
SQL Server Always ON Availability Group is a solution meant to achieve high availability and disaster recovery for SQL Server databases. We can configure this functionality between the Windows-based SQL Server installations, Linux-based SQL Server installations, and even between Linux and Windows-based SQL Server installations together.
Availability Groups are tightly integrated with cluster technologies in a form of automatic failover and data protection by replicating data to their respective secondary replicas. However, it is not always mandatory to have a cluster resource manager to configure availability groups.
To configure SQL Server availability groups, we need WSFC – Windows Server Failover Cluster technology for Windows-based SQL Server installations and PACEMAKER for Linux-based SQL Server installations.
PACEMAKER is an open-source cluster resource manager that we can use to manage resources and ensure system availability, should any failure on Linux systems takes place.
WSFC is a Microsoft product developed to support Windows-based cluster requirements.
When you look at the configured Availability Groups within SQL Server for both types of OS, it seems similar in SQL Server Management Studio.
However, this article explains Availability Groups between the Ubuntu Linux-based SQL Server installations using the PACEMAKER cluster technology so I will consider this configuration only.
Cluster Type Configuration
As I have stated above, we have three variants for configuring Availability Groups for SQL Server, depending on the OS:
- between Windows-based SQL Server installations;
- between Linux-based SQL Server installations;
- between the mixed type of Windows and Linux-based SQL Server installations.
Microsoft has introduced the Cluster_type configuration setting to identify and configure an appropriate cluster technology for Availability Groups. It is a configuration item that defines which type of cluster technology we use for Availability Groups, no matter which OS the SQL Server instance is based on.
You can fetch and validate the existing configuration of the Cluster type using SQL Server dynamic management view (DMV) sys.availability_groups. There are two columns named cluster_type and cluster_type_desc. We can read these columns to define the cluster type configuration of the Availability Group setup.
This configuration setting has 3 values to fulfill the cluster technology requirements for each variant:
WSFC.You must use the WSFC (Windows server failover cluster) option if you have Windows-based SQL Server installations. It is not supported for Linux-based SQL Server installations.
EXTERNAL. If you are configuring Availability Groups between Linux-based SQL Server installations, you must use the PACEMAKER cluster manager and choose the EXTERNAL cluster type. The failover mode must also be EXTERNAL (in WSFC it will be Automatic).
NONE. If you don’t want to use any clustering technology for your Availability Groups, select NONE. This option is applicable if you want to configure Availability Groups between Linux and Windows-based SQL Server instances. Even if you have configured clustering for your system, once you set the cluster type value to NONE, the Availability Groups will not use the cluster technology. The failover mode for the cluster type NONE is always Manual.
A New Setting: Required Synchronized Secondaries to Commit
Starting with SQL Server 2017, Microsoft has introduced a new setting called required_synchronized_secondaries_to_commit. It enables the automatic failover option if you have configured the cluster type as EXTERNAL for the PACEMAKER cluster configuration.
This setting’s value is set by default when you configure the SQL Server resource agent mssql-server-ha and create the cluster configuration.
Also, you can manually modify the value for your requirements by running the below command:
--Run below commands to change value for setting required_synchronized_secondaries_to_commit
--AGResourceName is the name of the resource configured for the Availability group
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
Note: We can change the above setting only via Pacemaker on Linux. It is impossible to modify it using the T-SQL statement for Linux-based deployments. However, for Windows-based deployments, we can change this setting by a T-SQL statement.
Below are the possible values for required_synchronized_secondaries_to_commit
0 – It means that secondary replicas do not need to be synchronized with the respective primary replica. Thus, it does not support the Automatic failover. You need to initiate the failover manually if the primary replica goes down. Important: there is a chance of data loss when you choose this value for configuration.
1 – It means that at least one secondary replica must be in the synchronized state to achieve automatic failover.
2 – It means that both secondary replicas must be synchronized with the primary replica. The automatic failover is supported.
Replicas to Participate in an Availability Group
The number of replicas that can participate in an Availability Group depends on the installed SQL Server edition.
- The SQL Server Standard edition supports only two-node replica for an Availability Group along with the additional configuration-only replica.
- The SQL Server Enterprise edition supports up to nine replicas – one primary and eight secondary replicas.
As the SQL Server Standard Edition supports only two replicas (one primary replica and one secondary replica), Microsoft has introduced a new concept called configuration-only replica in SQL Server 2017 CU1 to achieve automatic failover for SQL Servers running on Linux systems.
There are two possible design options:
- Three synchronous replicas. This configuration can be deployed with the SQL Server Enterprise edition only. There will be 3 copies of your availability databases. This architecture allows for all 3 functionalities read-scale, high availability, and data protection.
