
Imagine you need to query a table with a WHERE clause on columns a, b, and c. Sometimes, you filter the results with columns a and b only. Should you create 2 indexes? One would be with columns a, b, and c, and another one would be for columns a and b only, right? The answer depends on your knowledge of the SQL Composite Index.
When I was new to SQL, these were burning and confusing questions. But clients sometimes give us a hell of work, and we don’t have time to look for answers. At some point, I got stuck. If you’re here, you’ve probably got that “me” time to look for the answers yourself.
That’s good because this post will cover just that. Examples will be provided too. Also, if you are stuck just as I was before, I hope the answers to these 5 questions will take you forward. So, without further ado, let’s dig in.
1. What is a SQL Composite Index?
Simply put, an SQL composite index is an index with an index key of more than 1 column. Earlier, we wondered if we had to create 2 indexes – one for the a, b, and c columns, and another one for the a and b columns only. These pertain to composite indexes.
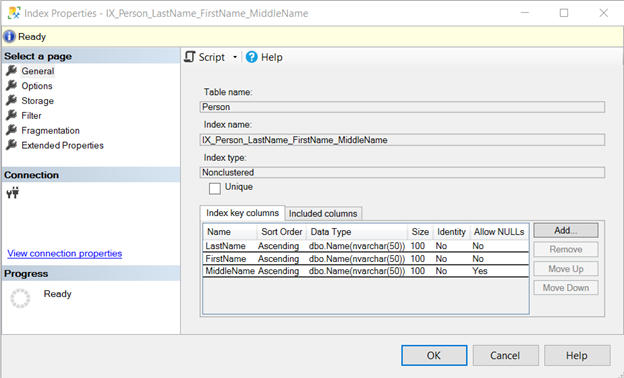
But a better example is the Person table in the AdventureWorks sample database. It has a composite index of Lastname, Firstname, and Middlename columns.
Another example is the BusinessEntityAddress table in AdventureWorks. Its primary key is a composite index composed of BusinessEntityID, AddressID, and AddressTypeID.
2. How Do You Create a SQL Composite Index?
Now that we know what a SQL composite index is, how do you create one? There are 2 ways:
- through T-SQL code
- or a SQL GUI tool like SQL Server Management Studio or dbForge Studio for SQL Server
T-SQL
One way is through ALTER TABLE. Here’s an example where a primary key is also a clustered, composite index:
USE AdventureWorks2017
GO
ALTER TABLE [Person].[BusinessEntityAddress] ADD CONSTRAINT [PK_BusinessEntityAddress_BusinessEntityID_AddressID_AddressTypeID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC,
[AddressID] ASC,
[AddressTypeID] ASC
)
GO
Another example uses CREATE INDEX:
USE [AdventureWorks2017]
GO
CREATE NONCLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
Using SQL GUI Tool
Not fond of coding your way to indexes? Then try a SQL GUI tool. Here’s how to do it in SQL Server Management Studio:
- In the Object Explorer, expand your desired database > Tables folder > the desired table.
- To create a new index, right-click the Indexes folder. Select New Index and the index type.
- Name your index and add the desired columns. Finally, click OK.
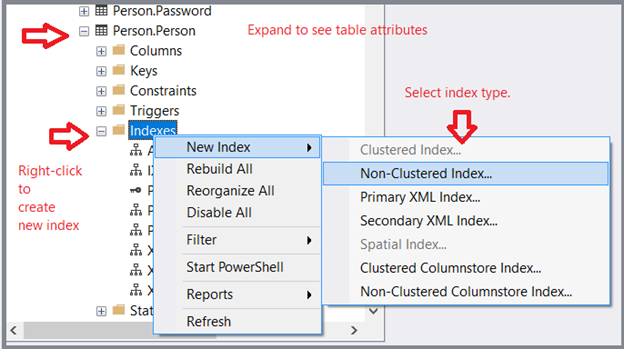
See how it looks:
3. When to Use a Composite Index?
This is one more question I had when I was new to SQL. And here’s a straight answer:
You create a composite index when covering the columns for searches and lookups.
