
What if 1 second of a transaction process is too long? You can tune your queries. But what if it’s not enough, can you still step up your game? In-memory OLTP may be the answer.
The current article will focus on this SQL Server’s technology for optimizing transaction processing.
In particular, we’ll examine the following points:
- Essence and value of In-memory OLTP
- Setting up In-memory tables
- T-SQL code for In-memory tables
- Memory-Optimized tables vs Disk-Based tables
- Assess existing databases to In-memory OLTP
- Checking Memory Usage by Memory-Optimized Objects
- SQL Server In-memory OLTP limitations
Fasten the seatbelts, and let’s start!
What is In-Memory Database in SQL Server?
Before we dive deeper, let’s clarify one more point. Most probably, you noticed another term – OLAP before. It seems similar to OLTP in look, and many users tend to mix these terms, which is wrong. OLTP and OLAP are absolutely different things.
What is difference between OLTP and OLAP
OLTP is a system meant for data modification. OLAP is a system targeted towards data retrieval and displaying in a historical context. Both these systems can be very helpful in your workflow.
Have a look at the below table with the side-by-side comparison of OLTP vs OLAP:
| OLTP | OLAP | |
| Basics | An online transactional system that manages database modification and handles large numbers of small transactions. | An online data retrieving and data analysis system that handles large data volumes |
| Queries | Simple queries | Complex queries |
| Types | INSERT, UPDATE, DELETE information from the database. | SELECT to extract data for analyzing and decision-making. |
| Source of data | Transactions | Aggregated data from transactions |
| Presentation | Day-to-day business transactions in a list | Enterprise data in multi-dimensions format |
| Scope | Adjusted to a specific industry (banking, retail, manufacturing, etc.) | Adjusted to a specific subject (marketing, inventory, sales, etc.) |
| Purpose | Running, tracking, and controlling over important business operations in real-time | Analysis, planning, and problem identifying and solving |
| Target users | End users | Professionals, such as business managers, data analysts, and executives |
| Processing time | Comparatively less time to process transactions | Comparatively more time to process transactions |
In our case, we’ll examine the In-Memory OLTP, which is the SQL Server’s technology for optimizing transaction processing. It improves performance because of the following factors:
- It makes data access and transaction execution more efficient in memory.
- It removes the lock and latches contentions between concurrently executing transactions.
- It uses native compilation for row-access logic and T-SQL modules.
The design principles and architecture are different from the classic SQL Server Database Engine, but it’s fully integrated into this engine. You don’t need to buy new tools.
The primary storage is in memory. But there’s a copy of memory-optimized tables on disk for durability purposes. This is read into memory after a server restart. Also, it ensures that your table is still there after a restart. For more information, check this reference from Microsoft. It discusses the durability of memory-optimized tables in detail.
Setting up In-Memory Tables
Before ODB creation, you need to have a separate filegroup for memory-optimized data. This is done upon the creation of the database or modification of an existing one as the first step before creating memory-optimized tables. Here’s how in T-SQL:
-- STEP 1 for new database
CREATE DATABASE TestInMemoryOLTP
GO
-- STEP 2 for new database. STEP 1 for existing database
ALTER DATABASE TestInMemoryOLTP
ADD FILEGROUP TestInMemoryOLTP_FileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Final step
ALTER DATABASE TestInMemoryOLTP
ADD FILE (NAME=[TestInMemoryOLTP_Dir], FILENAME='C:\DATA\TestInMemoryOLTP_Dir')
TO FILEGROUP TestInMemoryOLTP_FileGroup
GO
For a new database, execute CREATE DATABASE <database_name>. Then, ADD FILEGROUP <file_group_name> CONTAINS MEMORY_OPTIMIZED_DATA is the key to in-memory OLTP database. After that, you need to store this filegroup physically with ADD FILE. If you have an existing database, do the same 2 steps with ALTER DATABASE.
Now you can add memory-optimized tables.
Create In Memory Table + 2 More Options
Create your memory-optimized tables using CREATE TABLE with MEMORY_OPTIMIZED and DURABILITY settings.
USE TestInMemoryOLTP
GO
CREATE TABLE dbo.PersonNames_MO
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
GO
Simply set the MEMORY_OPTIMIZED=ON setting. This is obvious if you want memory-optimized tables. Then, set DURABILITY to either SCHEMA_AND_DATA or SCHEMA_ONLY.