- Two synchronous replicas and a configuration-only replica. You can configure this design with the help of the SQL Server Standard edition as well, running two synchronous replicas on the SQL Server Standard edition and the 3rd replica on the SQL Server Express edition which acts as the configuration-only replica. It is a cost-effective design that supports high availability with automatic failover and database protection.
Two-node Replica
The two-node replica configurations for Availability Groups is a very popular deployment option for ensuring the high availability of SQL Server databases. We achieve the automatic failover with the help of the Windows Server Failover Cluster technology and a file share witness in Windows-based SQL Server deployments.
The file share is generally used on an additional node in WSFC to provide quorum configuration for two-node replica configurations. WSFC synchronizes all configuration metadata to both replicas and on the third node or file share witness for smooth failover. All failover arbitration for Windows-based SQL Server availability group happens at WSFC layer.
If we want to achieve the automatic failover for Linux-based SQL Server Availability Group deployments, the above configuration won’t work. It is because WSFC can only be used for Windows-based SQL Server installations.
To address this limitation and enable automatic failover for Linux-based two-replica deployments, Microsoft has introduced a new concept.
Configuration-only Replica
A configuration-only replica is an option where we install an additional instance of SQL Server on the third node. That node will work as a witness server for the two-node replica configuration to support automatic failover. We can create one configuration-only replica per Availability Group.
For Linux-based SQL Server Instances where we use cluster type as EXTERNAL for PACEMAKER, the failover arbitration does not work at cluster layer like WSFC. All failover arbitration happens at the SQL Server layer because all availability group configuration metadata is stored in the master databases of each replica.
Microsoft has introduced the configuration-only replica concept to handle quorum for Linux-based SQL Server Availability Groups. This concept does not host any user databases to participate in an availability group. It stores all Availability Group configuration information in the master database to ensure that all failover arbitration happens smoothly.
You can use any edition of SQL Server for the configuration-only replica. Even the SQL Server Express edition will suit to save your license cost for the third replica. Remember, the configuration-only replica will not host any database within the availability group. Thus, you will have only two copies of databases in an availability group.
By default, required_synchronized_secondaries_to_commit is set to 0 when we use the configuration-only replica. We can manually modify this value to 1 if needed.
Have a look at the design diagram of the two-node synchronous replica and a configuration-only replica to achieve automatic failover and data protection.
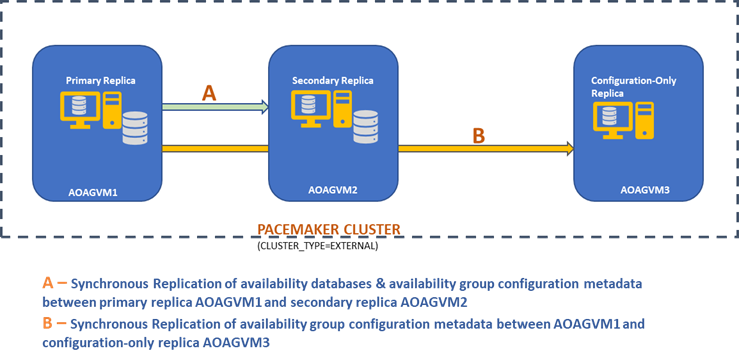
We can see there are 3 VMs named AOAGVM1, AOAGVM2 & AOAGVM3. They all are running by the Ubuntu Linux system, and SQL Server is configured on all three Linux systems. The availability databases are hosted on AOAGVM1 and AOAGVM2.
AOAGVM1 is acting as a primary replica, whereas AOAGVM2 is a secondary replica. AOAGVM3 serves as the configuration-only replica, which is the SQL Server Express edition. No user databases are hosted on this third replica.
The Pacemaker cluster has been configured between all three nodes to support the cluster technology for Linux-based availability group configuration.
To configure or implement the above design, we need to perform the following steps:
- Install SQL Server on three Ubuntu systems (the SQL Server Express edition will suit for configure-only replica).
- Configure Availability Groups between three nodes.
- Configure the PACEMAKER Cluster between three nodes.
- Add or Integrate Availability Group as a resource in the cluster group.
Have a look at the related article to complete step 1 (installing SQL Server instances on three nodes).
Stay tuned for my next article where I’ll explain the step-by-step process to implement the above design. Our goal will be to achieve automatic failover and data protection using the 2-node synchronous replica and a configuration-only replica.
We’ll be glad to hear your thoughts and practical tips on this matter. Feel free to share them in the Comments section.
Tags: Always On, sql server availability groups Last modified: September 16, 2021





