Introduction
A table is a logical structure. When you create a table, you typically would not care which drives it sits on at the storage layer. However, if you are a database administrator, this knowledge may become essential if you need to move certain database portions to alternative storage or volume. Then, you might want definite tables to be on a particular volume or set of disks.
Filegroups in SQL Server offer that abstraction layer allowing us to control the physical location of our logical structures – tables, indexes, etc.
Filegroups
A filegroup is a logical structure for grouping datafiles in SQL Server. If we create a filegroup and associate it with a set of data files, any logical object created on that filegroup will be physically located on that set of physical files.
The primary purpose of such physical file grouping is data allocation and data placement. For instance, we want our transaction data stored on one set of fast disks. Simultaneously, we need the historical data stored on another set of less expensive disks. In such a scenario, we would create the Tran table on the TXN filegroup and the TranHist table on a different HIST filegroup. Further in this article, we shall see how this translates to having the data on different disks.
Creating Filegroups
The syntax for creating filegroups is shown in Listing 1. Note: The database context is the master database. In issuing the statements, we are altering the DB2 database by adding new filegroups to it. Essentially, these filegroups are merely logical constructs at this point. They do not contain any data.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Adding Files to Filegroups
The next step is to add a file to each of the filegroups. We can add more than one file, but we keep it simple for demonstration purposes. Notice that each file is on a different drive entirely, and the syntax allows us to specify the intended filegroup.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Creating Tables to Filegroups
Here we ensure tables to be on desired disks. The syntax for creating tables allows us to specify the filegroup we want.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Taking a step back, we note that we have now achieved the following:
- Created two filegroups.
- Determined the data files (and disks) associated with each filegroup.
- Determined the tables associated with each filegroup.
In essence, the filegroup is the abstraction layer.
Checking Which Filegroups Our Tables Sit On
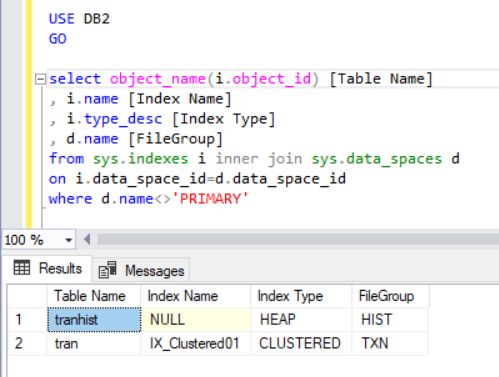
To check what filegroup each table belongs to, we’ll execute the code in Listing 4. We use two main system catalog views: sys.indexes and sys.data_spaces. The sys.data_spaces catalog view contains information about filegroups and partitions, and the main logical structures where tables and indexes are stored.
Note: We did not use sys.tables. The SQL Server associates indexes in a table with data spaces rather than tables, as we might intuitively think.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
The output of the query in Listing 4 displays two tables we’ve just created. Notice that the tranhist table does not have an index. Still, it shows up in the result set, identified as a heap.
A heap is a table that has no clustered index determining the order data physically stored in a table. There can be only one clustered index in a table.
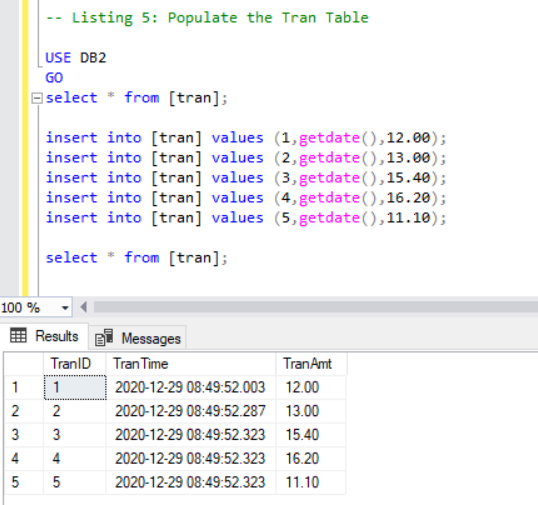
Populating the Tran Table
Now, we have to add a few records to the tran table using the following code:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Moving a Table to Another Filegroup
To move the tran table to another filegroup, we only need to rebuild the clustered index and specify the new filegroup while doing this rebuild. Listing 5 shows this approach.
We perform two steps: first, drop the index, then, recreate it. In between, we check to confirm that the data and the location of the two tables we created earlier remain intact.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
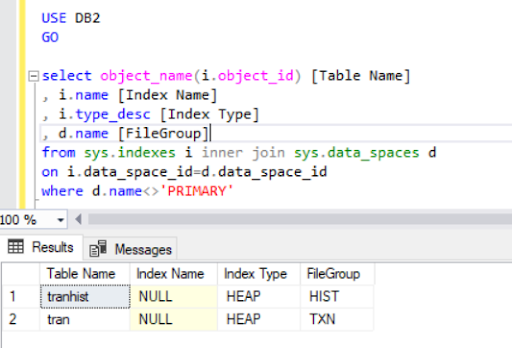
In dropping the clustered index from the tran table, we have converted it to a heap:
When we recreate the clustered index, it also gets indicated in the Listing 4 output.
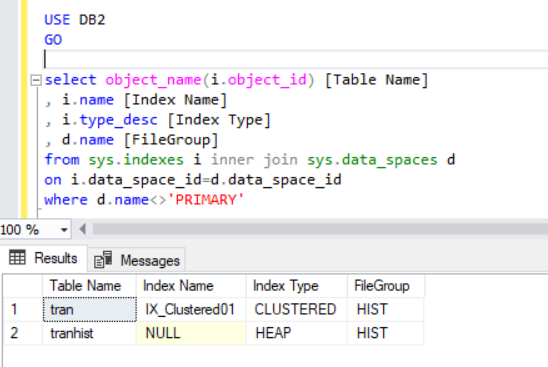
Now we have the tran table on the HIST filegroup.
Conclusion
This article demonstrated the relationship among tables, indexes, files, and filegroups in terms of our SQL Server data storing. We have also explained moving a table from one filegroup to another by recreating the clustered index.
This skill will be helpful when you need to migrate data to new storage (faster disks or slower disks for archiving). In more advanced scenarios, you can use filegroups to manage the data lifecycle by implementing table partitions.