The DURABILITY setting tells the SQL Server what you want to keep. SCHEMA_AND_DATA behaves like a disk-based table. If you restart the server, the table and the data will still be there. Meanwhile, only the table structure will be retained for SCHEMA_ONLY. Later, you will see that this is a good replacement for temporary tables.
Add Hash and Non-Clustered Indexes
You can’t have a memory-optimized table without a primary key or at least 1 index. So, if you try the code below, an error will occur.
CREATE TABLE dbo.TestTable
(
id INT NOT NULL IDENTITY(1,1)
,string VARCHAR(50) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
GO
Here’s the error message:
Msg 41321, Level 16, State 7, Line 18
The memory-optimized table 'TestTable' with DURABILITY=SCHEMA_AND_DATA must have a primary key.
Msg 1750, Level 16, State 0, Line 18
Could not create constraint or index. See previous errors.
SCHEMA_ONLY durability will produce a similar error:
Msg 41327, Level 16, State 7, Line 18
The memory-optimized table 'TestTable' must have at least one index or a primary key.
Msg 1750, Level 16, State 0, Line 18
Could not create constraint or index. See previous errors.
Thus, you need to create an index for memory-optimized tables. You can have 2 types of indexes: hash and non-clustered. Clustered indexes are not supported.
Indexes of memory-optimized tables are never written to disks. They are rebuilt every time the database is brought back online.
When creating indexes, do it at table creation or use ALTER TABLE to add an index. CREATE INDEX is not supported.
Now let’s discuss each type of index with examples.
Hash Indexes
Hash indexes store hash keys mapped to the original data. These keys are assigned to buckets. This improves performance due to reducing the key size, making the index compact. In the code below, a primary key is created with a hash index.
CREATE TABLE dbo.PersonNames_MO
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
GO
The hash index can be a non-clustered hash or a unique hash. Non-clustered hash is the default. As we can see from the listing above, a primary key is created with a non-clustered hash index.
Have a look at the example of a unique hash index:
CREATE TABLE dbo.TestTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000)
,string VARCHAR(50) NOT NULL
INDEX idx_string UNIQUE HASH WITH (BUCKET_COUNT=2000)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
GO
Another thing about hash indexes is the BUCKET_COUNT.
Earlier, we mentioned that hash keys are assigned to buckets. Several buckets should be specified on each hash index. How do we choose the right bucket count?
This is quite tricky. Use a wrong number, and it will affect performance. Microsoft suggests between 1 and 2 times the number of unique values in the index key.
For more information, visit the page at Microsoft.
Non-Clustered Indexes
The second type of memory-optimized tables indexes is the non-clustered index. Here’s an example of one:
ALTER TABLE dbo.PersonNames_MO
ADD INDEX idx_Names NONCLUSTERED (LastName, FirstName)
The above listing shows a composite index added on names.
How to Choose Between Hash and Non-Clustered Index
Columns used with the equality operator in the WHERE clause are good candidates for the hash index.
In the example below, the ID column is good for a primary key hash index.
SELECT LastName, FirstName
FROM PersonNames_MO
WHERE id = 624
Hash indexes are also good for full-key searches. For example, you created a hash index on Lastname, Firstname, and Middlename columns. When you apply SELECT, the WHERE clause should include equality searches on all 3 columns. If not, the query optimizer will scan the index for the values resulting in poor performance.
In contrast, non-clustered indexes are great for WHERE clause with >, <, <=, >=, and BETWEEN. You don’t need to include all columns in the WHERE clause to get the best performance.
So, based on this information, you will have to decide which type is the best for your queries. The goal is to have an Index Seek in the execution plan of your queries.
T-SQL Code for In-Memory Table
Part of in-memory OLTP is the use of natively compiled modules. Objects like triggers, user-defined functions, and stored procedures come to mind. These modules are compiled to machine code for maximum performance. Meanwhile, the one we are all used to is interpreted, not natively compiled.
Check out the table below for a list of compilation differences.
| Compilation Type | Natively Compiled | Interpreted |
| Initial Compilation | At create time | At first execution |
| Automatic recompilation | First execution after a database or server restart | On server restart or upon eviction from the plan cache |
| Manual recompilation | Use sp_recompile | Use sp_recompile |
There are also differences when it comes to the code. For example, let’s examine the stored procedure below:
CREATE PROCEDURE dbo.spTestProc
(
@Lastname VARCHAR(30),
@Firstname VARCHAR(30)
)
WITH NATIVE_COMPILATION, SCHEMABINDING -- required
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL= SNAPSHOT, LANGUAGE = N'us_english') -- required
SELECT ID, LastName, FirstName
FROM dbo.PersonNames_MO -- schema name is required. Without it, an error will occur
WHERE LastName = @Lastname
AND FirstName = @Firstname
END
GO
Note the required lines in the code. We need these extra settings to include for native code modules. Try altering the procedure without it, and an error will occur.