Let’s have an example:
USE AdventureWorks2017
GO
SELECT
FirstName
,MiddleName
,LastName
FROM Person.Person
WHERE LastName = 'D''Hers'
AND FirstName = 'Thierry'
AND MiddleName = 'B'
Analysis
Notice the WHERE clause? It includes 3 columns that need exact matches.
If there’s no index in the table, SQL Server will do a table scan. But if there’s a clustered index, it will do a clustered index scan.
A table scan means the database engine will search the table by scanning record by record until a match is found. That’s not a good idea for a fast query on a large table.
Meanwhile, an index scan is similar to a table scan. But it uses an index instead.
To know what SQL Server uses for your query, you Ctrl-M in SQL Server Management Studio. Or click Include Actual Execution Plan from the toolbar as an alternative. Do this before executing your query.
To see the execution plan when there’s no index on name, see Figure 3:
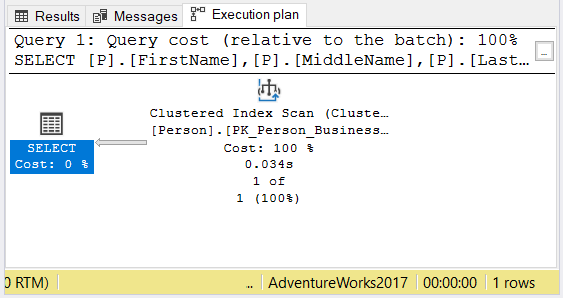
It shows the clustered index scan usage to find the name of Thierry B. D’Hers.
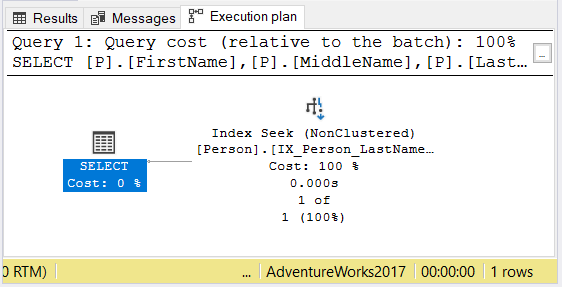
When you create a query for this table, your goal is to avoid a table or index scan. Figure 4 below is how it is supposed to be when the index is present:
4. How Does Column Order Affect Composite Index Usage?
You may wonder, what happens if you reverse the order of the columns in the WHERE clause. Or what if you use 1 or 2 columns from a 3-column composite index? Does it matter?
It does. And it can be disastrous from a query performance standpoint.
When an Index Seek Will Result
Let’s have another experiment. Try the listing below to get an index seek for 4 variations of the WHERE clause.
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
LastName = 'D''Hers'
AND FirstName = 'Thierry'
AND MiddleName = 'B'
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
FirstName = 'Thierry'
AND MiddleName = 'B'
AND LastName = 'D''Hers'
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
LastName = 'D''Hers'
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
LastName LIKE 'smi%'
AND FirstName LIKE 'an%'
The first SELECT statement follows the index key order in the WHERE clause. Yet, in the second SELECT statement, the WHERE clause didn’t follow the column order in the index. But since the index covers all the columns in the WHERE clause, an index seek is used.
The third SELECT statement uses only the first column in the index. The index seek is still used. The fourth SELECT uses the LIKE operator, and yet, an index seek is still used.
The Execution plan of the 4th case shows identical plan operators. Check out the one for the first SELECT in Figure 5.
