In this article, we will focus on real time operational analytics and how to apply this approach to an OLTP database. When we look at the traditional analytical model, we can see OLTP and analytic environments are separate structures. First of all, the traditional analytic model environments need to create ETL (Extract, Transform and Load) tasks. Because we need to transfer transactional data to the data warehouse. These types of architecture have some disadvantages. They are cost, complexity and data latency. In order to eliminate these disadvantages, we need a different approach.
Real Time Operational Analytics
Microsoft announced Real-Time Operational Analytics in SQL Server 2016. The capability of this feature is to combine transactional database and analytic query workload without any performance issue. Real-Time Operational Analytics provides:
- hybrid structure
- transactional and analytics queries can be executed at the same time
- does not cause any performance and latency issues.
- a simple implementation.
This feature can overcome the disadvantages of the traditional analytic environment. The main theme of this feature is that the column store index maintains a copy of data without affecting the performance of the transactional system. This theme allows the analytic queries to execute without affecting the performance. So this minimizes the performance impact. The main limitation of this feature is that we can’t collect data from different data sources.
Non-Clustered Column Store Index
SQL Server 2016 introduces updateable “Non-Clustered Column Store Index”. The non-Clustered Column Store Index is a column-based index which provides performance benefits for analytical queries. This feature lets us create the real time operational analytics framework. That means we can execute transactions and analytical queries at the same time. Consider that we need monthly total sales. In a traditional model, we have to develop ETL tasks, data mart, and data warehouse. But in real time operational analytics, we can do it without requiring any data warehouse or any changes to the OLTP structure. We only need to create suitable non-clustered column store index.
Architecture of non-clustered column store index
Let’s shortly look at the architecture of non-clustered column store index and running mechanism. The non-clustered column store index contains a copy of a part or all of the rows and columns in the underlying table. The main theme of non-clustered column store index is to maintain a copy of the data and use this copy of data. So this mechanism minimizes transactional database performance impact. The non-clustered column store index can create one or more than one columns and can apply a filter to columns.
When we insert a new row into a table which has a non-clustered column store index, firstly, SQL Server creates a “rowgroup”. Rowgroup is a logical structure which represents a set of rows. Then SQL Server stores these rows in a temporary storage. The name of this temporary storage is “deltastore”. SQL Server uses this temporary storage area because this mechanism improves compression ratio and reduces the index fragmentation. When the number of rows achieves 1,048,577, SQL Server closes the state of row group. SQL Server compresses this row group and changes the state to “compressed”.
Now, we will create a table and add the non-clustered column store index.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
In this step, we will insert several rows and look at the properties of the non-clustered column store index.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
This query will display the row group states, the total number of rows size and other values.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

The image above shows us the deltastore state and the total number of rows which are not compressed. Now we will populate more data to the table and when the number of rows achieves 1,048,577, SQL Server will close the first rowgroup and open a new rowgroup.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server will compress this rowgroup and create a new rowgroup. The “COMPRESSION_DELAY” option allows us to control how long the rowgroup waits in the closed status.

When we run the index maintain commands (reorganize, rebuild) the deleted rows are physically removed and the index is defragged.

When we update (delete + insert) some rows in this table, the deleted rows are marked as “deleted” and new updated rows are inserted into the deltastore.
Analytic query performance benchmark
In this heading, we will populate data to the Analysis_TableTest table. I inserted 4 million records. (You have to test this step and next steps in your test environment. Performance issues may occur and also DBCC DROPCLEANBUFFERS command can hurt performance. This command will remove all the buffer data on the buffer pool.)
Now we will run the following analytic query and examine the performance values.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

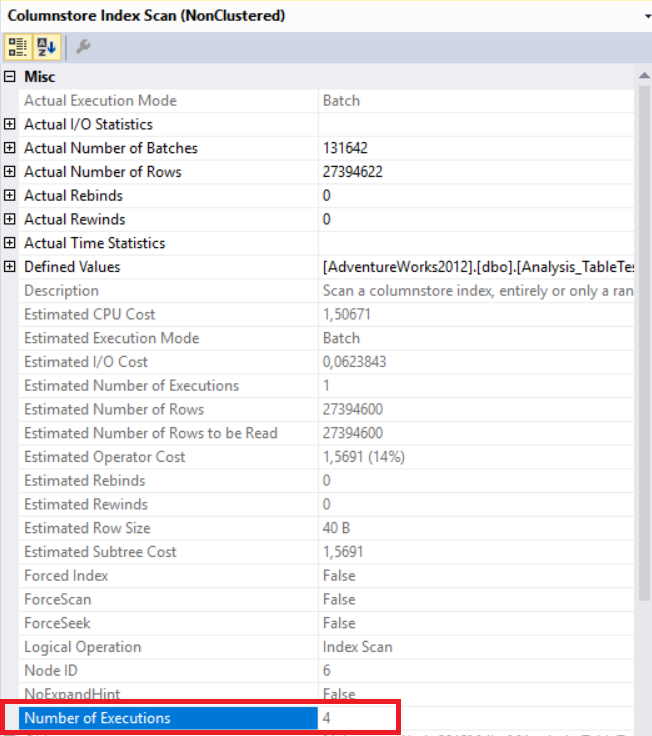
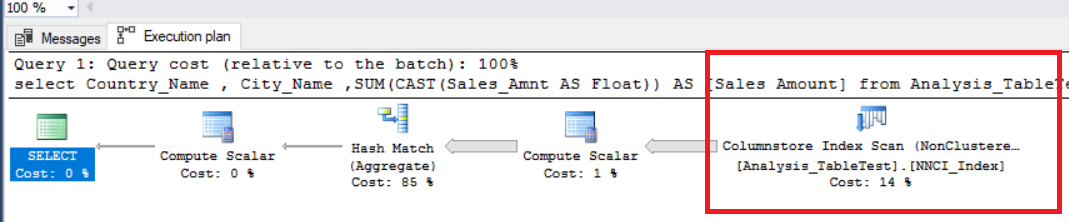
In the above image, we can see the non-clustered column store index scan operator. The below table shows CPU and execution times. This query consumes 1.765 milliseconds in CPU and completed in 0.791 milliseconds. The CPU time is greater than the elapsed time because the execution plan uses parallel processors and distributes tasks to 4 processor. We can see it in the “Columnstore Index Scan” operator properties. The “Number of executions” value indicates this.

Now we will add a hint to the query to reduce the number of processors. We will not see any parallelism operator.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

The below table defines execution times. In this chart, we can see the elapsed time is greater than the CPU time because SQL Server used only one processor.
Now we will disable the non-clustered column store index and execute the same query.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

The above table shows us the non-clustered column store index provides incredible performance in analytical queries. Approximately, the column store indexed query is five times better than the other.
Conclusion
Real-Time Operational Analytics provide incredible flexibility because we can execute analytic queries in OLTP systems without any data latency. At the same time, these analytic queries do not affect the performance of the OLTP database. This feature gives us the ability to manage transactional data and the analytic queries in the same environment.
References
Column store indexes – Data loading guidance
Get started with Column store for real time operational analytics
Real-Time Operational Analytics
Further Reading:
SQL Server Index Backward Scan: Understanding, Tuning
Using Indexes in SQL Server Memory-Optimized Tables
Tags: indexes, performance, query performance, sql server Last modified: October 07, 2022