The next section will use what we have learned so far and see if in-memory OLTP is fast.
Memory-Optimized Tables vs Disk-Based Tables
Let’s have a speed test. This was the reason for considering in-memory OLTP in the first place.
We will use time durations to measure the performance of disk-based and memory-optimized tables. We can’t use logical reads. Memory-optimized tables won’t have disk I/O. Enabled STATISTICS IO will be useless for them.
Before running the comparison, prepare the database. This includes tables, both disk-based and memory-optimized, and a natively compiled stored procedure.
In-Memory Database Unit Testing
You can run the script below in SQL Server Management Studio or dbForge Studio for SQL Server.
CREATE DATABASE TestInMemoryOLTP
GO
ALTER DATABASE TestInMemoryOLTP
ADD FILEGROUP TestInMemoryOLTP_FileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Change the path of the file group to your preferred location
ALTER DATABASE TestInMemoryOLTP
ADD FILE (NAME=[TestInMemoryOLTP_Dir], FILENAME='C:\DATA\TestInMemoryOLTP_Dir')
TO FILEGROUP TestInMemoryOLTP_FileGroup
GO
USE TestInMemoryOLTP
GO
CREATE TABLE dbo.PersonNames
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
)
GO
CREATE TABLE dbo.PersonNames_MO
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
GO
CREATE TABLE dbo.PersonNames_MO2
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
GO
CREATE TABLE dbo.TempPersonNames_MO
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
,LastName VARCHAR(30) NOT NULL
,FirstName VARCHAR(30) NOT NULL
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
GO
CREATE PROCEDURE dbo.spInsertNames
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DECLARE @i INT = 1;
DECLARE @rowcount INT = 5000;
WHILE @i <= @rowcount
BEGIN
INSERT INTO dbo.PersonNames_MO2
(LastName,FirstName)
SELECT lastname, firstname FROM dbo.PersonNames_MO
WHERE id = @i;
SET @i += 1;
END
END
GO
After running this script, check the output in SQL Server Management Studio. It’s like the one in Figure 1 below.
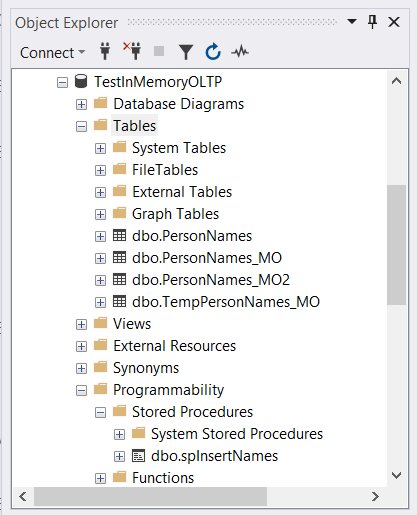
Besides this, you need the AdventureWorks database in the same instance of SQL Server for the input data.
OLTP Speed Test
Now, what are we going to compare? The speed or the time it takes for a row-by-row insert to:
- a disk-based table,
- a memory-optimized table with a SCHEMA_AND_DATA durability,
- memory-optimized table with SCHEMA_ONLY durability,
- a memory-optimized table using a natively compiled stored procedure.
Here’s the script.
SET NOCOUNT ON;
DECLARE @i INT = 1;
DECLARE @rowcount INT = 5000;
DECLARE @startTime DATETIME2 = SYSDATETIME();
DECLARE @elapsed_milliseconds INT;
PRINT 'Getting data from AdventureWorks...'
SELECT BusinessEntityID, Lastname, FirstName
INTO tmpPerson
FROM AdventureWorks.Person.Person
PRINT 'Inserting data to the disk-based table...'
BEGIN TRANSACTION
WHILE @i <= @rowcount
BEGIN
INSERT INTO dbo.PersonNames
(LastName, FirstName)
SELECT Lastname, FirstName FROM tmpPerson
WHERE BusinessEntityID = @i;
SET @i += 1;
END
COMMIT TRANSACTION
SET @elapsed_milliseconds = DATEDIFF(ms, @startTime, SYSDATETIME());
PRINT 'Elapsed time inserting to disk-based table: ' + CAST(@elapsed_milliseconds AS VARCHAR(10)) + ' ms.';
PRINT 'Inserting data to a memory-optimized table with DURABILITY=SCHEMA_AND_DATA...'