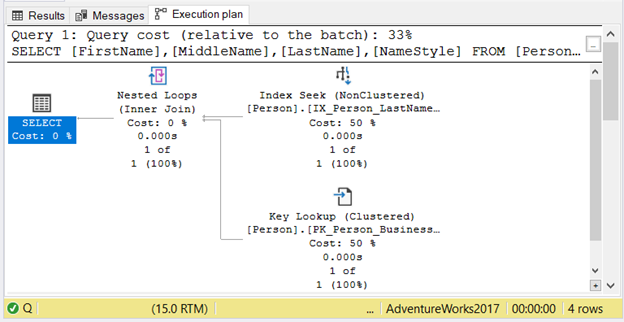
Don’t mind the Key lookup for now. The NameStyle column caused it because it is not covered by any index in the table.
When an Index Scan Will Result
But what if you pick the other 2 columns for your SELECT? That’s the Firstname and Middlename columns? Let’s see:
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
FirstName = 'Thierry'
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person
WHERE
FirstName = 'Thierry'
AND MiddleName = 'B'
Although this new set of queries are odd in the real world, it’s not impossible. Let’s inspect what happens to the execution plan in Figure 6 below:
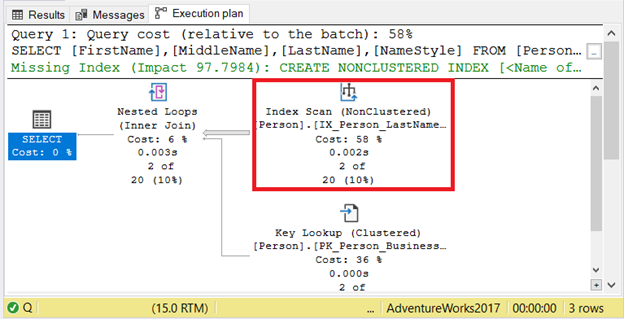
You can see the results of the Index Scan. Another is an Index Suggestion. But why? Aren’t these covered in the composite index?
Statistics, Histogram, and Density
The query optimizer uses statistics to create the best query plans. Refer again to the last question – our statistics have something to do with it.
Each statistics object is created on one or more table columns. It includes a histogram of values that displays the distribution of values in the first column. In our sample, the Person table’s index on name uses Lastname as the first column. Since this is a composite index, statistics also include information about values’ correlation among other columns. Those columns are Firstname and Middlename. BusinessEntityID is also in the mix because it’s a locator to the clustered index. These correlations or densities derive from the number of distinct rows of column values.
To see this in SQL Server, view the properties of IX_Person_LastName_FirstName_MiddleName statistics. Right-click it in the Object Explorer in SSMS, select Properties > Details.
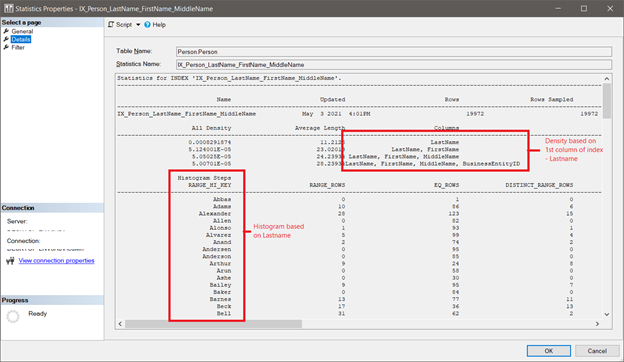
Notice the sections boxed in red in Figure 7. The density for all column combinations in the index starts with Lastname – the first column of the index. Check out the histogram too. It is also based on Lastname.
So, what’s the deal with these statistics?
Statistics store and base values on the first column. Thus, the query optimizer will decide on an index seek when the WHERE clause includes that column. Remove it, and the result will be an index scan.
What makes Lastname the choice for the first column in the index? The sample in the AdventureWorks database assumes that the Lastname column is more selective than the other 2. In other words, it will most likely be present in most queries.
KEY LESSON
Thus, when creating a composite index, the first column should be the most selective. That is if you want to make your queries run faster using a composite index.
If That’s The Case, Should You Create Another Index?
