Let’s imagine you have a large raw file and need to determine the best way to load it into an Oracle Autonomous Data Warehouse instance to explore and visualize data. In this article you will find a few Oracle solutions that allow you to do that.
Below you can see a table that identifies use cases for them all.
| Oracle Tool / Solution | Use Case | Sizing of Data Set |
| Import Wizard in SQL Developer | Used when you want to migrate both the table schema and data stored. Not suitable for large tables. | |
| SQL Loader | Used to load data from local files to Autonomous Database. Suitable for small datasets. | < 100MB |
| Oracle Data Pump | Used when you want to migrate an entire Oracle DB to the Oracle Autonomous Database. It offers a very fast bulk data and metadata movement. | |
| DBMS_CLOUD package & Oracle Object Storage | Used for large files that need to be loaded. These files can be stored in different cloud vendors, such as Amazon S3, Azure Blob Storage, etc. | 100MB |
| Data Sync | Used for loading the data source other than Oracle (DB2, Microsoft SQL Server, MySQL, etc.). It also offers to load data stored from generic JDBC data sources, such as Greenplum, Hive, Impala, MongoDB, Redshift, etc. | |
| Oracle Golden Gate | The solution is similar to Data Sync, but it offers real-time replication of data and migration without impacting the performance of data sources. |
Background
Oracle Cloud Object Storage is an internet-scale, high-performance storage service platform. It allows storing an unlimited amount of unstructured data of any type, such as videos, images, audio, etc. You can imagine the Object Storage service as an SFTP server in the cloud where you can store and retrieve the data safely and securely from the Internet or within the cloud platform.
The PL/SQL DBMS_CLOUD package supports the data loading from different formats, such as TEXT, ORC, Parquet, and Avro, and the below cloud services:
- Oracle Cloud Infrastructure Object Storage
- Azure Blob Storage
- Amazon S3
- Amazon S3-Compatible, including Google Cloud Storage and Wasabi Hot Cloud Storage
Implementation

Create Bucket in Object Storage
Log in to OCI and navigate to Object Storage > Object Storage (top-left hamburger icon).
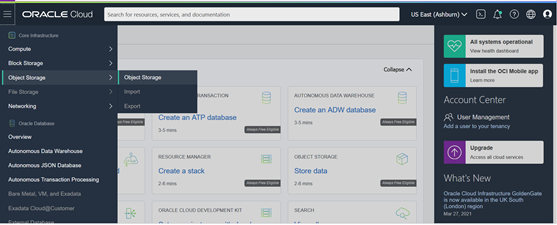
Choose the DEMO Compartment from the drop-down menu. If you don’t have any compartment, except for the root compartment, you need to create a new one at Identify > Compartments menu.
Click on Create Bucket:
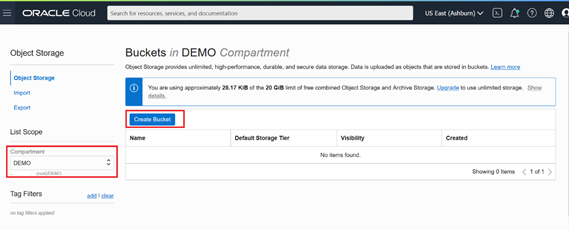
- Bucket name: BK_DEMO
- Default Storage Tier: Standard (this option is used when you want to access your data frequently. Otherwise, you can choose Archive as the long-term backup of your data).
- Encryption: Encrypt using Oracle managed keys. This option is used when you want Oracle to create encryption keys and manage them for you. In case, you own your keys you can use the second option.
The BK_DEMO is created successfully.
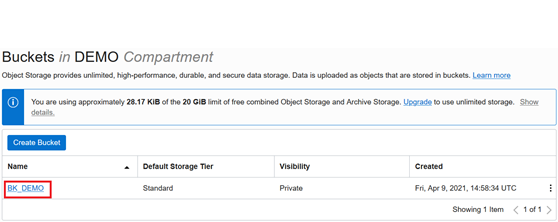
Create an Object Store Auth Token
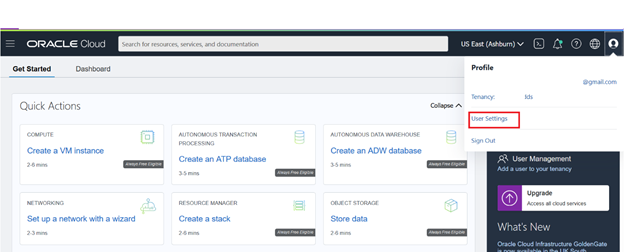
The purpose of this step is to create an Auth Token for your object storage account. Then you can use this token to create the communication tunnel between the Oracle Autonomous Data Warehouse and Object Storage service.
