
Hash indexes are an integral part of databases. If you’ve ever used a database, chances are that you have seen them in action without even realizing it.
Hash indexes differ in work from other types of indexes because they store values rather than pointers to records located on a disk. This ensures faster searching and insertion into the index. That’s why hash indexes are often used as primary keys or unique identifiers.
Understanding Hash Indices
A hash index is an index type that is most commonly used in data management. It is typically created on a column that contains unique values, such as a primary key or email address. The main benefit of using hash indexes is their fast performance.
The concept behind these indexes can be sophisticated to understand for someone who has never heard about them before. However, understanding hash indexes is important if you need to understand how databases work. It is necessary for solving common problems related to databases and their speed.
The good news is that with a little bit of patience and a mobile phone turned off, you can master hash indexes for sure! So, let’s take a better look.
Quick and Easy
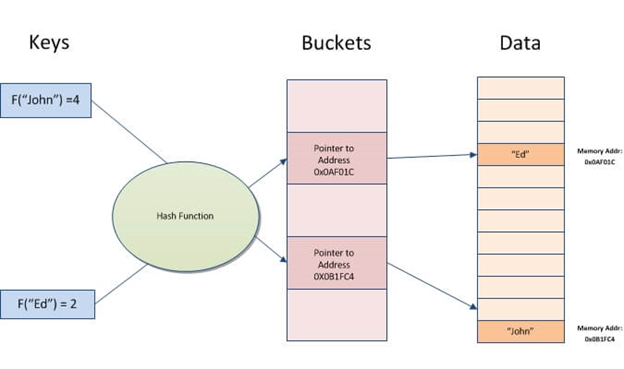
A hash index is a data structure that can be used to accelerate database queries. It works by converting input records into an array of buckets. Each bucket has the same number of records as all other buckets in the table. Thus, no matter how many different values you have for a particular column, every row will always map to one bucket.
Hash indexes allow for quick lookups on data stored in tables. They work by creating an index key from the value and then locating it based on the resulting hash. It is useful when there is a lot of input with similar values or duplicates, as it only needs to compare keys instead of looking through all records.
Was this neither quick nor easy? To understand how hash indexes work and why they’re so powerful you need to understand what is meant by hashing.
Hashing is taking a piece of information (a string) and turning it into an address or pointer for quick access later on.
The idea with hashing is that data gets assigned a small number. When you’re looking up the data, you don’t have to actually sift through masses. Instead, just look up that one number. The simplest example is Ctrl+F-ing the word you’re looking for in a text instead of reading dozens of pages yourself.
What are hash indexes for?
A hash index is a way to speed up the search process. With traditional indexes, you have to scan through every row to make sure that your query is successful. But with hash indexes, this isn’t the case!
Each key of the index contains only one row of the table data and uses the indexing algorithm called hashing which assigns them a unique location in memory, eliminating all other keys with duplicate values before finding what it’s looking for.
Hash indexes are one of many ways to organize data in a database. They work by taking input and using it as a key for storage on a disk. These keys, or hash values, can be anything from string lengths to characters in the input.
Hash indexes are most commonly used when querying specific inputs with specific attributes. For instance, it may be finding all A-letters that are higher than 10 cm. You can do it quickly by creating a hash index function.
Hash indexes are a part of the PostgreSQL database system. This system was developed to increase speed and performance. Hash indexes can be used in conjunction with other index types, such as B-tree or GiST.
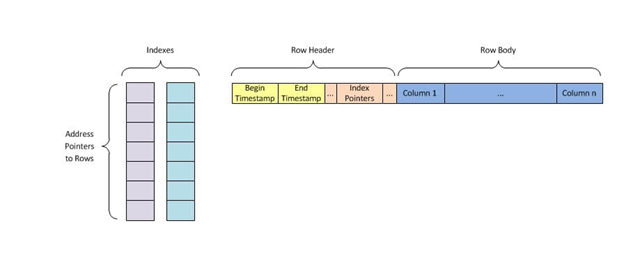
A hash index stores keys by dividing them into smaller chunks called buckets, where each bucket is given an integer ID-number to retrieve it quickly when searching for a key’s location in the hash table. The buckets are stored sequentially on a disk so that the data they contain can be quickly accessed.
More technical explanations can be found on this page (right-mouse-click and choose “Translate to English”).
Advantages
The main advantage of using hash indexes is that they allow for fast access when retrieving the record by the key value. It is often useful for queries with an equality condition. Also, using hash benchmarks won’t require much storage space. Thus, it is an effective tool, but not without drawbacks.
Disadvantages
Hash indexes are a relatively new indexing structure with the potential of providing significant performance benefits. You can think of them as an extension of binary search trees (BSTs).
Hash indexes work by storing data in buckets based on their hash values, which allows for fast and efficient retrieval of the data. They are guaranteed to be in order.
However, it is impossible to store duplicate keys within a bucket. Hence, there will always be some overhead. But so far, the pros of using hash indexes outweigh the cons.
How Does it All Work in a Little More Depth?
Let’s take a demo aviasales database to get a more in-depth understanding of how hash indexes work.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Here you can see how we’re implementing hash indexes by compiling data into sets.
This is an easy example, but note that limitations come with less code infrastructure. There can be a lack of WAL-log access or an inability to recover indexes (indices?) after a crash. Besides, indexes might not participate in replication – it is due to PostgreSQL being outdated. However, just like with Python, you get warnings that often allow you to prevent mistakes.
You can take a deeper look inside these indexes if you’re sufficiently intrigued. For that, we are creating a page inspect extension instance.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
If you want to completely inspect the code, start with README.
Summary
Hash indexes are a data structure that speeds up the process of searching for information in large databases. They work by splitting the data into smaller chunks and then sorting them. Thus, when you search for something, you can find it much faster.
If you want to look up more stuff, there are resources for DYOR. Also, keep an eye out for our new articles, which are coming out faster than you can Ctrl+F the word “hash” on this page. Hope this helps!
Tags: hashing, indexes Last modified: September 08, 2022