Let’s go back to the first questions of our introduction. If SQL Server knows more of the first column in a composite index, should you create another index for other combinations?
It depends on some factors.
Adding another index will have a performance penalty when writing to the table. That includes INSERT, UPDATE, or DELETE. But if reading faster is more important to you than writing faster, go ahead. Analyze the impact of the new index using STATISTICS IO and Execution Plan. If the result feels alright and writes on those keys are seldom happening, you can try it.
Also, you can check sys.dm_db_index_usage_stats to define if your new index is efficient. If you see a lot of user_seeks, and the last_user_seek is not long ago, then your queries use that index more often. If user_updates are far more than seeks, scans, and lookups, you should drop that index.
5. Which is Better: Composite Index or Index with Included Columns?
Back when indexes with included columns did not exist, our only option was to include any other columns we needed in the composite index. This made the index key bigger. Included columns allowed us to have leaner index keys but still covers a variety of your queries on a table.
It also made it easier to understand their purpose. Columns in a composite index cover searches and lookups in your queries. The SELECT column list will be covered by the non-key, included columns. This will take away Key Lookups in the execution plan – refer to Figure 5 again. If the composite index has the NameStyle column as an included column, the execution plan will be simpler.
Let’s try to compare a composite index that covers everything in the query vs. a composite index with selected columns as keys and included columns. I hope that makes the question clearer.
Of course, you can still add columns that are not used for searches or lookups into the composite index. It will also take away the Key Lookup operators. But how does it compare with indexes with included columns?
Perform Tests Using Execution Plan and Logical Reads
Execution plans and logical reads allow us to fine-tune queries. For more information, check out my previous post. We will use these in our test to see which one is better.
TEST 1
We use the Person table again. In the existing name index, we add the NameStyle column under included columns. Then, create a new composite index for Lastname, Firstname, Middlename, and NameStyle. Name it IX_Name.
CREATE NONCLUSTERED INDEX [IX_Name] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC,
[NameStyle] ASC
)
Then, use the next listing to compare plans and logical reads.
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person WITH (INDEX (IX_Person_LastName_FirstName_MiddleName))
WHERE
LastName LIKE 's%'
ORDER BY NameStyle
SELECT
FirstName
,MiddleName
,LastName
,NameStyle
FROM Person.Person WITH (INDEX (IX_Name))
WHERE
LastName LIKE 's%'
ORDER BY NameStyle
The result set will be the same. However, each SELECT will force a different index using the WITH clause. The first SELECT will use the index with included columns. The next will use the new composite index without included columns. We used Lastname to make sure an index seek is used. What’s different is the ORDER BY with NameStyle.
And the result? The 2 queries had identical plans. Check out Figure 8 below:
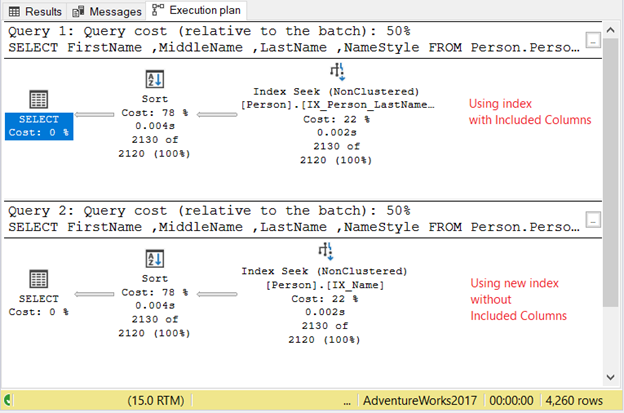
The logical reads are identical – 14 logical reads and the use of TempDB for sorting. Query time stats are the same.
