
Sometimes during our run as DBAs, we come up across at least one table that is loaded with duplicate records. Even if the table has a Primary Key (an auto-incremental one in most cases), the rest of the fields might have duplicate values.
However, SQL Server allows for many ways to get rid of those duplicate records (e.g. using CTEs, SQL Rank function, subqueries with Group By, etc.).
I remember once, during an interview, I was asked how to delete duplicate records in a table while leaving just 1 of each. At that time, I wasn’t able to answer, but I was very curious. After researching a bit, I found plenty of options to resolve this problem.
Now, years later, I’m here to present you a Stored Procedure that aims to answer the question “how to delete duplicate records in SQL table?”. Any DBA can simply use it to do some housekeeping without worrying too much.
Create Stored Procedure: Initial Considerations
The account you use must have enough privileges to create a Stored Procedure in the intended database.
The account executing this Stored Procedure must have enough privileges to perform the SELECT and DELETE operations against the target database table.
This Stored Procedure is intended for the database tables that don’t have a Primary Key (nor a UNIQUE constraint) defined. However, if your table has a Primary Key, the Stored Procedure will not take those fields into account. It will perform the lookup and deletion based on the rest of the fields (so use it very carefully in this case).
How to Use Stored Procedure in SQL
Copy & paste the SP T-SQL Code available within this article. The SP expects 3 parameters:
@schemaName – the name of the database table schema if applies. If not – use dbo.
@tableName – the name of the database table where the duplicate values are stored.
@displayOnly – if set to 1, the actual duplicate records will not be deleted, but only displayed instead (if any). By default, this value is set to 0 meaning that the actual deletion will happen if duplicates exist.
SQL Server Stored Procedure Execution Tests
To demonstrate the Stored Procedure, I have created two different tables – one without a Primary Key, and one with a Primary Key. I have inserted some dummy records into these tables. Let’s check what results I get before/after executing the Stored Procedure.
SQL Table with Primary Key
CREATE TABLE [dbo].[test](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL,
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED
(
[column1] ASC,
[column2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
SQL Stored Procedure Example Records
INSERT INTO test VALUES('A','A',1),('A','B',1),('A','C',1),('B','A',2),('B','B',3),('B','C',4)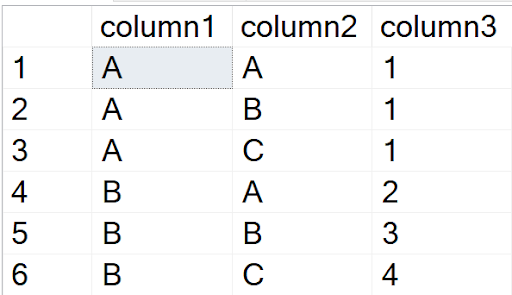
Execute Stored Procedure with Display Only
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 1
Since column1 and column2 form the Primary Key, the duplicates are evaluated against the non-Primary Key columns, in this case, column3. The result is correct.
Execute Stored Procedure without Display Only
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 0
The duplicate records are gone.
However, you must be careful with this approach because the first occurrence of the record is the one that will cut. So, if for any reason you need a very specific record to be deleted, then you must tackle your particular case separately.
SQL Table with no Primary Key
CREATE TABLE [dbo].[duplicates](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL
) ON [PRIMARY]
GO
SQL Stored Procedure Example Records
INSERT INTO duplicates VALUES
('John','Smith','Y'),
('John','Smith','Y'),
('John','Smith','N'),
('Peter','Parker','N'),
('Bruce','Wayne','Y'),
('Steve','Rogers','Y'),
('Steve','Rogers','Y'),
('Tony','Stark','N')
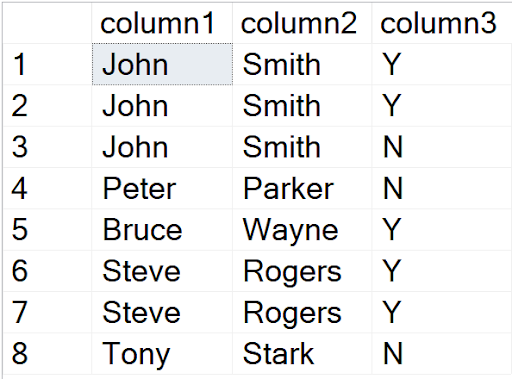
Execute Stored Procedure with Display Only
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 1
The output is correct, those are the duplicate records in the table.
Execute Stored Procedure without Display Only
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 0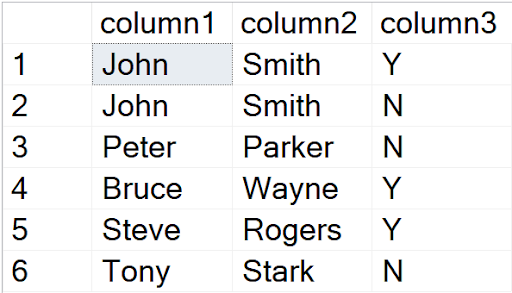
The Stored Procedure has worked as expected and the duplicates are successfully cleaned.
Special Cases for this Stored Procedure in SQL
If the schema or table you are specifying doesn’t exist within your database, the Stored Procedure will notify you, and the script will end its execution.