Log in to OCI and hover the mouse cursor over the profile icon in the top-right corner. Select User Settings.
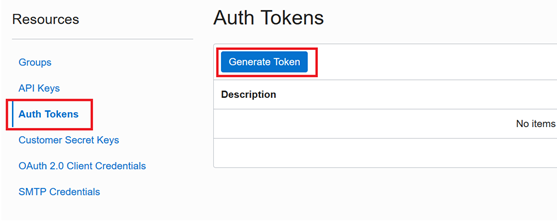
Under Resource, select Auth Tokens. Enter Description and click Generate Token.
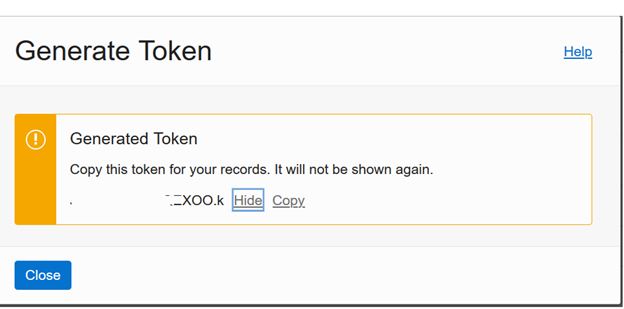
The system generates a token string which you should copy and paste into the text editor, such as Notepad. You will use it to set up the credentials in the next step.
Create Credentials in ADW Schema
After creating the Object Store Auth Token, we need to create the credentials for the object storage in ADW. ADW must be authorized for accessing Object Storage and reading the data for loading.
Open SQL Developer and connect to the ADW instance with your ADW database user (in this tutorial, we have the DEMO user).
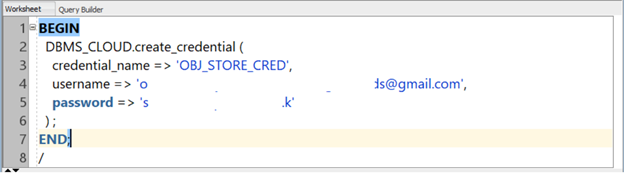
Open SQL Worksheet and enter the following query into the command line:
begin
DBMS_CLOUD.create_credential (
credential_name => 'OBJ_STORE_CRED',
username => '<your username>',
password => '<your Auth Token>'
) ;
end;
/
<your username> is your cloud account. You can get this information from the profile icon on the top-right:
<your Auth Token> is the token string generated in step #2.
Upload File to Object Storage
Log in to OCI and navigate to Object Storage > Click on BK_DEMO bucket. Under Resources, choose Objects, and click on Upload:
We are using the sample file of the LOAN customer. It is approximately 420MB in size, with 800,000 rows.
Load the Data into ADW
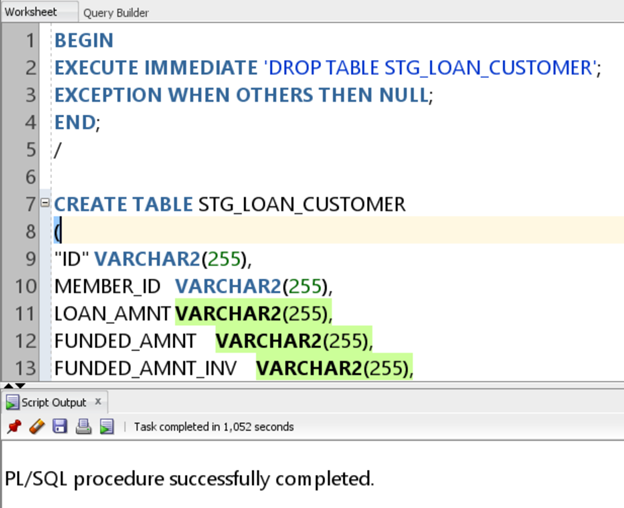
Now we need to load the LOAN customer data from the LOAN raw file uploaded. First, create a staging table in the DEMO database user:
BEGIN
EXECUTE IMMEDIATE 'DROP TABLE STG_LOAN_CUSTOMER';
EXCEPTION WHEN OTHERS THEN NULL;
END;
/
CREATE TABLE STG_LOAN_CUSTOMER
(
"ID" VARCHAR2(255),
MEMBER_ID VARCHAR2(255),
LOAN_AMNT VARCHAR2(255),
FUNDED_AMNT VARCHAR2(255),
FUNDED_AMNT_INV VARCHAR2(255),
"TERM" VARCHAR2(255),
INT_RATE VARCHAR2(255),
INSTALLMENT VARCHAR2(255),
GRADE VARCHAR2(255),
