Introduction
You must have already heard the term “Collation” in SQL Server. Collation is a configuration that determines how character data sorting is done. This is an important setting that has a huge impact on how the SQL Server database engine behaves in dealing with character data. In this article, we aim to discuss collations in general and show a few examples of dealing with collations.
Where do I find collations?
You can find SQL collation at the server, database and column level. Another important thing to know is that the collation setting need not be the same at the server, database and column level. Also, you can update your queries to use specific collations. It is at this time that you will realize the importance of configuring the correct collation across your environment as there is a high possibility of unexpected issues if the collation is not consistent.
What are the different types of collations available?
You can get the full list of available collations by querying the system function sys.fn_helpcollations()
select * from sys.fn_helpcollations()
This will return the following output.
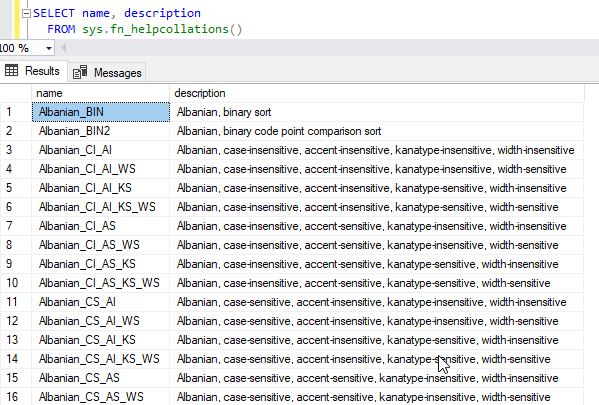
If you are looking for specific collations by language, you can filter the name further. For example, if you are looking for the Maori language supported collation, you can use the following query.
select * from sys.fn_helpcollations()
where name like '%Maori%'
This will return the following output.
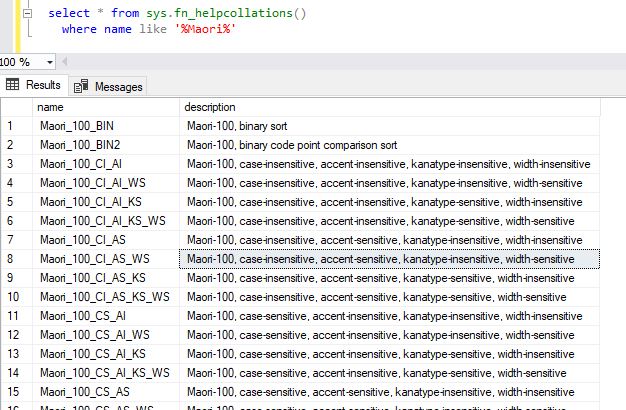
This way you can check for the supported collations for the collation of your choice. On just querying the fn_helpcollations() system function, 5508 rows in total were returned meaning there are that many supported collations. Note, that this covers a majority of the languages around the world.
What are the different options you see in the collation name?
For example, in this collation: Maori_100_CS_AI_KS_WS_SC_UTF8, you can see the various options in the collation name.
![]()
CS – case-sensitive
AI – accent-insensitive
KS – kana type-sensitive
WS – width-sensitive
SC – supplementary characters
UTF8 – Encoding standard
Based on the type of a collation option selected, the SQL Server database engine will be performing differently in dealing with character data for sorting and searching operations. For example, if you use the case-sensitive option in the SQL collation, the database engine will be behaving differently for a query operation looking for “Adam” or “adam”. Assuming you have a table called “sample” and there is a firstname column with a user “adam”. The query below will return no results if there is no row with a firstname “Adam”. This is because of the “CS-Case sensitive” option in the collation.
select * from sample
where firstname like '%Adam%'
With this simple example, you can understand the significance of choosing the correct SQL collation option. Make sure you understand the application requirements before selecting collation in the first place.
