A transaction in SQL is a unit of execution that groups one or more tasks together. A transaction is considered successful if all the tasks within it are executed without error.
However, if any of the tasks within a transaction fails to execute, the whole transaction fails. A transaction has only two results: successful or failed.
A Practical Scenario
Consider a practical example of an ATM (Automated Teller Machine). You go to the ATM and it asks for your card. It runs a query to check whether the card is valid or not. Next, it asks you for your pin code. Again it runs a query to match the pin code. The ATM then asks you for the amount you want to withdraw and you enter the amount you would like. The ATM executes another query to deduct that amount from your account and then dispenses the funds to you.
What if the amount is deducted from your account and then the system crashes due to a power failure without dispensing the notes?
This is problematic because the customer has the funds deducted without having received any money. This is where transactions can be handy.
In the case of a system crash or any other error, all of the tasks within the transaction are rolled back. Therefore, in the case of an ATM, the amount will be added back to your account if you are unable to withdraw it for any reason.
What is a Transaction?
At its simplest, a change in a database table is a transaction. Therefore, INSERT, UPDATE and DELETE statements are all transaction statements. When you write a query, a transaction is performed. However, this transaction cannot be reversed. We will see how transactions are created, committed and rolled back below but first let’s create some dummy data to work with.
Preparing the Data
Run the following script on your database server.
CREATE DATABASE schooldb
CREATE TABLE student
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL,
total_score INT NOT NULL,
)
INSERT INTO student
VALUES (1, 'Jolly', 'Female', 20, 500),
(2, 'Jon', 'Male', 22, 545),
(3, 'Sara', 'Female', 25, 600),
(4, 'Laura', 'Female', 18, 400),
(5, 'Alan', 'Male', 20, 500)
The above SQL script creates a database schooldb. In this database, a table student is created and some dummy data is added to that table.
Executing Queries without Transactions
Let us execute three standard queries. We are not using transactions at the moment.
INSERT INTO student
VALUES (6, 'Suzi', 'Female', 25, 395)
UPDATE student
SET age = 'Six' WHERE id= 6
DELETE from student
WHERE id = 6
Here the first query inserts a student record into the database. The second query updates the age of the student and the third query deletes the newly inserted record.
If you execute the above script, you will see that the record will be inserted in the database and then an error will occur while executing the second query.

If you look at the second query, we are updating age by storing a string value in the age column which can store integer type data. Therefore an error will be thrown. However, the first query will still complete successfully. This means that if you select all the records from the student table, you will see newly inserted record.
[table id=23 /]
You can see that the record with id=6 and name ‘Suzi’ has been inserted into the database. But the age could not be updated and the second query failed.
What if we don’t want this? What if we want to be sure that either all the queries execute successfully or none of the queries execute at all? This is where transactions come handy.
Executing Queries with Transactions
Now let us execute the three queries above within a transaction.
First, let’s see how to create and commit a transaction.
Creating a Transaction
To run a query/queries as a transaction simply wrap the queries within BEGIN TRANSACTION and COMMIT TRANSACTION keywords. The BEGIN TRANSACTION declares the start of a TRANSACTION while COMMIT TRANSACTION states that transaction has been completed.
Let’s execute three new queries on the database we created earlier as a transaction. We will be adding a new record for a new student with ID 7.
BEGIN TRANSACTION
INSERT INTO student
VALUES (7, 'Jena', 'Female', 22, 456)
UPDATE student
SET age = 'Twenty Three' WHERE id= 7
DELETE from student
WHERE id = 7
COMMIT TRANSACTION
When the above transaction is executed, again an error will occur in the second query since again a string type value is being stored in the age column which only stores integer type data.
However, since the error occurs inside a transaction, all the queries that executed successfully before this error occurred will be automatically rolled back. Therefore, the first query which inserts a new student record with id = 7 and name ‘Jena’ will also be rolled back.
Now, if you select all the records from the student table, you will see that the new record for ‘Jena’ has not been inserted.
Manual Transaction Rollback
We know if a query throws an error within a transaction, the whole transaction, including all the queries already executed, are automatically rolled back. However, we can also manually rollback a transaction manually whenever we want.
To rollback a transaction the keyword ROLLBACK is used followed by the name of the transaction. To name a transaction, the following syntax is used:
BEGIN TRANSACTION Transaction_name
Suppose we want our student table to have no records containing duplicate student names. We will add a record for a new student. We will then check if a student with an identical name to the name of the newly inserted student exists in the database. If the student with that name doesn’t already exist we will commit our transaction. If a student with that name does exist, we will rollback our transaction. We will make use of conditional statements in our query.
Take a look at the following transaction:
DECLARE @NameCount int
BEGIN TRANSACTION AddStudent
INSERT INTO student
VALUES (8, 'Jacob', 'Male', 21, 600)
SELECT @NameCount = COUNT(*) FROM student WHERE name = 'Jacob'
IF @NameCount > 1
BEGIN
ROLLBACK TRANSACTION AddStudent
PRINT 'A student with this name already exists'
END
ELSE
BEGIN
COMMIT TRANSACTION AddStudent
PRINT 'New record added successfully'
END
Take a careful look at the above script. A lot of things are happening here.
In the first line, we create an integer type SQL variable NameCount.
Next, we begin a transaction named ‘AddStudent’. You can give any name to your transaction.
Inside the transaction, we inserted a new record for a student with id = 8 and name ‘Jacob’.
Next, using the COUNT aggregate function we count the number of student records where the name is ‘Jacob’ and store the result in ‘NameCount’ variable.
If the value of the variable is greater than 1, it means that a student with the name ‘Jacob’ already exists in the database. In that case, we ROLLBACK our transaction and PRINT a message on the screen that ‘A student with this name already exists’.
If not, we commit our transaction and display the message ‘New record added successfully’.
When you run the above transaction for the first time, there will not be a student record with the name ‘Jacob’. Therefore the transaction will be committed and the following message will be printed:
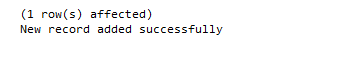
Now try to run the following SQL script on the server:
DECLARE @NameCount int
BEGIN TRANSACTION AddStudent
INSERT INTO student
VALUES (9, 'Jacob', 'Male', 22, 400)
SELECT @NameCount = COUNT(*) FROM student WHERE name = 'Jacob'
IF @NameCount > 1
BEGIN
ROLLBACK TRANSACTION AddStudent
PRINT 'A student with this name already exists'
END
ELSE
BEGIN
COMMIT TRANSACTION
PRINT 'New record added successfully'
END
Here again, we are inserting student record with id =9 and name ‘Jacob’. Since a student record with the name ‘Jacob’ already exists in the database, the transaction will roll back and the following message will be printed:
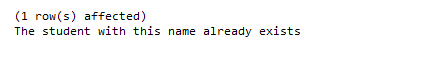







Very informative for SQL developers.
Please post the same at http://www.sqldata-tools.com