Analytic functions are special kinds of pre-built functions that come with PostgreSQL by default. They allow you to execute a variety of analytical workloads on your datasets and prepare results.
In the world of cloud computing, where we need to provide insights to customers in a swift and meaningful way, understanding these analytical functions solves a lot of challenges.
This article will talk about the most common analytical functions used in PostgreSQL.
Analytic or Window Functions in PostgreSQL
The analytical functions have been added to the database engine since PostgreSQL 9.1.
The basic purpose of an analytic or a window function is to perform calculations across several records related to the current row. It takes into account the context of the current row and calculates other rows based on that.
The analytic or window functions can be considered somewhat similar to aggregate functions. However, the major difference between these is that an aggregate function group the number of output records, whereas an analytic function does not group the output records to a single row.
Some of the most popular analytic functions in PostgreSQL are as follows.
- RANK – assign a rank to the row based on a column.
- CUME_DIST – find the cumulative distribution of an integer column.
- FIRST_VALUE – find the first value that appears in a group of records within the dataset.
- LAST_VALUE – find the last value that appears within a group of records.
- LAG – display values after the occurrence of the current row.
- LEAD – display values that appear before the occurrence of the current row.
Now, let us try the implementation of these practices. I have prepared a script in SQL for creating a sample database table in your instance of PostgreSQL. You can find this SQL script in my gist.
Thus, first, you need to create a sample database in your PostgreSQL instance, and then run the script on the database. It will create a table with some dummy data in it.
Using the RANK Function
The RANK function serves to assign a rank or assign a row number to every row within a partition of a result set. This rank is set to 1 for the first row in each partition. As the partition changes, the RANK automatically detects the change and assigns the value 1 to that row.
SELECT
laptop_name,
laptop_brand,
RANK() OVER(PARTITION BY laptop_brand ORDER BY price) AS rank_laptop_brand
FROM laptops;
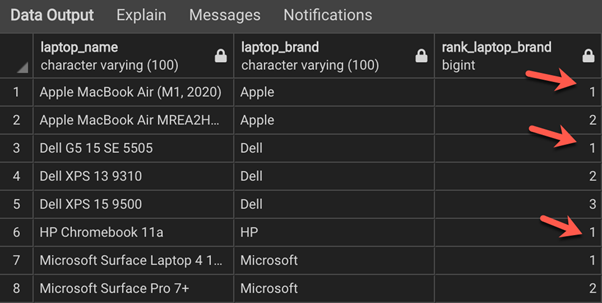
We have prepared the query to rank the records by prices. The partition is created on the laptop_brand column. This means the rank will reset to 1 and start again for every change in this column.
Understanding the CUME_DIST Function
A Data Analyst who has to analyze the cumulative distribution of a numerical column may often need to apply statistical calculations in a relational table.
In statistics, a cumulative distribution function serves to calculate the probability when a random variable may take a specific value less than or equal to the value itself. In SQL, it can be calculated by counting the total number of records present in the dataset and then dividing it by the rank of each row.
Let us understand this with the help of an example:
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
CUME_DIST() OVER(ORDER BY price) AS price_cume_dist
FROM laptops
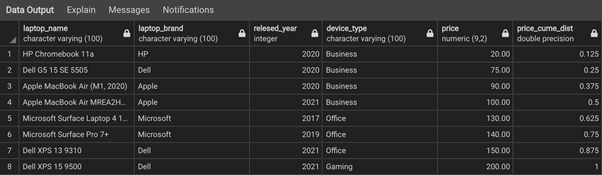
As you can see, the column price_cume_dist gives us the cumulative distribution of the price starting from the lowest to the highest. The last record has the distribution value of 1 which means all prices in the dataset are equal to or lower than that value.
Likewise, the cumulative distribution can also be calculated based on the partition of a group in the dataset instead of the entire dataset. For example, we can calculate the cumulative distribution of the same numerical column based on another column within the dataset that would create the partition. Let us try an example:
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
CUME_DIST() OVER(PARTITION BY device_type ORDER BY price) AS price_cume_dist_by_device_type
FROM laptops
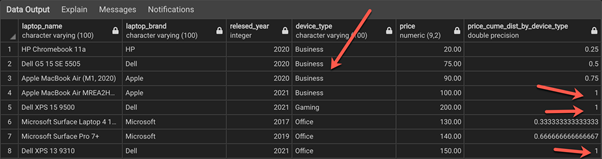
Thus, the price_cume_dist_by_device_type column is calculated based on the partition created by the device_type column. For every new device type, the distribution is reset to 0.
Understanding the FIRST_VALUE and the LAST_VALUE Functions
As it goes by the name, the FIRST_VALUE function serves to find the first occurrence of the value from a column and repeat it for all the other rows. Similarly, the LAST_VALUE is used to find the last occurrence of a column value and then repeat it for all the rows in the dataset.