SET @startTime = SYSDATETIME()
SET @i = 1
BEGIN TRANSACTION
WHILE @i <= @rowcount
BEGIN
INSERT INTO dbo.PersonNames_MO
(LastName, FirstName)
SELECT Lastname, FirstName FROM tmpPerson
WHERE BusinessEntityID = @i;
SET @i += 1;
END
COMMIT TRANSACTION
SET @elapsed_milliseconds = DATEDIFF(ms, @startTime, SYSDATETIME());
PRINT 'Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_AND_DATA: ' + CAST(@elapsed_milliseconds AS VARCHAR(10)) + ' ms.';
PRINT 'Inserting data to a memory-optimized table with DURABILITY=SCHEMA_ONLY...'
SET @startTime = SYSDATETIME()
SET @i = 1
BEGIN TRANSACTION
WHILE @i <= @rowcount
BEGIN
INSERT INTO dbo.TempPersonNames_MO
(LastName, FirstName)
SELECT Lastname, FirstName FROM tmpPerson
WHERE BusinessEntityID = @i;
SET @i += 1;
END
COMMIT TRANSACTION
SET @elapsed_milliseconds = DATEDIFF(ms, @startTime, SYSDATETIME());
PRINT 'Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_ONLY: ' + CAST(@elapsed_milliseconds AS VARCHAR(10)) + ' ms.';
PRINT 'Inserting data to a memory-optimized table with DURABILITY=SCHEMA_AND_DATA using native SP...'
SET @startTime = SYSDATETIME()
EXEC dbo.spInsertNames
SET @elapsed_milliseconds = DATEDIFF(ms, @startTime, SYSDATETIME());
PRINT 'Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_AND_DATA using native SP: ' + CAST(@elapsed_milliseconds AS VARCHAR(10)) + ' ms.';
SET NOCOUNT OFF
The records were inserted like the code in the natively compiled stored procedure. This lets us compare native code vs. interpreted code in the script.
Now, check the output below:
Getting data from AdventureWorks...
Inserting data to disk-based table...
Elapsed time inserting to disk-based table: 10656 ms.
Inserting data to memory-optimized table with DURABILITY=SCHEMA_AND_DATA...
Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_AND_DATA: 9746 ms.
Inserting data to memory-optimized table with DURABILITY=SCHEMA_ONLY...
Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_ONLY: 8455 ms.
Inserting data to memory-optimized table with DURABILITY=SCHEMA_AND_DATA using native SP...
Elapsed time inserting to memory-optimized table with DURABILITY=SCHEMA_AND_DATA using native SP: 602 ms.
Because of I/O, the elapsed time for the disk-based table is the slowest of the bunch. It took almost 11 seconds.
Using a memory-optimized table with DURABILITY = SCHEMA_AND_DATA ranks third. Then the table with SCHEMA_ONLY durability is even faster because it doesn’t need to retain a copy on a disk.
The winner is using a natively compiled stored procedure.
Look at the table and graph in Figure 2 for a better presentation of the results.
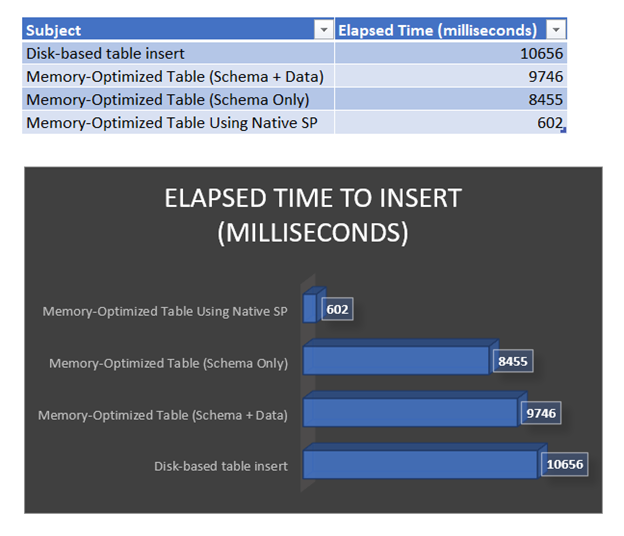
The key points are:
- Use native T-SQL modules for maximum performance.
- Use memory-optimized tables with SCHEMA_ONLY durability to replace temporary tables.
- You also avoid tempDB usage using memory-optimized tables with SCHEMA_ONLY durability.
So, should we all move to memory-optimized tables and native code? Read on further to find out.
