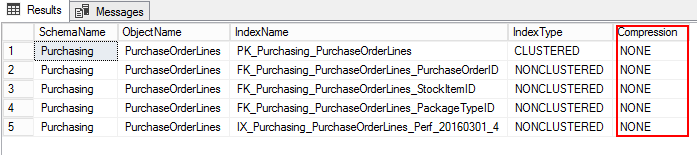
3. Let us find out the PurchaseOrderLines compression setting by running the following T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

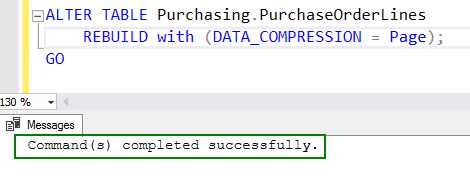
4. Enable compression by running the ALTER table command:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
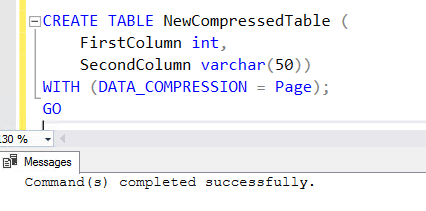
5. To create a new table with the compression enabled feature, add the WITH clause at the end of CREATE TABLE statement. You can see the below CREATE TABLE statement used to create NewCompressedTable.
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Data Compression Facts
Let us walk through some of the actual information about compression
- Compression cannot be applied to system tables
- A table cannot be enabled for compression when the row size exceeds 8060 bytes.
- Compressed data is cached in the buffer pool; it means faster response times
- Enabling compression can cause query plans to change because the data is stored using a different number of pages and number of rows per page.
- Non-clustered indexes do not inherit compression property
- When a clustered index is created on a heap, the clustered index inherits the compression state of the heap unless an alternative compression state is specified.
- The ROW and PAGE level compressions can be enabled and disabled, offline or online.
- If the heap setting is changed, then all non-clustered indexes are to be rebuilt.
- The disk space requirements for enabling or disabling the row or page compression are the same as for creating or rebuilding an index.
- When partitions are split by using the ALTER PARTITION statement, both partitions inherit the data compression attribute of the original partition.
- When two partitions are merged, the resultant partition inherits the data compression attribute of the destination partition.
- To switch a partition, the data compression property of the partition must match the compression property of the table.
- Columnstore tables and indexes are always stored with the Columnstore compression.
- Data compression is incompatible with sparse columns so the table can’t be compressed.
Real-time scenario
Let us walk-through the data compression technique and understand the key parameters of data compression.
To check the space used by each table, run the following T-SQL. The output of the query gives us detailed information about the usage of each table. This would be the decisive factor for the implementation of the data compression.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
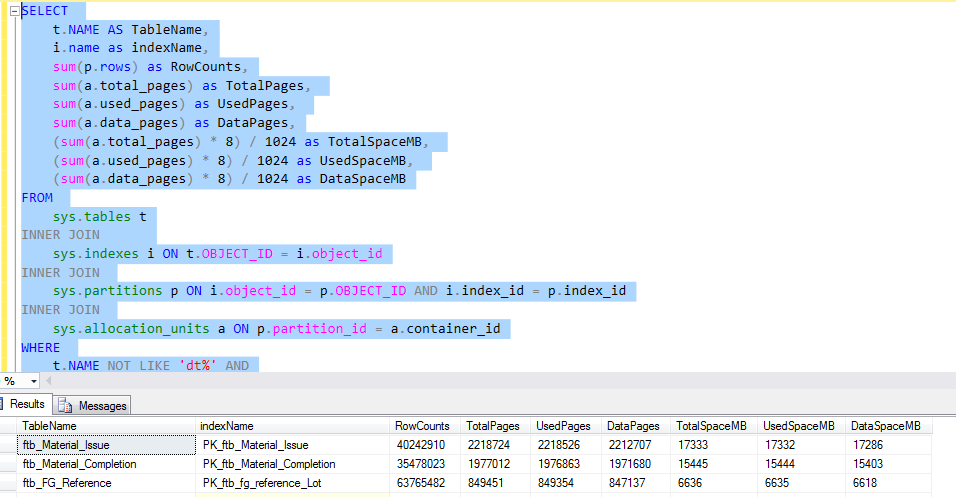
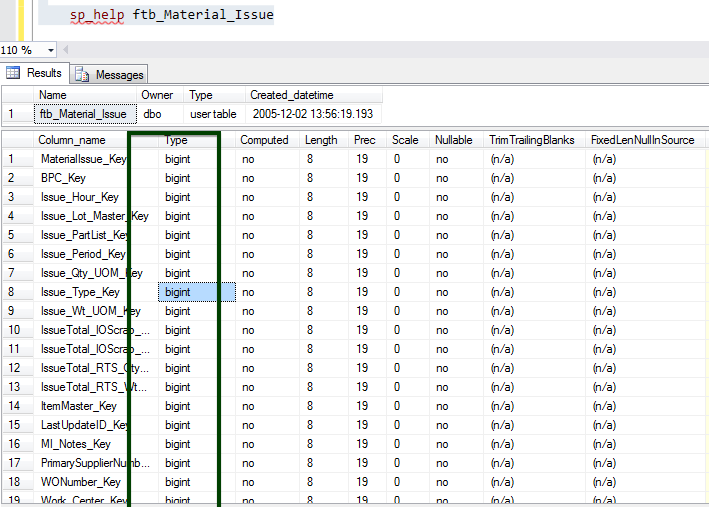
Let us consider the ftb_material_Issue fact table. The fact table has numeric BIGINT data types.
