
Understanding Spark SQL is extremely helpful for analyzing big data, especially when you’re working with the Spark platform. But what exactly is Spark SQL? What are spark data frames? How can you learn using it?
Let’s take a look at its functions, capabilities, and, more importantly, the results it can provide for you.
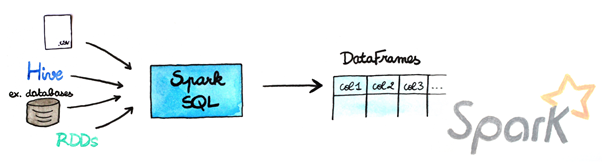
Table of contents
- What is Spark SQL?
- Advantages of Spark for Specific Purposes
- How to use Spark SQL
- Examples of Using Spark SQL
- How to Learn and Practice Spark SQL
- Conclusion
What is Spark SQL?
Apache Spark is a programming framework that simplifies the creation of data-processing applications. It provides libraries in Java and Scala to write programs using either batch or streaming techniques. It also offers libraries in R, Python, and SQL. Therefore, users can write code to apply these tools with their datasets without the need to know any Scala or Java – just use some helpful Apache Spark tutorials.
Spark SQL is the name given to Spark’s in-memory analytics and data warehousing solution (formerly known as Apache Hive).
Spark SQL supports relational, structured, semi-structured, and unstructured data, making it easy to run SQL queries on them. Also, it supports native machine learning and graph processing capabilities that allow you to explore data deeper with traditional tools like Hive or Hadoop MapReduce.

Being one of Apache’s components, Spark SQL allows users to manipulate structured data with the programming model provided by Scala, Java, or Python APIs. One can write queries using various data sources, including tables in Hive or external databases via JDBC/ODBC connections.
Advantages of Spark for Specific Purposes
Spark SQL is an extension of the Scala programming language that allows for writing SQL queries directly against Spark datasets, including data sets in HDFS or Spark’s native file format. Thus, it is possible to use the scalability and fault-tolerance advantages of Spark with the flexibility and convenience of SQL.
Spark SQL for Speed and Scalability
Spark SQL is a powerful tool for processing structured datasets – a framework allowing the developers to write applications with standard SQL. You can query and interact with data stored in HDFS and HBase as well as columnar stores, such as Apache Parquet, Apache ORC, and Amazon S3.
Spark can run across multiple machines or clusters for increased efficiency. A large number of organizations start to use Spark after implementing it successfully at scale for machine learning-based initiatives. Spark has become so successful in areas like data analytics because speed and scalability are paramount here.
Let’s take such features as external storage support. This brings another level of flexibility to Spark since you can integrate external storage systems like Amazon S3 to access unstructured datasets.
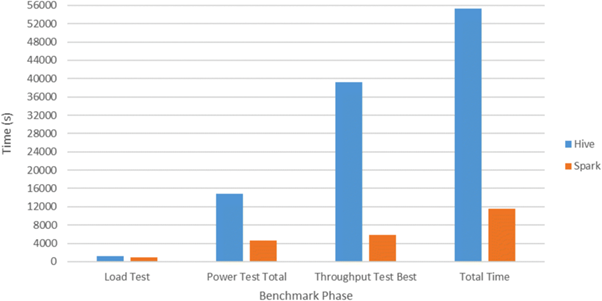
The other side is faster analysis due to complex computations that occur on less complex columnar data, especially if you want to join two datasets with wide tables versus narrow ones. To give you an idea about just how fast these things are, importing 250 GB of CSV files into Spark takes mere minutes! It is 5x faster than Hive running on MapReduce through internal benchmarks.
Frequent Itemsets
For datasets with sequential or transactional features, finding frequent itemsets is important in business-intelligence analyses. Assume that you’re analyzing customer purchasing habits. There is a great chance you’ll find related items that are frequently purchased together, i.e., bread and butter, carrot and celery sticks, etc. Finding these relationships can help you identify high-value products to stock in your store.