If you leave the schema name blank, the script will notify you and end its execution.

If you leave the table name blank, the script will notify you and end its execution.

If you execute the Stored Procedure against a table that doesn’t have any duplicates and activate the @displayOnly bit, you will get an empty result set.
SQL Server Stored Procedure: Complete Code
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author : Alejandro Cobar
-- Create date: 2021-06-01
-- Description: SP to delete duplicate rows in a table
-- =============================================
CREATE PROCEDURE DBA_DeleteDuplicates
@schemaName VARCHAR(128),
@tableName VARCHAR(128),
@displayOnly BIT = 0
AS
BEGIN
SET NOCOUNT ON;
IF LEN(@schemaName) = 0
BEGIN
PRINT 'You must specify the schema of the table!'
RETURN
END
IF LEN(@tableName) = 0
BEGIN
PRINT 'You must specify the name of the table!'
RETURN
END
IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName)
BEGIN
DECLARE @pkColumnName VARCHAR(128);
DECLARE @columnName VARCHAR(128);
DECLARE @sqlCommand VARCHAR(MAX);
DECLARE @columnsList VARCHAR(MAX);
DECLARE @pkColumnsList VARCHAR(MAX);
DECLARE @pkColumns TABLE(pkColumn VARCHAR(128));
DECLARE @limit INT;
INSERT INTO @pkColumns
SELECT K.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS C
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS K ON C.TABLE_NAME = K.TABLE_NAME AND C.CONSTRAINT_SCHEMA = K.CONSTRAINT_SCHEMA
WHERE C.CONSTRAINT_TYPE = 'PRIMARY KEY'
AND C.CONSTRAINT_SCHEMA = @schemaName AND C.TABLE_NAME = @tableName
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
DECLARE pk_cursor CURSOR FOR
SELECT * FROM @pkColumns
OPEN pk_cursor
FETCH NEXT FROM pk_cursor INTO @pkColumnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @pkColumnsList = CONCAT(@pkColumnsList,'',@pkColumnName,',')
FETCH NEXT FROM pk_cursor INTO @pkColumnName
END
CLOSE pk_cursor
DEALLOCATE pk_cursor
SET @pkColumnsList = SUBSTRING(@pkColumnsList,1,LEN(@pkColumnsList)-1)
END
DECLARE columns_cursor CURSOR FOR
SELECT COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName AND COLUMN_NAME NOT IN (SELECT pkColumn FROM @pkColumns)
ORDER BY ORDINAL_POSITION;
OPEN columns_cursor
FETCH NEXT FROM columns_cursor INTO @columnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @columnsList = CONCAT(@columnsList,'',@columnName,',')
FETCH NEXT FROM columns_cursor INTO @columnName
END
CLOSE columns_cursor
DEALLOCATE columns_cursor
SET @columnsList = SUBSTRING(@columnsList,1,LEN(@columnsList)-1)
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
IF(CHARINDEX(',',@columnsList) = 0)
SET @limit = LEN(@columnsList)+1
ELSE
SET @limit = CHARINDEX(',',@columnsList)
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,@limit-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT ',@columnsList,',MAX(DuplicateCount) AS DuplicateCount FROM CTE WHERE DuplicateCount > 1 GROUP BY ',@columnsList)
END
ELSE
BEGIN
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,CHARINDEX(',',@columnsList)-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT * FROM CTE WHERE DuplicateCount > 1;')
END
EXEC (@sqlCommand)
END
ELSE
BEGIN
PRINT 'Table doesn't exist within this database!'
RETURN
END
END
GO
Conclusion
If you don’t know how to delete duplicate records in SQL table, than tools like this will be helpful for you. Any DBA can check if there are database tables that don’t have Primary Keys (nor Unique constraints) for them, that might accumulate a pile of unnecessary records over time (potentially wasting storage). Just plug and play the Stored Procedure, and you’re good to go.
You can go a bit further and build an alerting mechanism to notify you if there are duplicates for a specific table (after implementing a bit of automation using this tool of course), which comes quite handy.
As with anything related to DBA tasks, make sure to always test everything in a sandbox environment before pulling the trigger in production. And when you do, make sure to have a backup of the table you focus on.
Tags: sql server tables, stored procedure Last modified: November 07, 2022