Assess Existing Databases to In-Memory OLTP
It’s easier to start from scratch. However, do you feel you need this feature for your existing databases? Then open your SSMS and see the tools you can use for your existing disk-based databases.
Transaction Performance Analysis Overview Report
This standard report provides top candidates for in-memory OLTP, applying to tables and stored procedures.
To access this report, right-click the database you wish to assess and select Reports > Standard Reports > Transaction Performance Analysis Overview.
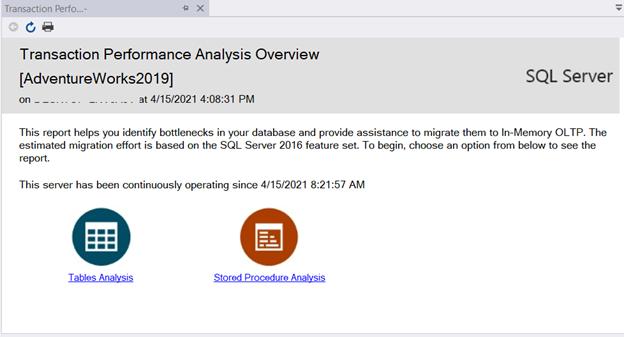
To see which tables are good candidates, click Tables Analysis:
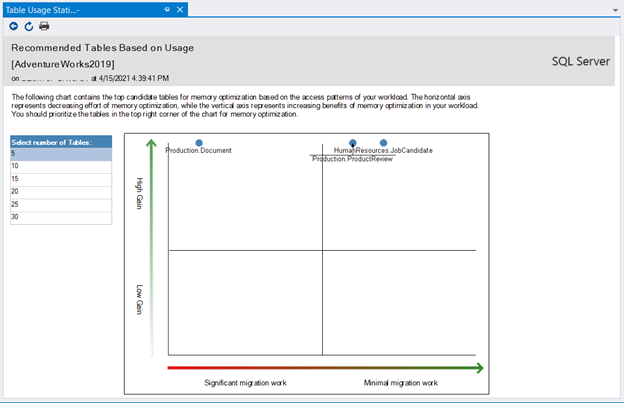
As you can see, 3 tables were identified as candidates for in-memory OLTP. It explains the benefits and how hard or easy the migration will take.
You can do the same in Stored Procedure Analysis. For the AdventureWorks2019 database, no stored procedure appeared in the report.
Memory Optimization Advisor for Performance Management
You can also assess specific tables in your database and see migration issues. This way, you eliminate each problem in the checklist until everything is good. Then, come back to this advisor to migrate the table to a memory-optimized table.
To start using this feature, right-click the table you wish to migrate. A welcome window will appear. Click Next. The Memory Optimization Checklist will appear. If there are issues, work them out first. If everything is green and checked, click Next.
ASSESS THE MIGRATION ISSUES FIRST
Figure 5 shows a screenshot for the ProductReview table in AdventureWorks2019.
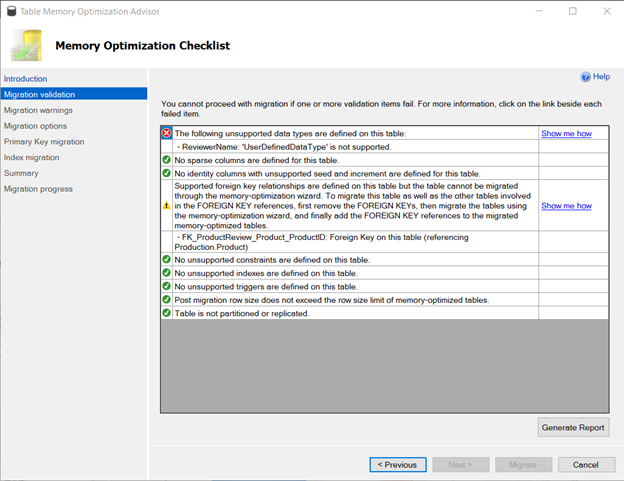
Two (2) migration issues are present in the ProductReview table.
First, you need to resolve the user-defined type in one of the table columns because user-defined types are not supported in memory-optimized tables.
Second, resolve the foreign key constraint to the Product table. Having a foreign key to a disk-based table is not supported.
Therefore, you need to make the Product table a memory-optimized table first. Then migrate the ProductReview table.
SPECIFY THE IN-MEMORY OLTP OPTIONS AND INDEXES
The next screen lets you change options for in-memory OLTP. Remember that you need a separate FILEGROUP for the database in point #2. After that, you have the option to rename the original table. The advisor will help you to estimate the migration memory requirements. If memory is insufficient, the migration will fail.