After a dataset is ingested into Spark SQL, it can be analyzed using a broad range of built-in and third-party tools, such as graph algorithms and machine learning models. As Spark supports Apache Arrow for data in-memory processing, Spark users do not need to keep all their data in memory. Moreover, Spark allows users to query RDDs from anywhere within an application without materializing them into memory. Thus, even graph algorithms that require large amounts of memory for execution become practical. Only a small fraction of their overall computation is done in memory.
These features come together to enable applications based on finding frequent itemsets. It is something that would have been very difficult or impossible using a traditional relational columnar database model or MapReduce jobs.
Sensitivity Analysis
As you analyze data from multiple sources, you may find that certain factors impact your results more than others. To predict better how your project may be affected by changes in circumstances, conduct a sensitivity analysis.
This analysis entails altering each factor individually and seeing how it impacts your final model. Since it’s quantitative, you can use a specific methodology to determine which factors are more important. For example, if you analyze sales data and want to see how competitor prices, inventory level, age of inventory, and seasonality variables (holidays, weather events, etc.) affect your revenue, you can experiment with those factors as independent variables and revenue as a dependent variable. Thus, you determine which elements have a significant effect on sales.
Sensitivity analysis is critical when you’re working with data. If your goal is to make good decisions, you need to understand what affects them, based on your input. It can be time-consuming, but it is essential to conduct sensitivity analysis at each stage of any project when decision-making comes into play.
Summing up, the Spark SQL sensitivity analysis refers to evaluating how the output from an algorithm will vary as inputs change. In practice, you can use it to determine the sensitivity of the result set to data changes. Also, you can figure out which data points impact your results most of all.
Don’t forget to run sensitivity analysis in Spark SQL using the relabel API and cross-validation metrics. This way, you can correctly interpret your results before pushing them into production.
How to use Spark SQL
Spark SQL is a Spark component that provides structured data processing capabilities. It enables users to query structured and semi-structured data in HDFS, Apache Parquet files, JSON, Hive tables, and more.
Spark SQL also enables distributed joins across datasets residing in different clusters or on different machines. This functionality grants you efficient exploratory analytics with external data sources. You can apply it to machine learning frameworks (such as MLlib) and build predictive models.
If you need a Spark SQL tutorial, watch one to grasp the idea.
For advanced users, using Spark SQL helps load data from various sources, filter it, combine it with other datasets, transform it using user-defined functions, and save to any target supported by Spark, all in a standard Scala or Java interface.
With Spark SQL, you can easily run interactive queries on large datasets distributed across clusters of computers. Spark can run interactively inside a web browser or programmatically via API calls to Scala, Java, Python, or R high-level language code. There are also libraries available for working with big data files stored on a disk.
Structurally, Spark’s SQL layer, commonly called Spark SQL, provides a data abstraction called DataFrames that integrates RDD-based operations and relational database operations on top of Spark Core.
DataFrames will let the users work with structured and semi-structured data as if it were in a traditional RDBMS system, like Oracle or MySQL. They simplify access to distributed datasets through their familiarity as objects, instead of forcing you to deal with low-level APIs, such as those used by map/reduce languages like Cascading and Scalding.
Examples of Using Spark SQL
Spark SQL allows you to run queries across multiple data sources. Imagine you are a university professor and want to award a stipend to students who achieved more than 90% in exam scores. The classical way (right-clicking a file in Windows and viewing Properties) would be time-consuming! You could get stuck in that process for months.
But SQL now allows you to retrieve data from large databases, and Spark SQL makes it even more convenient. You might have a huge table of student data, including their name, age, exam results, email, etc. With SQL, you can quickly and easily extract all names of students whose results were above 90% into a separate table.
The more you learn about SQL, the more opportunities it presents. While surface-level methods may save you tons of time and energy, more in-depth solutions are crucial, especially for large companies. For example, monitoring employees’ KPI and improving sales can have a mastodon impact on revenue.
If you’re are not a company but an enthusiast, chances are you’re not coding for fun and are looking to get a job in the sphere. Spark SQL has been called “a Big Data Engineer’s most important tool” for a reason.