Finding collation on SQL Server instance
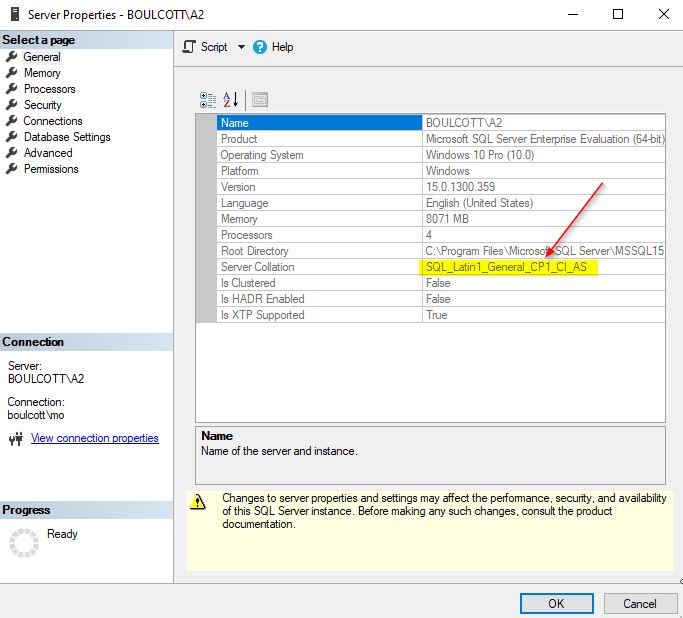
You can get the server collation in SQL Server Management Studio (SSMS) by right-clicking the SQL instance, then clicking the “Properties” option and checking the “General” tab. This collation is selected by default at the installation of SQL Server.
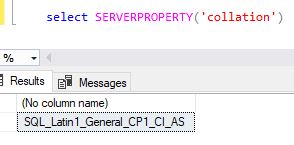
Alternatively, you can use the serverproperty option to find the collation value.
select SERVERPROPERTY('collation'),
Finding collation of a SQL database
In SSMS, right-click the SQL database and go to the “Properties”. You can check the collation details in the “General” tab as shown below.
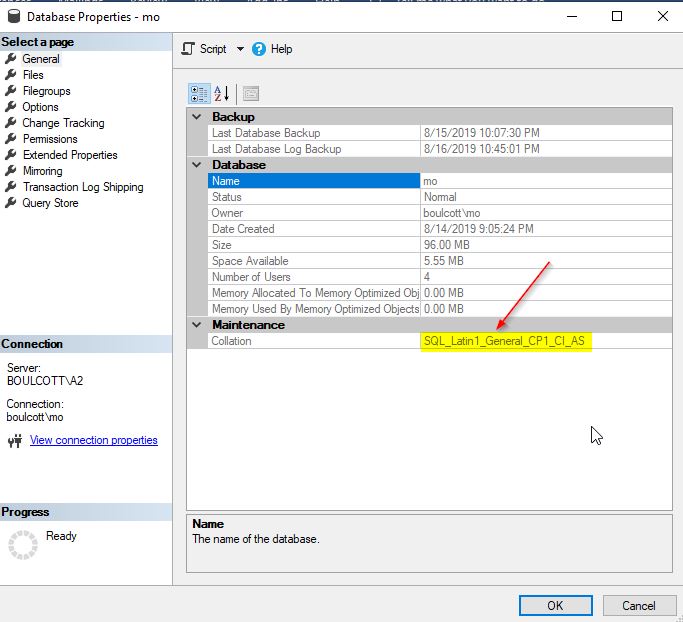
Alternatively, you can use the databasepropertyex function to get the details of a database collation.