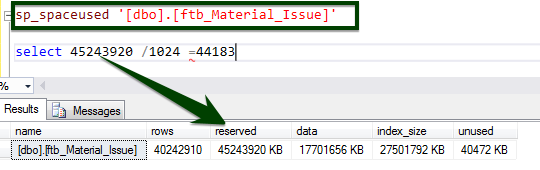
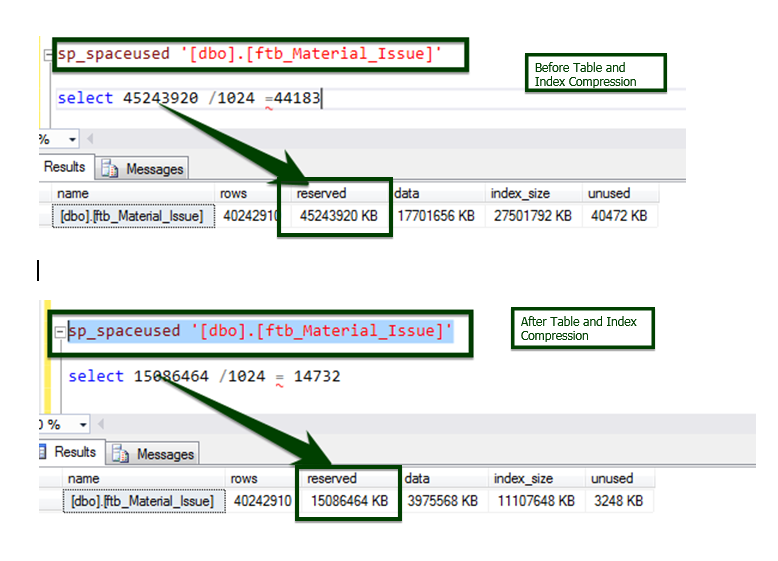
Now, run the sp_spaceused stored procedure to understand the details of the table. You can learn more about the sp_spaceused command here.
Enable the table-level compression by running the following T-SQL. The following T-SQL was executed on the server and it took 34 minutes 14 seconds to compress the page at the table-level.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
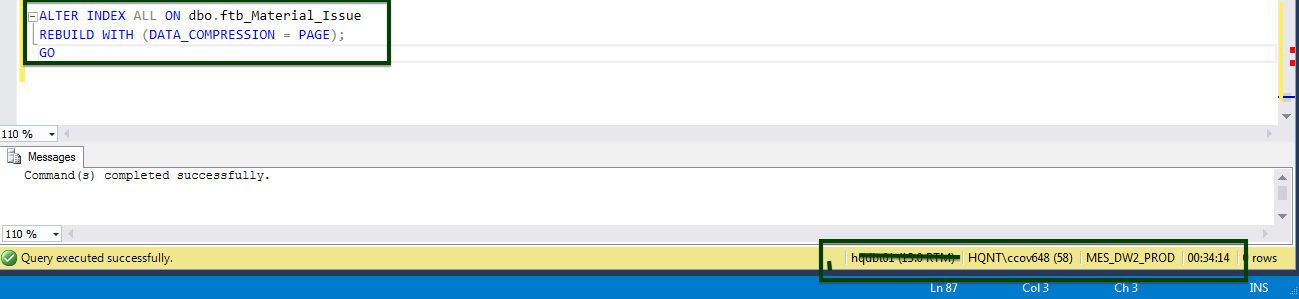
You can see the CPU and I/O fluctuations during the execution of the ALTER table command.
Now, let’s do the Before v/s After data compression comparison. The table size about ~45 GB is brought down to ~15 GB.
The process is implemented on most of the objects using an automated script and here is the final result of the comparison.
Data comparison between Before and After the index compression operation.

Summary
Data compression is a very effective technique to reduce the size of data; reduced data requires less I/O processes. Adding compression to the database increases the load on CPU requirements. You’ll need to ensure that you have the available processing capacity to accommodate these changes in an efficient manner. So it’s better to do a little research first and see the types of gains that can be expected before applying the modifications to enable data compression. It’s very much beneficial in the cloud database setup where cost is involved.
Stage the compressions (don’t do them all at once) and compress during low-activity time periods. Data compression and backup compression co-exist nicely and can result in additional storage space savings, so go ahead and indulge.
Not only does compression reduce physical file sizes, but it also reduces disk I/O, which can greatly enhance the performance of many database applications, along with database backups.
Deciding to implement compression is easier if we know the underlying infrastructure and business requirements. We can definitely use the available system procedure to understand and estimate compression savings. This stored procedure does not provide any such details which tell you how the compression will positively or negatively affect your system. It is evident that there are trade-offs to any sort of compression. If you have the same patterns of huge data, then compression is the key to saving space. With CPU power growing and every system bound to multiple-core structures, compression may fit for many systems. I would recommend testing your systems. Test to ensure that performance is not negatively impacted. If an index has lots of updates and deletes, the CPU cost to compress and decompress the data might outweigh the I/O and RAM savings from data compression. Not every database or table will automatically be a good candidate to apply compression to, so it’s best to do a little research first to see the kinds of gains that can be expected before applying the modifications to enable data compression on your databases. You need to test compression to see if it works well in your environment, because it may not work well in heavy-insert databases.
References
Editions and supported features of SQL Server 2016
Row Compression Implementation
Page Compression Implementation
Tags: database administration, performance, sql server Last modified: September 22, 2021