Does it mean that the 2 indexes are identical like twins wearing different clothing? Let’s dig deeper. Now we use sys.dm_db_partition_stats for the 2 indexes:
SELECT
'Person' AS TableName
,i.index_id
,i.[name] AS IndexName
,ps.used_page_count
,ps.reserved_page_count
,ps.row_count
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id
WHERE ps.object_id = OBJECT_ID(N'Person.Person')
AND i.index_id <> 1
The result is in Figure 9 below:

Based on Figure 9, a leaner index key with included columns will consume fewer pages. Hence, they are not identical. Somehow, using a different variation of the query reveals more of its differences.
TEST 2
Let’s try a different table with more than 36 million records. You need a script to create the table, and here it is:
SET NOCOUNT ON;
DROP TABLE Sales.SalesOrderHeader2
GO
PRINT 'Creating test table...'
CREATE TABLE [Sales].[SalesOrderHeader2](
[SalesOrderID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[RevisionNumber] [tinyint] NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DueDate] [datetime] NOT NULL,
[ShipDate] [datetime] NULL,
[Status] [tinyint] NOT NULL,
[OnlineOrderFlag] [dbo].[Flag] NOT NULL,
[SalesOrderNumber] AS (isnull(N'SO'+CONVERT([nvarchar](23),[SalesOrderID]),N'*** ERROR ***')),
[PurchaseOrderNumber] [dbo].[OrderNumber] NULL,
[AccountNumber] [dbo].[AccountNumber] NULL,
[CustomerID] [int] NOT NULL,
[SalesPersonID] [int] NULL,
[TerritoryID] [int] NULL,
[BillToAddressID] [int] NOT NULL,
[ShipToAddressID] [int] NOT NULL,
[ShipMethodID] [int] NOT NULL,
[CreditCardID] [int] NULL,
[CreditCardApprovalCode] [varchar](15) NULL,
[CurrencyRateID] [int] NULL,
[SubTotal] [money] NOT NULL,
[TaxAmt] [money] NOT NULL,
[Freight] [money] NOT NULL,
[TotalDue] AS (isnull(([SubTotal]+[TaxAmt])+[Freight],(0))),
[Comment] [nvarchar](128) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_SalesOrderHeader2_SalesOrderID] PRIMARY KEY CLUSTERED
(
[SalesOrderID] ASC
)
GO
PRINT 'Generating test data...'
DECLARE @Loops SMALLINT = 0;
WHILE @Loops < 5000
BEGIN
INSERT INTO Sales.SalesOrderHeader2
(RevisionNumber
,OrderDate
,DueDate
,ShipDate
,Status
,OnlineOrderFlag
,PurchaseOrderNumber
,AccountNumber
,CustomerID
,SalesPersonID
,TerritoryID
,BillToAddressID
,ShipToAddressID
,ShipMethodID
,CreditCardID
,CreditCardApprovalCode
,CurrencyRateID
,SubTotal
,TaxAmt
,Freight
,Comment
,rowguid
,ModifiedDate)
SELECT
RevisionNumber
,DATEADD(YY, 5, OrderDate)
,DATEADD(YY, 5, DueDate)
,DATEADD(YY, 5, ShipDate)
,Status
,OnlineOrderFlag
,PurchaseOrderNumber
,AccountNumber
,CustomerID
,SalesPersonID
,TerritoryID
,BillToAddressID
,ShipToAddressID
,ShipMethodID
,CreditCardID
,CreditCardApprovalCode
,CurrencyRateID
,SubTotal
,TaxAmt
,Freight
,Comment
,rowguid
,DATEADD(YY, 5, ModifiedDate)
FROM Sales.SalesOrderHeader
WHERE OrderDate BETWEEN '2011-07-01' AND '2012-07-31';
CHECKPOINT;
INSERT INTO Sales.SalesOrderHeader2
(RevisionNumber
,OrderDate
,DueDate
,ShipDate
,Status
,OnlineOrderFlag
,PurchaseOrderNumber
,AccountNumber
,CustomerID
,SalesPersonID
,TerritoryID
,BillToAddressID
,ShipToAddressID
,ShipMethodID
,CreditCardID
,CreditCardApprovalCode
,CurrencyRateID
,SubTotal
,TaxAmt
,Freight
,Comment
,rowguid
,ModifiedDate)
SELECT
RevisionNumber
,DATEADD(YY, 6, OrderDate)
,DATEADD(YY, 6, DueDate)
,DATEADD(YY, 6, ShipDate)
,Status
,OnlineOrderFlag
,PurchaseOrderNumber
,AccountNumber
,CustomerID
,SalesPersonID
,TerritoryID
,BillToAddressID
,ShipToAddressID
,ShipMethodID
,CreditCardID
,CreditCardApprovalCode
,CurrencyRateID
,SubTotal
,TaxAmt
,Freight
,Comment
,rowguid
,DATEADD(YY, 6, ModifiedDate)
FROM Sales.SalesOrderHeader
WHERE OrderDate BETWEEN '2011-07-01' AND '2012-07-31';
CHECKPOINT;
SET @Loops = @Loops + 1;
END
PRINT 'Creating a non-clustered composite index with included columns...'