It’s easy to start using Spark SQL. Queries are in SQL that is an industry-standard language. It opens up Spark to thousands of expert data scientists familiar with MySQL, PostgreSQL, or other open-source databases that use SQL as their query language.
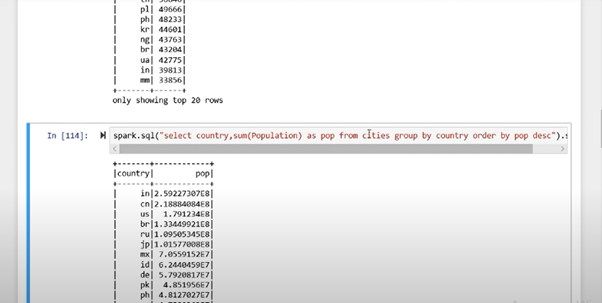
This is what Spark looks like:

In this example, we’re selecting entries that satisfy our criteria by commands (in purple). We are telling Spark to SELECT from a storage space CITIES certain COUNTRIES where POPULATION matches our demands:
The best features of Spark
- Failsafe
- Doesn’t excessively consume resources
- Scalable
- Flexible
- Using cluster calculations in memory (Spark RDD) that increase processing speed (up to 10 times faster disk operations)
- Supports multiple languages
- Extended analytics: except Map/Reduce, it supports SQL requests, machine learning, Graph algorithms, and more.
Iteration operations using Spark RDD

Spark SQL Functions: Did you Say Faster?
Spark is remarkably fast due to multiple factors, all of which fall under the umbrella of intelligent organization.
You may consider Spark SQL a more powerful alternative to MapReduce. While MapReduce handles batch processing by reading large chunks of data from disk into memory before doing anything, Spark handles each operation with only enough material that fits into memory at one time, allowing faster processing of larger datasets.
The functionality that allows Spark to read data from multiple sources, cost-based optimizer, code generation, and columnar storage allow Spark to be extra optimized and extra speedy.

Also, here’s another comparison:
How to Learn and Practice Spark SQL
In this example, we’re using data about various countries in our warehouse to arrange countries according to their populations (descending). We’re trying to figure out which parts of these countries’ populations reside in areas other than cities. To accomplish that, we have to manipulate data from different tables.
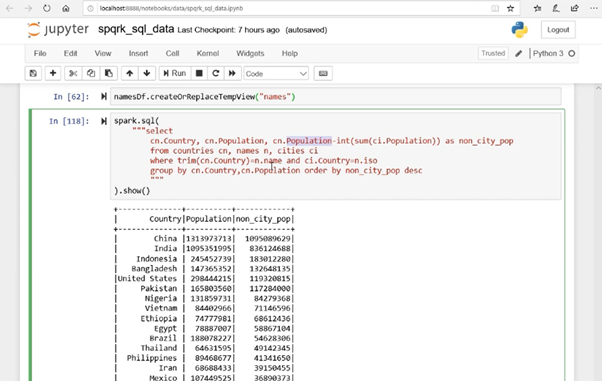
You may be that you’re new to coding. But even so, you can figure out what the code is telling the program to do by reading it. You can see the stuff you don’t know you can look up and figure out. Before you know it, you’ll be writing your programs. And then there’s no limit to what you can do!
Retrieve the vacancies from the whole world of job boards and pick the best possible job? Done. Or, maybe, create the next Bitcoin? Probably, it will take some work, but also possible. If Satoshi Nakamoto did it, so can you!
Conclusion
Apache Spark runs your applications tremendously fast. It accomplishes the goal by reducing the read and write operations and caching data in memory even when doing numerous parallel operations. It gives you lots of possibilities to manipulate the data and create robust and powerful apps.
Imagine how much you could do with the help of one of the most efficient data retrieval tools on the Web! IF information is money, THEN a tool that helps you get it could make you very powerful. Fortunately,
Tags: framework, sql Last modified: March 31, 2023