SUB_GRADE VARCHAR2(255),
EMP_TITLE VARCHAR2(255),
EMP_LENGTH VARCHAR2(255),
HOME_OWNERSHIP VARCHAR2(255),
ANNUAL_INC VARCHAR2(255),
VERIFICATION_STATUS VARCHAR2(255),
ISSUE_D VARCHAR2(255),
LOAN_STATUS VARCHAR2(255),
PYMNT_PLAN VARCHAR2(255),
"URL" VARCHAR2(255),
"DESC" VARCHAR2(4000),
PURPOSE VARCHAR2(255),
TITLE VARCHAR2(255),
ZIP_CODE VARCHAR2(255),
ADDR_STATE VARCHAR2(255),
DTI VARCHAR2(255),
DELINQ_2YRS VARCHAR2(255),
EARLIEST_CR_LINE VARCHAR2(255),
INQ_LAST_6MTHS VARCHAR2(255),
MTHS_SINCE_LAST_DELINQ VARCHAR2(255),
MTHS_SINCE_LAST_RECORD VARCHAR2(255),
OPEN_ACC VARCHAR2(255),
PUB_REC VARCHAR2(255),
REVOL_BAL VARCHAR2(255),
REVOL_UTIL VARCHAR2(255),
TOTAL_ACC VARCHAR2(255),
INITIAL_LIST_STATUS VARCHAR2(255),
OUT_PRNCP VARCHAR2(255),
OUT_PRNCP_INV VARCHAR2(255),
TOTAL_PYMNT VARCHAR2(255),
TOTAL_PYMNT_INV VARCHAR2(255),
TOTAL_REC_PRNCP VARCHAR2(255),
TOTAL_REC_INT VARCHAR2(255),
TOTAL_REC_LATE_FEE VARCHAR2(255),
RECOVERIES VARCHAR2(255),
COLLECTION_RECOVERY_FEE VARCHAR2(255),
LAST_PYMNT_D VARCHAR2(255),
LAST_PYMNT_AMNT VARCHAR2(255),
NEXT_PYMNT_D VARCHAR2(255),
LAST_CREDIT_PULL_D VARCHAR2(255),
COLLECTIONS_12_MTHS_EX_MED VARCHAR2(255),
MTHS_SINCE_LAST_MAJOR_DEROG VARCHAR2(255),
POLICY_CODE VARCHAR2(255),
APPLICATION_TYPE VARCHAR2(255),
ANNUAL_INC_JOINT VARCHAR2(255),
DTI_JOINT VARCHAR2(255),
VERIFICATION_STATUS_JOINT VARCHAR2(255),
ACC_NOW_DELINQ VARCHAR2(255),
TOT_COLL_AMT VARCHAR2(255),
TOT_CUR_BAL VARCHAR2(255),
OPEN_ACC_6M VARCHAR2(255),
OPEN_IL_6M VARCHAR2(255),
OPEN_IL_12M VARCHAR2(255),
OPEN_IL_24M VARCHAR2(255),
MTHS_SINCE_RCNT_IL VARCHAR2(255),
TOTAL_BAL_IL VARCHAR2(255),
IL_UTIL VARCHAR2(255),
OPEN_RV_12M VARCHAR2(255),
OPEN_RV_24M VARCHAR2(255),
MAX_BAL_BC VARCHAR2(255),
ALL_UTIL VARCHAR2(255),
TOTAL_REV_HI_LIM VARCHAR2(255),
INQ_FI VARCHAR2(255),
TOTAL_CU_TL VARCHAR2(255),
INQ_LAST_12M VARCHAR2(255)
);
/
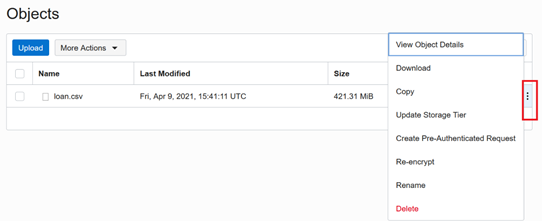
Get the URL path of the LOAN raw file in the Object Storage Bucket. Under Object, сlick on the three-dots icon and select View Objects Details.
