The ROLLUP and CUBE operators are used to return results aggregated by the columns in the GROUP BY clause.
The GROUPING and GROUPING_ID functions are used to identify whether the columns in the GROUP BY list are aggregated (using the ROLLUP or CUBE operators) or not.
There are two major differences between the GROUPING and GROUPING_ID Functions.
They are as follows:
- The GROUPING function is applicable on a single column, whereas the column list for the GROUPING_ID function has to match the column list in the GROUP BY clause.
- The GROUPING function indicates whether a column in the GROUP BY list is aggregated or not. It returns 1 if the result set is aggregated, and 0 if the result set is not aggregated.
On the other hand, the GROUPING_ID function also returns an integer. However, it performs the binary to decimal conversion after concatenating the outcome of all of the GROUPING functions.
In this article, we will see the GROUPING and GROUPING_ID functions in action with the help of examples.
Preparing Some Dummy Data
As always, let’s create some dummy data that we are going to use for the example that we will work with in this article.
Execute the following script:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
In the script above, we have created a database named “Company”. We have then created a table “Employee” within the Company database. Finally, we have inserted some dummy records into the Employee table.
GROUPING Function
As mentioned above, the GROUPING function returns 1 if the result set is aggregated, and 0 if the result set is not aggregated.
Take a look at the following script to see the GROUPING function in action.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
The script above counts the sum of the salaries of all of the male and female employees, which are grouped first by the Department column and then by the Gender column. Two more columns are added to display the result of the GROUPING function applied to the Department and the Gender columns.
The ROLLUP operator is used to display the sum of salaries in the form of grand totals and subtotals.
The output of the script above looks like this.
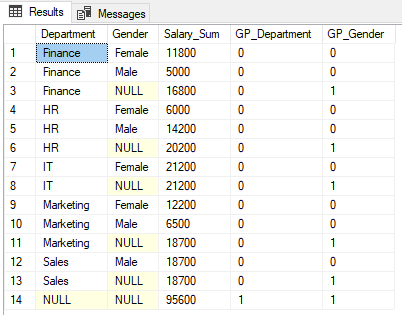
Take a careful look at the output. The sum of salaries is displayed by gender by department gender (rows 1, 2, 4, 5, 7, 9, 10, and 12). It is then also aggregated by gender only (rows 3, 6, 8, 11, and 13). Finally, the grand total of salaries aggregated by both Department and Gender is displayed in row 14.
1 is displayed in the GROUPING function column GP_Gender for rows where results are aggregated by gender i.e. rows 3, 6, 8, 11, and 13. This is because the GP_Gender column contains the result of the GROUPING function applied to the Gender column.
Similarly, row 14 contains the aggregated sum of all the departments and all the columns. Therefore 1 is returned for both the GP_Department and GP_Gender columns.
You can see NULL is displayed in the Department and Gender columns in the output where results are aggregated. For example in row 3, NULL is displayed in the Gender column because the results are aggregated by gender column and so there is no column value to display. We don’t want our users to see NULL, a better word here could be “All genders”.
To do this, we have to modify our script as follows:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
In the script above, if the GROUPING function applied to the Department column returns 1 and “All Departments” is displayed in the Department column. Otherwise, if the Department column contains value NULL, then it will display “Unknown”. The gender column has been modified in the same way.
Running the script above returns following results:
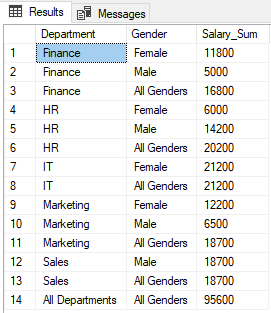
You can see that NULL in the Department and Gender columns where the GROUPING function returns 1, has been replaced with “All Departments” and “All Genders”, respectively.
GROUPING_ID Function
The GROUPING_ID function concatenates the output of the GROUPING functions applied to all the columns specified in the GROUP BY clause. It then performs binary to decimal conversion before returning the final output.
Let’s first concatenate the output returned by the GROUPING function applied to the Department and Gender columns. Take a look at the following script:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
In the output, you will see 0s and 1s returned by the GROUPING function concatenated together. The output looks like this:
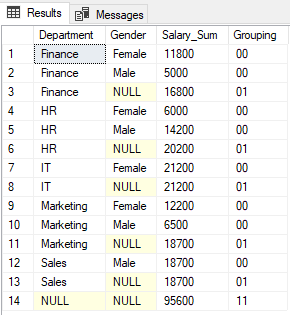
The GROUPING_ID function simply returns the decimal equivalent of the binary value formed as a result of the concatenation of the values returned by the GROUPING functions.
Execute the following script to see the GROUPING ID function in action:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
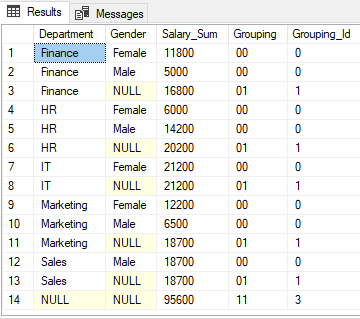
For row 1, the GROUPING ID function will return 0 since the decimal equivalent of ‘00’ is zero.
For rows 3, 6, 8, 11 and 13, the GROUPING_ID function returns 1 since the decimal equivalent of ‘01’ is 1.
Finally, for row 14, the GROUPIND_ID function returns 3, since the binary equivalent of ‘11’ is 3.
The output of the script above looks like this:
See Also:
Microsoft: Grouping_ID Overview
Microsoft: Grouping Overview
YouTube: Grouping & Grouping_ID
Tags: sql, sql functions, sql server, t-sql Last modified: October 23, 2024