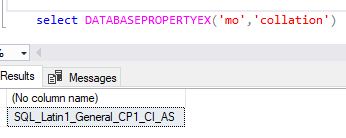
select DATABASEPROPERTYEX('Your DB Name','collation')
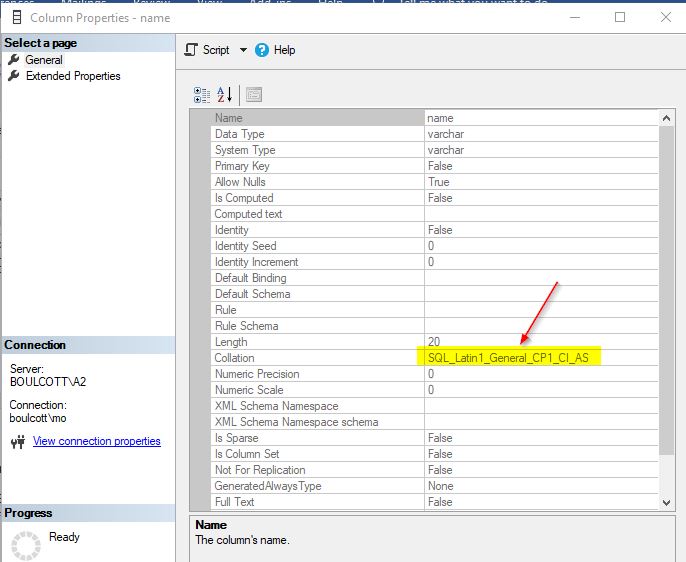
Finding collation of a column in a table
In SSMS, go to the table, then columns, and finally right-click the individual columns to view the “Properties”. If the column is of a character data type, you will see details of the collation.
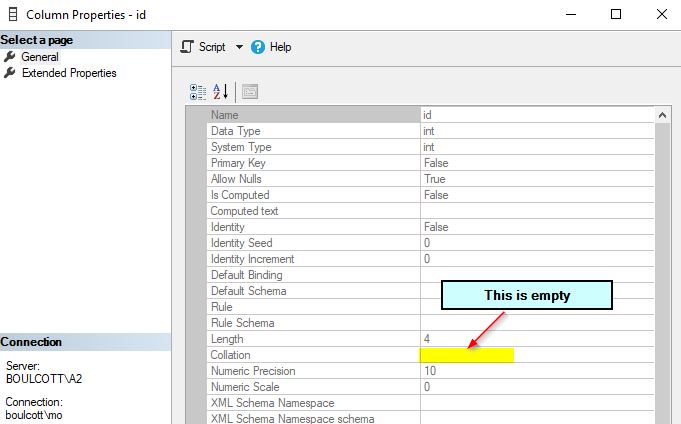
However, at the same time, if you check the value for a non-character data type, the collation value will be null. Below is a screenshot of a column that has int data type.
Alternatively, you can use a sample query below to view the collation values for columns.
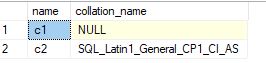
select sc.name, sc.collation_name from sys.columns sc inner join sys.tables t on sc.object_id=t.object_id where t.name='t1' – enter your table name
Below is the output for the query.
Trying out different collations in SQL queries
In this section, we will see how the sort order gets impacted when different collations are used in queries. A sample table is created with 2 columns as shown below.
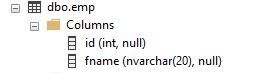
The fname column has the default collation of the database it belongs to. In this case, the collation is SQL_Latin1_General_CP1_CI_AS.
To insert a few records in the table, use a query below. Assign your own values to the parameters.
insert into emp values (1,'mohammed') insert into emp values (2,'moinudheen') insert into emp values (3,'Mohammed') insert into emp values (4,'Moinudheen') insert into emp values (5,'MOHAMMED') insert into emp values (6,'MOINUDHEEN')
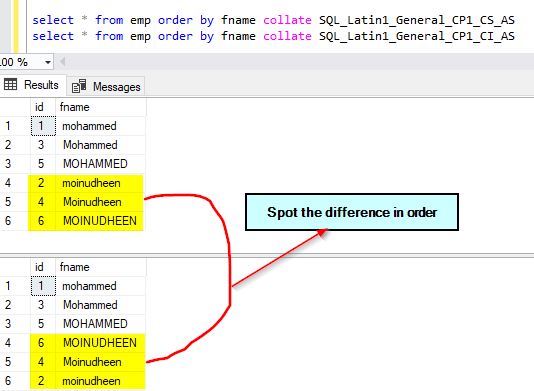
Now, query the emp table and sort it by the fname column using different collations. We will use the default collation of the column for sorting as well another case sensitive collation – SQL_Latin1_General_CP1_CS_AS.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – this is default
The output for these queries is given below. Notice the difference in collation used. We are using case sensitive instead of case insensitive.