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader2_CustomerID_OrderDate_With_Included]
ON [Sales].[SalesOrderHeader2] ([CustomerID],[OrderDate])
INCLUDE ([ShipDate],[SalesPersonID],[SubTotal])
GO
PRINT 'Creating non-clustered composite index without included columns...'
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader2_CustomerID_OrderDate]
ON [Sales].[SalesOrderHeader2] ([CustomerID],[OrderDate],[ShipDate],[SalesPersonID],[SubTotal])
GO
Now, press Ctrl-M or click Include Actual Execution Plan and run the queries below. Again, we will force the use of the 2 indexes to see the differences.
SET STATISTICS IO ON
SELECT
CustomerID
,SalesPersonID
,SalesOrderID
,OrderDate
,ShipDate
,SubTotal
FROM Sales.SalesOrderHeader2 WITH (INDEX(IX_SalesOrderHeader2_CustomerID_OrderDate_With_Included))
WHERE (CustomerID BETWEEN 20900 AND 20999)
AND (OrderDate BETWEEN '01/01/2017' AND '10/31/2018')
AND SubTotal > 1000
ORDER BY CustomerID, OrderDate, ShipDate
SELECT
CustomerID
,SalesPersonID
,SalesOrderID
,OrderDate
,ShipDate
,SubTotal
FROM [Sales].[SalesOrderHeader2] WITH (INDEX(IX_SalesOrderHeader2_CustomerID_OrderDate))
WHERE (CustomerID BETWEEN 20900 AND 20999)
AND (OrderDate BETWEEN '01/01/2017' AND '10/31/2018')
AND SubTotal > 1000
ORDER BY CustomerID, OrderDate, ShipDate
SET STATISTICS IO OFF
EXECUTION PLAN
This time, the execution plans are different. Take a look at Figure 10.
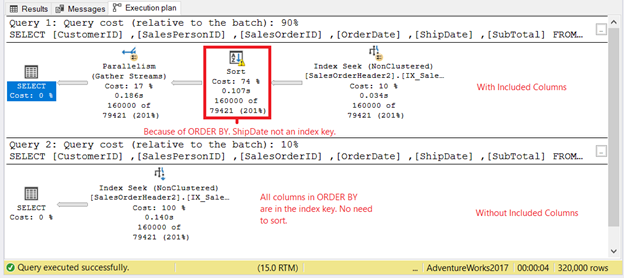
We see notable operators that appeared in the first execution plan in Figure 10.
First, the Sort operator. It has the highest operator cost of all because there’s an ORDER BY of 3 columns: CustomerID, OrderDate, and ShipDate. While CustomerID and OrderDate are parts of the index key, ShipDate is not. Thus, SQL Server needs to sort the output. Also, we see a warning icon. If you hover your mouse to that operator, you will see the warning message: Operator used tempdb to spill data during execution with spill level 1 and 3 spilled thread(s), Sort wrote 533 pages to and read 533 pages from tempdb with granted memory 8328KB and used memory 8328KB. In short, this plan is more expensive. The second SELECT, on the other hand, has all the columns in ORDER BY as part of the index key. Sorting is not required.
