
Introduction
Recently we encountered an interesting performance problem on one of our SQL Server databases that process transactions at a serious rate. The transaction table used to capture these transactions became a hot table. As a result, the problem showed up in the application layer. It was an intermittent timeout of the session seeking to post transactions.
This happened because a session would typically “hold on” to the table and cause a series of spurious locks in the database.
The first reaction of a typical database administrator would be to identify the primary blocking session and terminate it safely. This was safe because it was typically a SELECT statement or an idle session.
There were also other attempts to solve the problem:
- Purging the table. This was expected to grant good performance even if the query had to scan a full table.
- Enabling the READ COMMITTED SNAPSHOT isolation level to reduce the impact of blocking sessions.
In this article, we’ll try to recreate a simplistic version of the scenario and use it to show how simple indexing can address situations like this when done right.
Two Related Tables
Have a look at Listing 1 and Listing 2. They show the simplified versions of tables involved in the scenario under consideration.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Listing 3 shows a trigger that inserts four rows into the TranDetails table for every row inserted in the TranLog table.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Join Query
It is typical to find transaction tables supported by large tables. The purpose is to keep much older transactions or to store the details of records summarized in the first table. Think of this as orders and orderdetails tables that are typical in SQL Server sample databases. In our case, we are considering the TranLog and TranDetails tables.
Under normal circumstances, transactions populate these two tables over time. In terms of reporting or simple queries, the query will perform a join on these two tables. This join will capitalize on a common column between the tables.
First, we populate the table using the query in Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
In our sample, the common column used by the join is the TranID column:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
You can see the two simple sample queries that use a join to retrieve records from TranLog and TranDetails.
When we run the queries in Listing 5, in both cases, we have to do a full table scan on both tables (see Figures 1 and 2). The dominant part of each query is the physical operations. Both are inner joins. However, Listing 5a uses a Hash Match join, while Listing 5b uses a Nested Loop join. Note: Listing 5a returns 4000 rows while Listing 4b returns 4 rows.
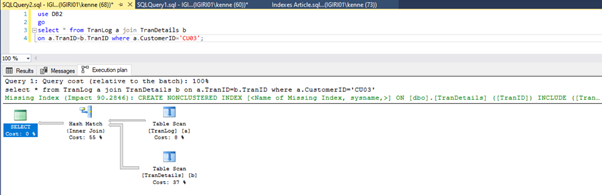
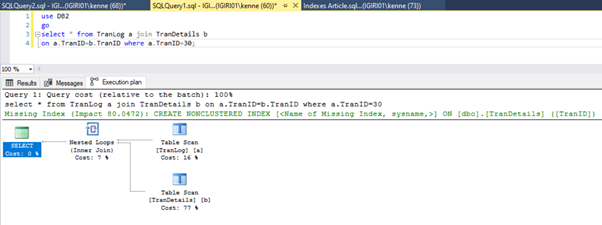
Three Performance Tuning Steps
The first optimization we do is introducing an index (a primary key, to be exact) on the TranID column of the TranLog table:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
Figures 3 and 4 show that SQL Server utilizes this index in both queries, doing a scan in Listing 5a and a seek in Listing 5b.
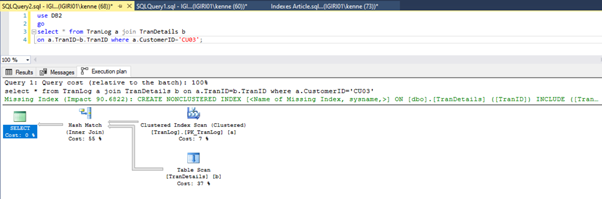
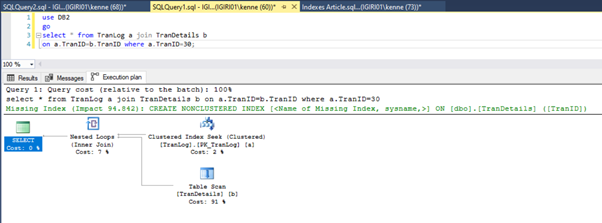
We have an index seek in Listing 5b. It happens because of the column involved in the WHERE clause predicate – TranID. It is that column we have applied an index on.
