This is the first article in a series of articles about In-Memory OLTP. It helps you to understand how the new Hekaton engine works internally. We will focus on details of in-memory optimized tables and indexes. This is the entry-level article, which means you do not need to be an SQL Server expert, however, you do need to have some basic knowledge about the traditional SQL Server engine.
Introduction
The SQL Server 2014 In-Memory OLTP engine (Hekaton project) was created from the ground zero to utilize terabytes of available memory and huge numbers of processing cores. In-Memory OLTP allows users to work with memory-optimized tables and indexes, and natively compiled stored procedures. You can use it along with the disk-based tables and indexes, and T-SQL stored procedures, that SQL Server has always provided.
In-Memory OLTP engine internals and capabilities significantly differ from the standard relational engine. You need to revise almost everything you knew about how multiple concurrent processes are handled.
SQL Server engine is optimized for disk-based storage. It reads 8KB data pages into memory for processing and writes 8KB data pages back to disk after modifications. Of course, SQL Server foremost fixes the changes to disk in the transaction log. Reading 8 KB data pages from disk and writing it back, can generate a lot of I/O and leads to a higher latency cost. Even when the data in the buffer cache, SQL server is designed to assume that it is not, which leads to inefficient CPU usage.
Considering the limitations of traditional disk-based storage structures, the SQL Server team began building a database engine optimized for large main memory and multiple-core CPUs. The team set the following goals:
- Optimized for data that was stored completely in memory but was also durable on SQL Server restarts
- Fully integrated into the existing SQL Server engine
- Very high performance for OLTP operations
- Designed for modern CPUs
SQL Server In-Memory OLTP meets all of these goals.
About In-Memory OLTP
SQL Server 2014 In-Memory OLTP provides a number of technologies to work with memory-optimized tables, along with the disk-based tables. For instance, it allows you to access in-memory data utilizing standard interfaces such as T-SQL and SSMS. The following illustration demonstrates memory optimized tables and indexes, as a part of In-Memory OLTP (on the left) and the disk-based tables (on the left) that require to read and write 8KB data pages. In-Memory OLTP also supports natively compiled stored procedures and provides new in-memory OLTP compiler.
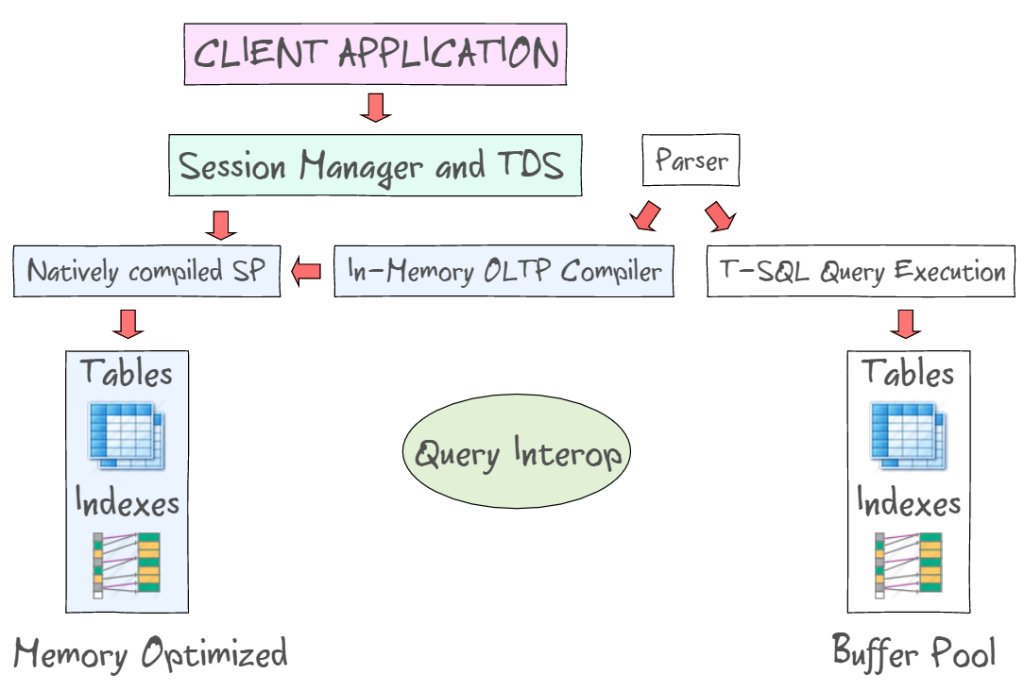
Query Interop allows interpreting T-SQL to reference memory-optimized tables. If a transaction references both memory-optimized and disk-based tables, it can be referred as s cross-container transaction. The client app utilizes Tabular Data Stream – an application layer protocol used to transfer data between a database server and a client. It was initially designed and developed by Sybase Inc. for their Sybase SQL Server relational database engine in 1984, and later by Microsoft in Microsoft SQL Server.
Memory-optimized tables
While accessing disk-based tables, the required data may already be in memory although it may not be. If data is not in memory, SQL Server needs to read it from the disk. The most fundamental difference while using memory-optimized tables is that the whole table and its indexes are stored in memory all the time. Concurrent data operations require no locking or latching.
While a user modifies in-memory data, SQL Server performs some disk I/O for any table that needs to be durable, otherwise speaking, where we need a table to retain in-memory data at the time of a server crash or restart.
Row-based storage structure
Another significant difference is the underlying storage structure. The disk-based tables are optimized for block-addressable disk storage, whereas in-memory optimized tables are optimized for byte-addressable memory storage.