Second, the Parallelism operator. The first SELECT forces SQL Server to utilize all 4 processors that my machine has. It’s not that bad. It only tells that the query optimizer needs these 4 processors, or the execution time will be longer.
If you want to take away the Sort and Parallelism operators, you can include the ShipDate column as part of the composite index key.
LOGICAL READS
STATISTICS IO also supports the execution plan by having different logical reads. I used statisticsparser.com to format the logical reads nicely. See Figure 11.
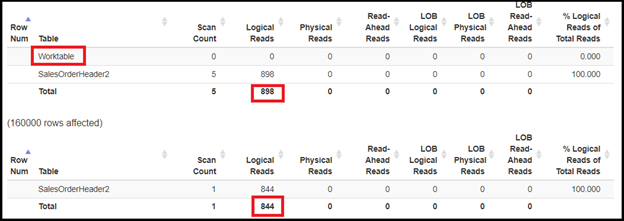
The first SELECT used 898 logical reads with WorkTable. This supports the execution plan’s Sort operator in Figure 10. The second SELECT is not too far behind with 844 logical reads.
When we include the ShipDate column as part of the first composite index, it reduces logical reads. Even better, it results in slightly fewer logical: 842 logical reads for the first SELECT and 844 logical reads for the second SELECT.
This does not say that the first composite index is inferior. It only states that the first composite index needs the ShipDate column as part of the index key.
PAGE INFORMATION
Curious about how many pages each index uses in the database? Let’s run a similar query using sys.dm_db_partition_stats on the 2 indexes:
SELECT
'SalesOrderHeader2' AS TableName
,i.index_id
,i.[name] AS IndexName
,ps.used_page_count
,ps.reserved_page_count
,ps.row_count
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id
WHERE ps.object_id = OBJECT_ID(N'Sales.SalesOrderHeader2')
AND i.index_id <> 1
The result is in Figure 12 below:

The composite index with included columns used fewer pages. This means less disk space and memory.
KEY LESSON
Which is better: SQL composite index or index with included columns?
SQL composite indexes with included columns used fewer pages in our test. But query plans and logical reads are either the same or slightly different. In our second test, performance improves if we modify the index key. You will never know until you test. Since we didn’t cover other scenarios, this is the best answer. Then, the one that consumes less logical reads and has a simpler plan will be the best option.
Takeaways
The answers to the 5 questions can only be useful if you apply them in your experiments and projects. I hope this has helped you in some way to improve your goals on quick running queries. With practice, this can become second nature to you.
Let’s recap.
- An SQL composite index is an index with an index key of more than 1 column.
- It is good for covering searches and lookups like WHERE clause and joins.
- You can create composite indexes using CREATE INDEX or ALTER TABLE.
- An SQL GUI tool can also be used.
- When creating one, think of what column is mostly used in the query and make it the first column in the key.
- Finally, if you need to cover other columns other than for searches and lookups, use included columns.
Like this post? Then please share it on your favorite social media platforms.
Boost your database performance and optimize queries by exploring these insightful articles on SQL indexing techniques, unlocking their full potential for your projects:
- 3 Methods to Rebuild All Indexes for All Tables with T-SQL in SQL Server Database
- SQL Server: Renaming Indexes using the sp_rename Procedure
- SQL Server Indexes Management Using Index Manager for SQL Server
- Stored Procedure to Get Indexes Status in All Databases
- SQL Server Resumable Index: Is it good for you?
- Easy Answers to 5 Vital Questions about Composite Index in SQL
- Clustered and Non Clustered Index: 7 Top Points Explained
- Hash What? Understanding Hash Indexes