In practice, these functions are used to eliminate complex SQL joins while obtaining the first or the last value in the dataset. For example, in a web forum database, you might want to know who has initiated the thread and who was the last person to comment on the thread. These can be done by leveraging the FIRST_VALUE and the LAST_VALUE functions.
Let us see a quick demonstration:
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
FIRST_VALUE(laptop_name) OVER(ORDER BY price) AS first_value_laptop_name
FROM laptops
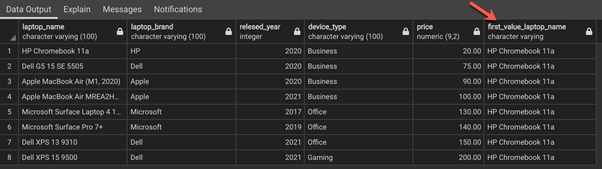
The first value of the laptop_name column is repeated in the last column of the dataset for all columns. You can also add a partition to this query to print the first values in each of the partitions.
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
FIRST_VALUE(laptop_name) OVER(PARTITION BY laptop_brand ORDER BY Price) AS first_value_by_laptop_brand
FROM laptops
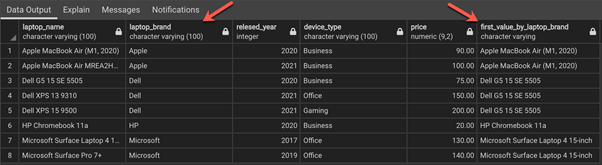
Here, the partition is created based on the laptop_brand column. For each of the brands, the first values change accordingly.
For the implementation of the last value function, you can use the following query:
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
LAST_VALUE(laptop_name) OVER(ORDER BY price) AS last_value_laptop_name
FROM laptops
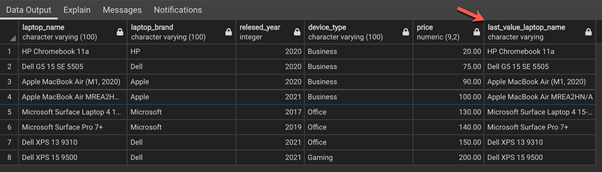
Unlike previous functions, each of the rows has a different value for the LAST_VALUE column. This is because of the way the function is designed. To print the last values for each row, you can use the following SQL command:
SELECT
laptop_name,
laptop_brand,
relesed_year,
device_type,
price,
LAST_VALUE(laptop_name) OVER(ORDER BY price
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_value_laptop_name
FROM laptops
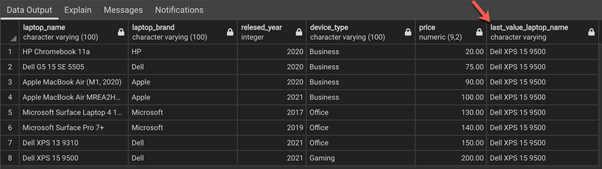
Here, the last value of the laptop_name column is repeated for each of the rows.
Understanding the Usage of LEAD and LAG Functions
LEAD and LAG are two important analytical functions in SQL. They are used to find values from the same column but with an offset to compare sales values from different periods. For example, comparing the sales growth from last quarter to this quarter. Have a look at the example:
SELECT
laptop_name,
LEAD(laptop_name,1) OVER(ORDER BY price) AS first_offset,
LEAD(laptop_name,2) OVER(ORDER BY price) AS second_offset,
laptop_brand,
price
FROM laptops
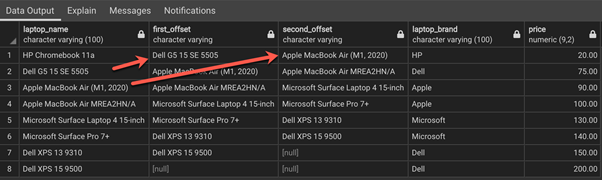
The LEAD function prints the leading row offset values in the second and the third column. Similarly, the LAG function will print the lagging row offsets.
SELECT
laptop_name,
LAG(laptop_name,1) OVER(ORDER BY price) AS first_offset,
LAG(laptop_name,2) OVER(ORDER BY price) AS second_offset,
laptop_brand,
price
FROM laptops
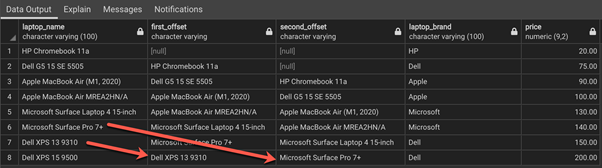
Conclusion
PostgreSQL is an open-source and widely used database management system in today’s world. Most organizations prefer building data warehouses or reporting databases on the PostgreSQL database engine. That’s why analytic functions are necessary for efficient work. To further enhance your PostgreSQL experience, consider using dbForge Studio for PostgreSQL. This GUI tool offers a range of features like SQL development, database exploration, and data manipulation, making PostgreSQL management more efficient and user-friendly. We hope that the current article was helpful for you.
To learn more about analytic (window) functions, refer to the official documentation from PostgreSQL.