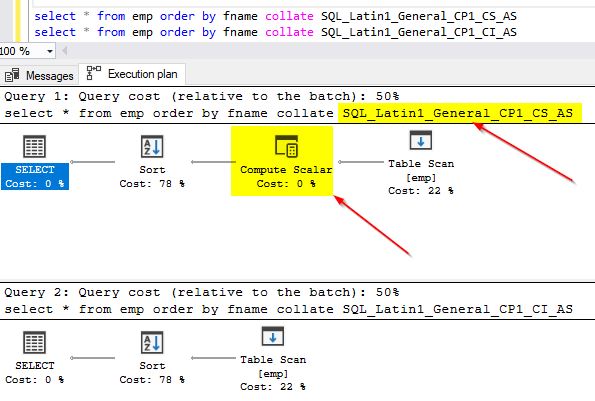
You can also check the query plans for both of these queries to spot the difference. On the first query plan where we use a different collation than the one in the column, you can notice the additional “Compute Scalar” operator.
When you hover the mouse over the “Compute Scalar” operator, you will see the additional details as shown below. This is due to the implicit conversion that is taking place as we are using a different collation from the default one used in the column.
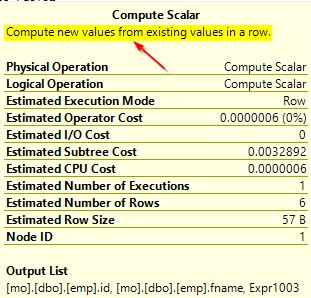
With this small example, you can see the kind of impact on query performance when you use collations explicitly in queries. In our demo database, we used a simple table but imagine a real-time scenario where small changes in query performance can cause unexpected results.
Checking if it is possible to change collation at the instance level
In this section, we will review different scenarios where we may have to change the default collations. You may encounter situations, when servers or databases get handed over to you and they may not be meeting your standard policies, so you may need to change the collation. The default SQL Server collation is SQL_Latin1_General_CP1_CI_AS. Changing the collation at the SQL instance level is not straight forward. It requires scripting out all the objects in the user databases, exporting the data, dropping the user databases, rebuilding the master database with the new collation, creating the user databases and then importing all the data. So, if you are installing new SQL instances, just make sure you get the collation right the first time, otherwise, you may have to do a lot of unwanted work later on. Explaining in detail the stages for changing collation at the instance level is beyond the scope of this article due to the detailed steps required for each of the stages.
Changing collation at the database level
Luckily, changing the database level collation is not as hard as changing the instance collation. We can update the collation using both SSMS and T-SQL. In SSMS, just right-click the database, go to “Properties” and click the “Options” tab on the left side. There, you can view the option to change the collation in the drop-down menu.
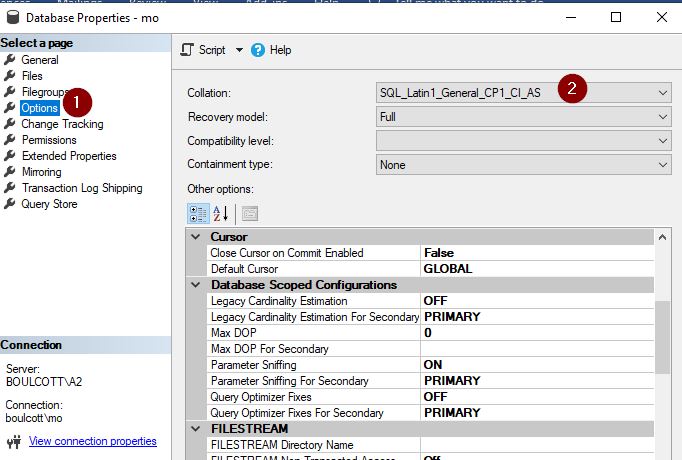
Click “OK” once done. I’ve just changed the database collation to SQL_Latin1_General_CP1_CI_AS. Just make sure, you perform this operation when the database is not in use as the operation will fail otherwise as shown below.
