
Cartesian product in SQL is a term from the set theory of mathematics. However, we can also find this term in SQL database manuals. What does it mean, and how should we work with it? Let’s learn it.
A Cartesian product of two sets X and Y, denoted X × Y, is the set of all ordered pairs where x is in X and y is in Y.
In terms of SQL, the Cartesian product is a new table formed of two tables. If those tables have 3 and 4 lines respectively, the Cartesian product table will have 3×4 lines. Therefore, each row from the first table joins each row of the second table. You get the multiplication result of two sets making all possible ordered pairs of the original sets’ elements.
The Cartesian product involves a large number of computational operations that are usually redundant. Thus, for large tables, we recommend using the qualifier operators.
How to Implement a Cartesian Product in SQL?
Implementing a Cartesian Product in SQL is possible with the CROSS JOIN operator that returns the cross product of two tables.
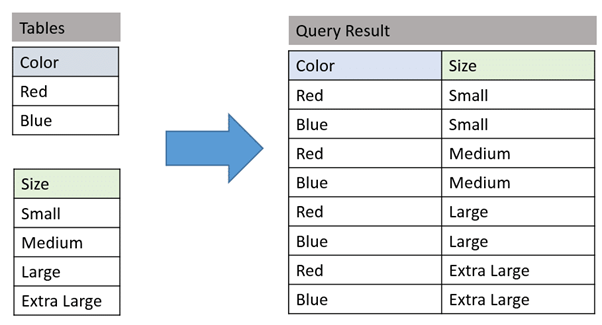
Let’s have a look at the example in the below image. Two corresponding tables state the color and size values. Because there is no JOIN condition, all rows (2) from the color table are joined to all rows (4) from the size table, generating 8 rows as the result.
The CROSS JOIN method applies to many situations. For instance, we need to have the full salary data of an office for a month. Even if month X has no salary, you can cross-combine Offices with a table of all Months.
Note: In practice, the Cartesian product of tables isn’t common. We might want to connect all employees with all departments, but it is reasonable only if everyone works according to a single plan, and their work affects all departments. Connecting all employees/departments with all locations is complete nonsense.
Still, sometimes the database contains tables with only one row for storing some constants (e.g., company name). Here, we can connect such tables to any query using the Cartesian product operation.
Using the Cartesian Product SQL in Practice
The Cartesian product SQL is useful when:
- the JOIN condition is omitted;
- the JOIN condition is invalid;
- all rows in the first table are concatenated with all rows in the second table.
Cartesian product of tables becomes more common if it is necessary to select only those records that match each other. We can do it by specifying the selection condition using ON, USING, or WHERE.
Sometimes, Cartesian products occur due to an error in the query text. The primary method of joining tables is an inner or natural join operation.
Joints in Cartesian Product
Joints play an important role in the Cartesian product implementation. They are its subsets.
For example, our Cartesian product of n tables is a table containing all possible rows of r. Here, r is a concatenation of some rows from the first table, rows from the second table, etc. until rows from the nth table. Let’s find out if we can get the Cartesian product using the SELECT statement.
To obtain the Cartesian product of several tables, specify the list of multiplied tables in the FROM clause, and the list of all their columns – in the SELECT clause. In our case, we need to get the Cartesian product of Type of Dishes (5 rows) and Meal (3 rows) tables:
SELECT type_of_dishes.*, meal.*
FROM type_of_dishes, meal;
The result is a table containing 5 x 3 = 15 rows:
| Type of Dishes | Meal |
| Snack | Breakfast |
| Snack | Lunch |
| Snack | Dinner |
| Soup | Breakfast |
| Soup | Lunch |
| Soup | Dinner |
| Main dish | Breakfast |
| Main dish | Lunch |
| Main dish | Dinner |
| Dessert | Breakfast |
| Dessert | Lunch |
| Dessert | Dinner |
| Drink | Breakfast |
| Drink | Lunch |
| Drink | Dinner |
Now, we multiply the tables Menu (20 rows), Meal (3 rows), Type of Dishes (5 rows), and Dishes (30 rows) by the following query:
SELECT Menu.*, Meal.*, Type_of_Dishes.*, Dishes.*
FROM Menu, Meal, Type_of_Dishes, Dishes;
We get a table that contains 20 x 3 x 5 x 30 = 9000 rows.
The Inner JOIN of Tables in Practice
The inner JOIN can unite tables with common columns only. Thus, when we are performing this operation, it concatenates only strings having common values.
Typically, an inner JOIN is used for tables that have a one-to-many relationship. In this case, the primary key of the main table and the foreign key of the subordinate table act as relationship columns. Thus, the main table rows that do not have related rows in the subordinate table will not be included in the query result at all during an inner JOIN.
In SQL, there are 2 ways to implement an inner JOIN of tables. Both methods are equivalent and usually lead to the same query execution algorithm. Let’s learn them in detail.
Selection from the Cartesian Product
Let’s assume we want to display the names of all students and their marks. The appropriate request looks like below:
SELECT students.name_st, marks.mark
FROM students, marks
WHERE students.cod_st = marks.cod_st
JOIN Operation
The same query connecting students to their marks can be written slightly differently:
SELECT students .name_st, marks.mark
FROM students join marks
ON students.cod_st = marks.cod_st
The results of both queries are similar and look like this:
name_st mark
Smith Smith... Adams Adams Adams ...
Each student’s surname is repeated in the resulting table as many times as the student received marks. If the students’ table contains, for example, a row with the surname Anderson, who has not yet received any marks, this surname will not be displayed in the resulting table at all.
This is how the inner join operation works.
We need to pay attention to some features of the above examples.
First, the query text uses compound column names written with the dot notation: table_name.column_name
The use of distinguished names avoids ambiguity in the record of the column name, as different tables can contain columns of the same name. If the name of any column is unique within the table from the FROM clause, you can use a simple name. However, distinguished names are better because such queries are faster to compile.
Secondly, in both queries above, we explicitly specified the JOIN condition – equality of the relationship columns (students.cod_st = marks.cod_st).
In theory, you could shorten the query text because there is only one common column (cod_st) in the students and marks tables. However, joining two tables is not always done only by the primary and foreign keys. Any two columns of the same type can be used for joining tables.
Be very careful when linking rows using the non-key columns for the relationship. For example, a query where you define a relationship through the condition students.cod_st = marks.cod_sub would be syntactically correct, but completely meaningless.
Conclusion
Generally speaking, a Cartesian SQL product generates a large number of lines and the result is rarely useful. Therefore, when you work with SQL tables, it is better to avoid Cartesian product usage. You should always include a valid JOIN condition in the WHERE clause, except for the cases where you have a specific need to combine all rows from all tables.
However, Cartesian product SQL could apply to tests where you have to generate a large number of rows to simulate the required data amount.
Last modified: October 13, 2022