Next, we introduce a foreign key on the TranID column of the TranDetails table (Listing 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
This does not change much in the execution plan. The situation is virtually the same as shown earlier in Figures 3 and 4.
Then we introduce an index on the foreign key column:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
This action changes the execution plan of Listing 5b dramatically (See Figure 6). We see more index seeks to happen. Also, notice the RID lookup in Figure 6.
RID lookups on heaps typically happen in the absence of a primary key. A heap is a table with no primary key.
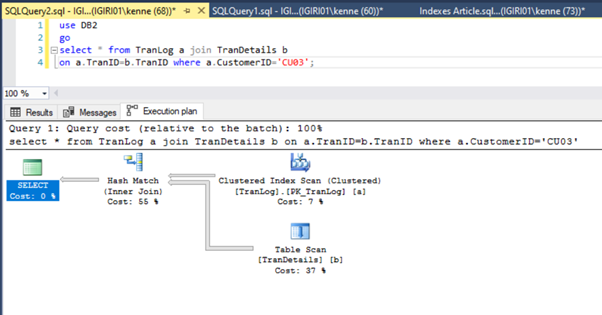
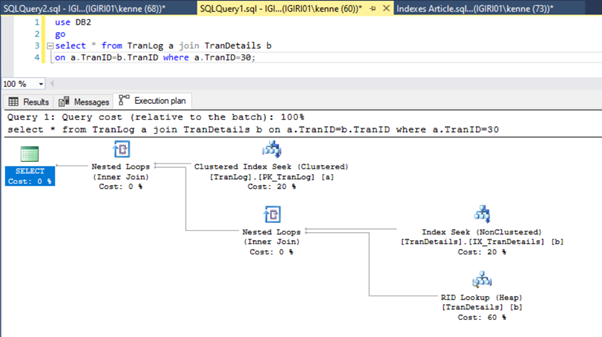
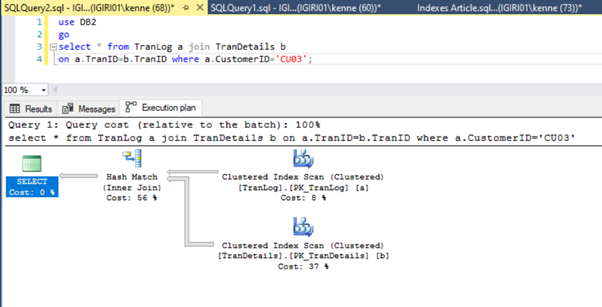
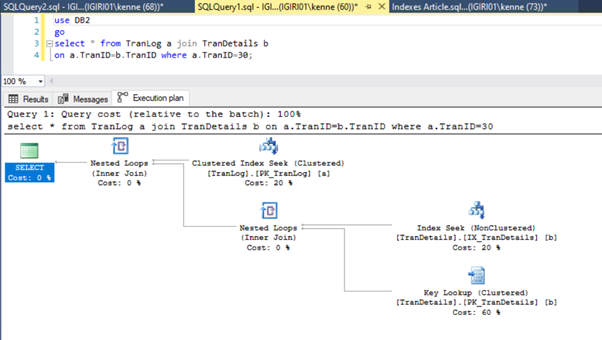
Finally, we add a primary key to the TranDetails table. This gets rid of the table scan and RID heap lookup in Listings 5a and 5b respectively (See Figures 7 and 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Conclusion
The performance improvement introduced by indexes is well-known to even novice DBA. However, we want to point out that you need to look closely at how queries use indexes.
Furthermore, the idea is to establish the solution in the particular case where we have the join queries between Transaction Log tables and Transaction Detail tables.
It generally makes sense to enforce the relationship between such tables using a key and introduce indexes to the primary and foreign key columns.
In developing applications that use such a design, developers should keep in mind the required indexes and relationships at the design stage. Modern tools for SQL Server specialists make these requirements much easier to fulfill. You can profile your queries using the specialized Query Profiler tool. It is a part of the multi-featured professional solution dbForge Studio for SQL Server developed by Devart to make the lives of DBA simpler.
Tags: foreign key, performance, primary keys Last modified: September 08, 2022








test
rerq
312312