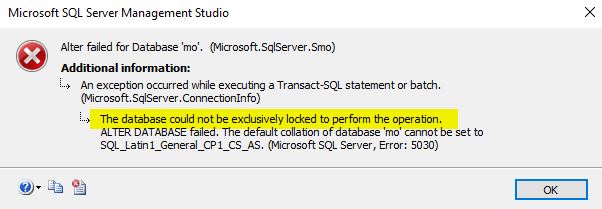
Use the proceeding query in order to change the database collation using T-SQL.
USE master; GO ALTER DATABASE mo COLLATE SQL_Latin1_General_CP1_CS_AS; GO
You would notice that changing the database level collation will not impact the collation of the existing columns in the tables. You can use the earlier examples to check the impact of collation on the sort order for the queries below.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – - this is default
The fname column collation will remain the original one and will stay unchanged even after changing the database level collation.
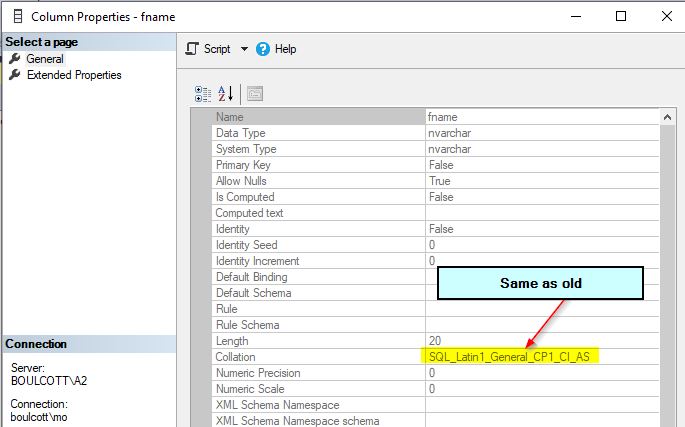
However, the new database level collation will be applied for all new columns in the new tables that you will create. So, always test the changing of database collations thoroughly as it has a considerable impact on queries output or behavior.
Changing collation at the column level
In the previous section, you noticed that even after changing the database level collation, the collation of the existing columns in the tables remains unchanged. In this section, we will see how we can change the collation of the existing columns in the tables to match that of the database collation. In the previous section, you changed the database collation to SQL_Latin1_General_CP1_CS_AS. Next, you want to identify all the columns in the user tables that do not match this database collation. You may use this script for identifying those columns.
select so.name TableName,sc.name ColumnName, sc.collation_name CollationName from sys.objects so inner join sys.columns sc on so.object_id=sc.object_id where sc.collation_name!='SQL_Latin1_General_CP1_CS_AS' and so.[type] ='U'
The sample output from my demo database is as shown below.
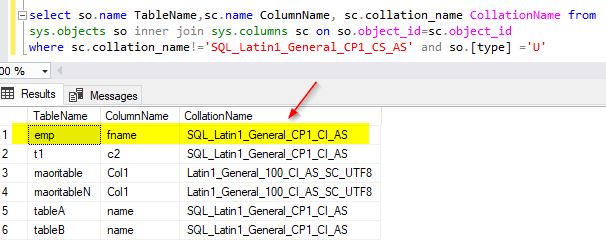
Suppose you want to change the collation of the existing fname column to “SQL_Latin1_General_CP1_CS_AS”, then you may use this alter script below.
use mo
go
ALTER TABLE dbo.emp ALTER COLUMN fname
nvarchar(20) COLLATE SQL_Latin1_General_CP1_CS_AS NULL;
GO
If you use the earlier examples where you checked the query performance using different collations, you will notice that the “compute scalar” operator is not used when we use the same collation as that of the database. Refer to the screenshot below. In the earlier example, you could have noticed the “Compute scalar” operator being used in the first execution plan. As we changed the column collation to match that of the database collation, there is no need for implicit conversion. You will see the “Compute scalar” operator in the second query as it uses a different collation explicitly.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS – - this is default select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS
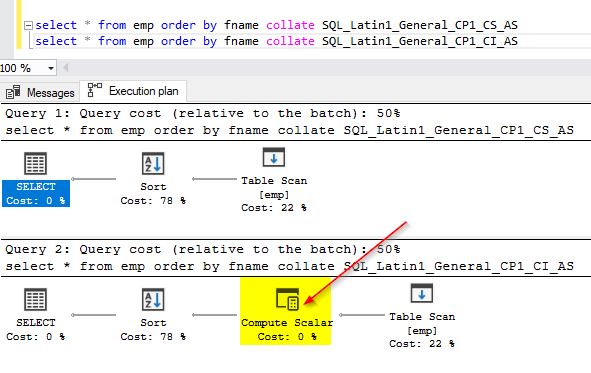
Can we change the collation of system databases?