Further, the advisor will show you options to migrate primary keys and indexes. Earlier, in point #4, we got familiar with hash and non-clustered index types. Now you have to decide which one is best for the migration.
Finally, when everything is set and reviewed, click Migrate to start the migration.
How to Check Memory Usage by Memory-Optimized Objects
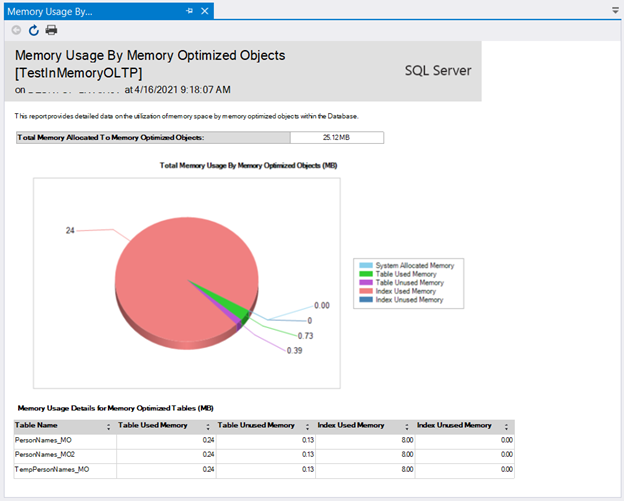
When your in-memory OLTP database is up, you need to monitor what’s happening in your RAM. Otherwise, you might be surprised when out of memory error appears. Besides, you can adjust your configuration.
One way to monitor this is to use the Memory Usage By Memory-Optimized Objects report. It is another standard report from SQL Server Management Studio.
Simply right-click the in-memory OLTP database you want and select Reports > Standard Reports > Memory Usage By Memory-Optimized Objects.
SQL Server In Memory OLTP Limitations
Like everything else in the world, in-memory OLTP has limitations. That’s why a mix of disk-based and memory-optimized objects is allowed within a database. Knowing these limitations will help you decide if in-memory OLTP is right for you. I’ll mention some of them.
Memory-Optimized Table Limitations
The following data types are not supported:
- datetimeoffset
- hierarchyid
- sql_variant
- geography
- rowversion
- geometry
- XML
- user-defined types
The following table commands are not supported:
- TRUNCATE TABLE
- DBCC CHECKTABLE
Foreign Key Limitations
Foreign keys are only supported when referencing primary keys of other memory-optimized tables. This applies to SQL Server 2016 onwards. You can also check other updates of this version in-memory OLTP in SQL server 2016.
Index Limitations
The following index features are not supported:
- Clustered Index – Instead, use a non-clustered or hash index.
- Included Columns
- Filtered Index
The following index commands are not supported:
- CREATE INDEX – Create the index within CREATE TABLE or ALTER TABLE.
- DROP INDEX – Remove the index with ALTER TABLE
Native T-SQL Code Module Limitations
The following language constructs are not supported:
- SELECT INTO
- DELETE with FROM clause
- UPDATE with FROM clause
- Common Table Expressions (CTE)
The following objects cannot be accessed within natively compiled modules:
- disk-based tables.
- temporary tables – Instead, use memory-optimized tables with DURABILITY=SCHEMA_ONLY.
- views – Instead, access the base tables.
For a complete list of limitations, visit this page.
In-Memory OLTP Takeaways
So, what do you think? Is in-memory OLTP right for you? Let’s have a recap of what you need to know.
- Not because data lives in memory that you will lose all data on failure.
- You need another FILEGROUP to contain all memory-optimized data.
- You can start adding memory-optimized tables.
- Add hash or non-clustered indexes on your tables.
- You can also use native code modules like stored procedures for faster processing.
- A speed test proved that in-memory OLTP is faster than disk-based tables and interpreted code.
- For migrating existing databases, you have tools to help you migrate to in-memory OLTP.
- You also have a tool to monitor memory usage once your database is ready.
- However, there are current limitations in the use of in-memory OLTP.
- Finally, to succeed in boosting your database speed, use in-memory OLTP in the right scenarios.
Did we miss something? Let us know in the Comments section. And if you like this post, please share it with your followers and friends on social media platforms.
Tags: in-memory oltp, sql server, t-sql Last modified: March 31, 2023








[…] In-Memory OLTP: Overview and Usage Scenarios […]