Copy the URL Path (URI)
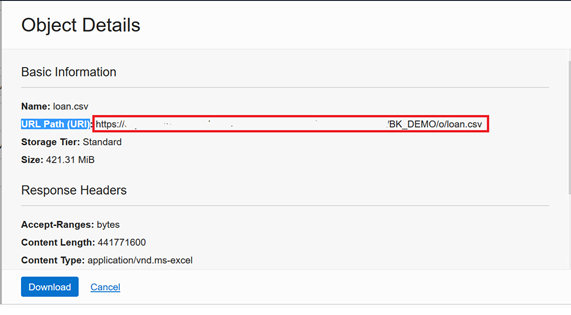
Use the COPY_DATE procedure of the DBMS_CLOUD package to load data from the LOAN raw file to the staging table:
BEGIN
EXECUTE IMMEDIATE 'TRUNCATE TABLE STG_LOAN_CUSTOMER';
END;
/
BEGIN
DBMS_CLOUD.COPY_DATA(
table_name => 'STG_LOAN_CUSTOMER',
credential_name => 'OBJ_STORE_CRED',
file_uri_list => URL path of Loan file in Bucket',
format => json_object('type' value 'csv',
'delimiter' value ',',
'ignoremissingcolumns' value 'true',
'skipheaders' value '1',
'trimspaces' value 'lrtrim',
'truncatecol' value 'true')
);
END;
BEGIN
EXECUTE IMMEDIATE 'TRUNCATE TABLE STG_LOAN_CUSTOMER';
END;
/
BEGIN
DBMS_CLOUD.COPY_DATA(
table_name => 'STG_LOAN_CUSTOMER',
credential_name => 'OBJ_STORE_CRED',
file_uri_list => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/xxxxxxxxxxxx/b/BK_DEMO/o/loan.csv',
format => json_object('type' value 'csv',
'delimiter' value ',',
'skipheaders' value '1',
'trimspaces' value 'lrtrim',
'truncatecol' value 'true')
);
END;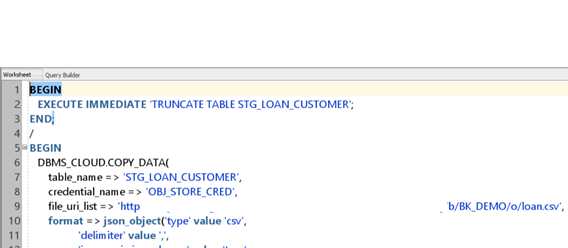
- table_name: name of the table needed to import the data
- crediential_name: name of your object storage credentials created in step #3
- file_uri_list: path to the LOAN file in the Object Storage bucket
- format:
- type: specify the CSV type of the LOAN file
- delimiter: comma
- skipheaders: true to ignore the header row while loading
- trimspaces: true to remove leading space and trailing spaces of fields
- truncatecol: true to truncate the value length to meet the data length in the staging table. E.g., if you define 100 characters for the ID column in the staging table, the ID column length in the raw file that is greater than 100 characters will be truncated to 100 characters.
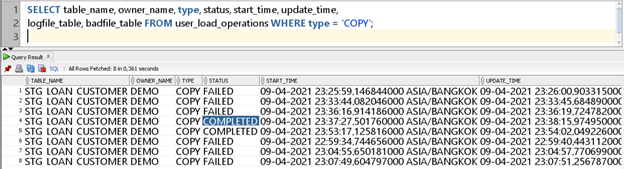
Verify the data loaded into the staging table and compare the row count to the raw file. Use the following dba_load_operations and user_load_operations tables to verify the process. All load operations done by PL/SQL package DBMS_CLOUD are logged in these tables.
SELECT table_name, owner_name, type, status, start_time, update_time,
logfile_table, badfile_table FROM user_load_operations WHERE type = 'COPY';
Benchmark Performance
The process took around 45 seconds to load 420MB of 800,000 rows of the LOAN data. However, it takes more than 5 minutes if we use the Import Wizard of SQL Developer.
Conclusion
Oracle offers many methods to support loading data into ADW. Among them, it’s worth noticing Import Wizard of SQL Developer, SQL*Loader, Data Pump, DBMS_CLOUD package & Oracle Storage solutions, Data Sync, and Oracle Golden Gate.
Depending on your situation, you should choose the appropriate method that helps you load the data easily and effectively. With the DBMS_CLOUD package and Object Storage, this method offers you several use-cases, such as working with large raw files/datasets, working with different Oracle Cloud Storage services or storage infrastructure, such as AWS or Amazon S3, and Apart of Big Data project.
Related Articles
- Provisioning an Oracle Autonomous Database
- Database Security in Oracle
- Conditional Split Transformation: Export Data from SQL Server into Oracle and MySQL Databases