SQL Server keeps data rows in 8K data pages, with space allocation from extents for disk-based tables. The data page is the fundamental unit of disk and memory storage. While reading and writing data from disk, SQL Server reads and writes the relevant data pages only. A data page will only contain data from one table or index. Application processes modify rows on different data pages as required. Later, during the CHECKPOINT operation, SQL Server first fixes the log records to disk and then writes all dirty pages to disk. This operation often causes a lot of random physicals I/O.
For memory-optimized tables, there are no data pages, as well as no extents. There are only data rows written to memory sequentially, in the order the transactions occurred. Each row contains an index pointer to the next row. All I/O is in-memory scanning of these structures. There is no notion of data rows being written to a particular location that belongs to a specified object. Although, you do not have to think that memory-optimized tables are stored as the unorganized set of data rows (similar to disk-based heaps). Each CREATE TABLE statement for a memory-optimized table creates at least one index that SQL Server uses to link together all the data rows in that table.
Every single data row consists of the row header and the payload that is the actual column data. The header stores information about the statement that created the row, pointers for each index on the target table, and timestamp values. Timestamp indicates the time a transaction inserted and deleted a row. SQL Server records updated by inserting a new row version and marking the old version as deleted. Several versions of the same row can exist at any given time. This allows simultaneous access to the same row during the data modification. SQL Server displays the row version relevant to each transaction according to the time the transaction started relative to the timestamps of the row version. This is the core of the new multi version concurrency control mechanism for in-memory tables.
By the way, Oracle has an excellent multi-version control system. Basically, it works as follow:
- User A starts a transaction and updates 1000 rows with some value at time T1.
- User B reads the same 1000 rows at time T2.
- User A updates row 565 with value Y (original value was X).
- User B reaches row 565 and finds that a transaction is in operation since Time T1.
- The database returns the unmodified record from the logs. The returned value is the value that was committed at the time less than or equal to T2.
- If the record could not be retrieved from the redo logs it means the database is not set up appropriately. More space needs to be allocated to the logs.
- The returned results are always the same with respect to the start time of the transaction. So within the transaction, the read consistency is achieved.
Natively compiled tables
The final major difference is that the in-memory optimized tables are natively compiled. When a user creates a memory-optimized table or index, SQL Server stores the structure of every table (along with all indexes) in the metadata. Later, SQL Server utilizes that metadata to compile into DDL a set of native language routines for accessing the table. Such DDL are associated with the database but not actually part of it.
Other words, SQL Server keeps in memory not only tables and indexes but also DDL for accessing and modifying these structures. Once a table was altered, SQL Server needs to recreate all DDL for table operations. That is why you can not alter a table once created. These operations are invisible to users.
Natively compiled stored procedures
The best performance is achieved while utilizing natively compiled stored procedures to access natively compiled tables. Such procedures contain processor instructions and can be executed directly by CPU without further compilation. However, there are some restrictions on the T-SQL constructions for the natively compiled stored procedures (comparing to traditionally interpreted code). Another significant point is that natively compiled stored procedures can only access memory optimized tables.
No locks
In-Memory OLTP is a lock-free system. This is possible because SQL Server never modifies any existing row. The UPDATE operation creates the new version and marks the previous version as deleted.Then it inserts a new row version with new data inside it.
Indexes
As you might have guessed, indexes a very different from the traditional ones. In-memory optimized tables have no pages. SQL Server utilizes indexes to link all the rows that belong to a table into a single structure. We can not use the CREATE INDEX statement to create an index for the in-memory optimized table. Once you have created the PRIMARY KEY on a column, SQL Server automatically creates a unique index on that column. Actually, it is the only allowed unique index. You can create a maximum of eight indexes on a memory-optimized table.
By analogy with tables, SQL Server keeps memory-optimized indexes in memory. However, SQL Server never logs operations on indexes. SQL Server maintains indexes automatically during table modifications.
Memory-optimized tables support two types of indexes: hash index and range index. Both are non-clustered structures.
The hash index is a new type of index, designed specifically for memory-optimized tables. It is extremely useful for performing lookups on specific values. The index itself is stored as a hash table. It is an array of hash buckets, where each bucket is a pointer to a single row.
The range index (non-clustered) is useful for retrieving ranges of values.
Recovery
The basic restore mechanism for a database with memory-optimized tables is the same as the recovery mechanism of databases with disk-based tables. However, recovery of memory-optimized tables includes the step of loading the memory-optimized tables into memory before the database is available for user access.
When SQL Server restarts, every database goes through the following phases of the recovery process: analysis, redo, and undo.
On the analysis phase, the In-Memory OLTP engine identifies the checkpoint inventory to load and preloads its system table log entries. It will also process some file allocation log records.
On the redo phase, data from the data and delta file pairs are loaded into memory. Then the data is updated from the active transaction log based on the last durable checkpoint and the in-memory tables are populated and indexes rebuilt. During this phase, disk-based and memory-optimized table recovery run concurrently.
The undo phase is not needed for memory-optimized tables since In-Memory OLTP doesn’t record any uncommitted transactions for memory-optimized tables.
When all operations are completed, the database is available for access.
Summary
In this article, we took a quick look at the SQL Server In-Memory OLTP engine. We have learned that memory-optimized structures are stored in memory. Application processes can find the required data by accessing these structures in memory without the need for disk I/O. In the following articles, we will take a look how to create and access In-Memory OLTP databases and tables.
Further reading
In-Memory OLTP: What’s new in SQL Server 2016
Using Indexes in SQL Server Memory-Optimized Tables
Tags: in-memory oltp, indexes, sql server, t-sql Last modified: September 23, 2021