Changing the collation of system databases is not possible. If you try to change the collation of the system databases – master, model, msdb or tempdb, you will get this error message.
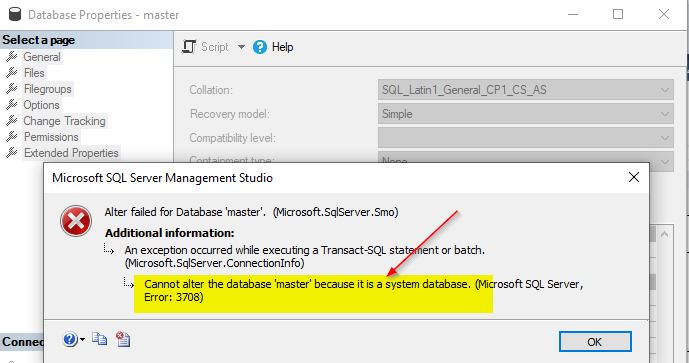
You will need to follow the steps outlined earlier on changing the collation at the SQL Server instance level in order to change the collation of the system databases. It is important to get the collations correct first time you install SQL Server to avoid such issues.
The known issue about collation conflict
Another common issue you may find is the error related to collation conflict especially while using temporary objects. The temporary objects are stored in the tempdb. The tempdb being a system database will assume the collation of the SQL instance. When you create user databases that have collation other than that of the SQL instance, you will run into issues when using temporary objects. You may also face issues while comparing columns in tables that have different collations. By now, you already know that a table can have columns with different collations as we cannot change the collation at the table level. The common error message you will notice is something like “Cannot resolve the collation conflict between “Collation1” and “Collation2” in the equal to operation.” Collation1 and Collation2 can be any collation used in a query. Using a simple example, we can produce a demo of this collation conflict. If you’ve completed the previous examples in this article, you will already have a table named “emp”. Just create a temporary table in your demo database and insert records using the sample script provided.
create table #emptemp (id int, fname nvarchar(20)) insert into #emptemp select * from emp
Just run a join using both tables and you will get this collation conflict error as shown below.
select e.id, et.fname from emp e inner join #emptemp et on e.fname=et.fname

You will notice that the user database collation used is “SQL_Latin1_General_CP1_CS_AS” and it doesn’t match to that of the server collation. In order to fix this type of error, you can alter the columns that are used in the temporary objects to use the default collation of the user database. You can use the “database_default” option or explicitly provide the collation name of the user database. In this example, we use the collation “SQL_Latin1_General_CP1_CS_AS”. Try one of these options
Option 1: Use the database_default option
alter table #emptemp alter column fname nvarchar(20) collate database_default
Once done, run the select statement again and the error will be fixed.
Option 2: Use the collation of the user database explicitly
alter table #emptemp alter column fname nvarchar(20) collate SQL_Latin1_General_CP1_CS_AS
Once done, run the select statement again and the error will be fixed.
Conclusion
In this article, you found about:
• the concept of collation
• the different collation options available
• finding collation details for any SQL instance, database, and column
• A WORKING EXAMPLE on trying out collation options in SQL queries
• changing collations at the instance level, database level, and column level
• HOW TO change collations of system databases
• a collation conflict and how to fix it
Now you know about the importance of collation and the criticality of configuring the correct collation on the SQL instance and also across the database objects. Always test the various scenarios on your test environment before applying any of the above options on your production systems.
Tags: sql, sql server, SQL Server collation Last modified: October 23, 2024






[…] to a case-sensitive one within REPLACE, what will happen? Here’s the code using COLLATE within […]